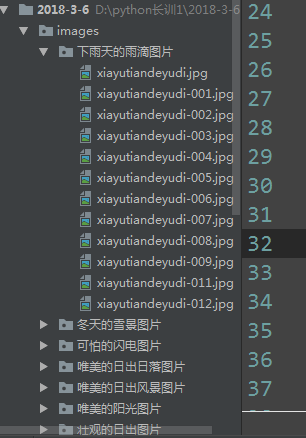
正則應用--爬取天堂圖片網圖片(普通版本,函式版本,類版本)
阿新 • • 發佈:2019-01-29
第一部分:普通版本
一.os包的用法
先引入import os
# 如果資料夾不存在,建立資料夾
if not os.path.exists(title):
# 建立資料夾
os.makedirs(title)發起請求,接收響應
response = request.urlopen(req)html = response.read().decode('utf-8')request.urlretrieve(src, title + '/' + name)
完整程式碼:
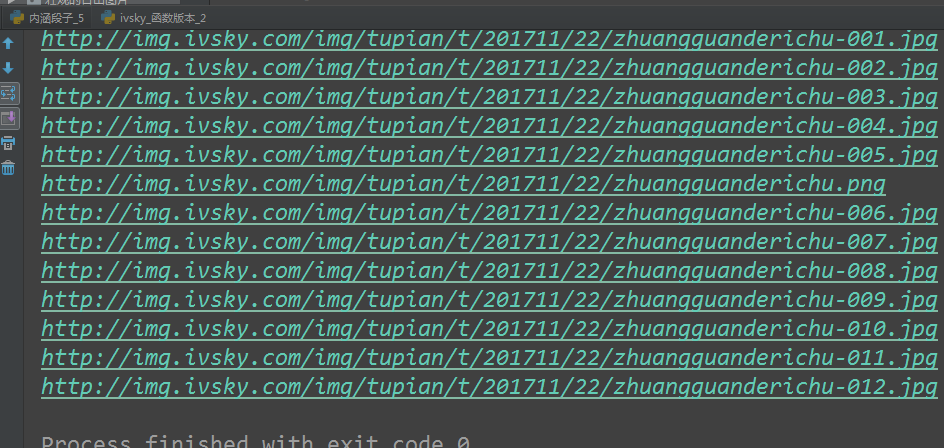
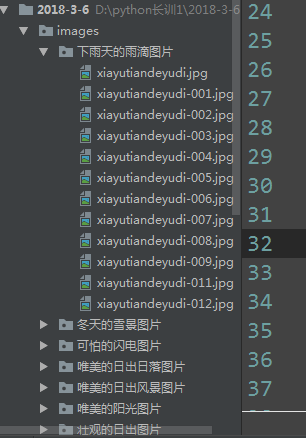
# -*- coding:utf-8 -*- # 網路請求包 from urllib import request, parse # 正則 import re import os # 準備url地址 url = 'http://www.ivsky.com/tupian/ziranfengguang/' # 構建請求物件 req = request.Request(url=url, headers={ 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:53.0) Gecko/20100101 Firefox/53.0' }) # 發起請求,接收響應 response = request.urlopen(req) # 將返回的位元組資料 轉換為str資料 html = response.read().decode('utf-8') # print(html) # 準備正則 pattern = re.compile('div class="il_img.*?<a href="(.*?)" title="(.*?)"') # findall()函式 查詢所有符合正則的資料 # 返回存放分組元組資訊的列表 res = re.findall(pattern, html) print(res) # for 迴圈遍歷列表,取出每一個圖片分類的連結及標題 for info in res: link = info[0] title = info[1] # 如果資料夾不存在,建立資料夾 if not os.path.exists(title): # 建立資料夾 os.makedirs(title) # 拼接完整的詳情連結 detail_url = 'http://www.ivsky.com' + link # 發起請求 response = request.urlopen(detail_url) # 將資料轉換為字串 detail_html = response.read().decode('utf-8') # 準備正則 det_pat = re.compile('<div class="il_img.*?<img src="(.*?)"') # findall() detail_res = re.findall(det_pat, detail_html) # print(detail_res) for src in detail_res: name = src.split('/')[-1] print('圖片名稱:{} 圖片連結:{}'.format(name, src)) # 直接根據連結,檔名稱,下載圖片 request.urlretrieve(src, title + '/' + name)
執行結果:

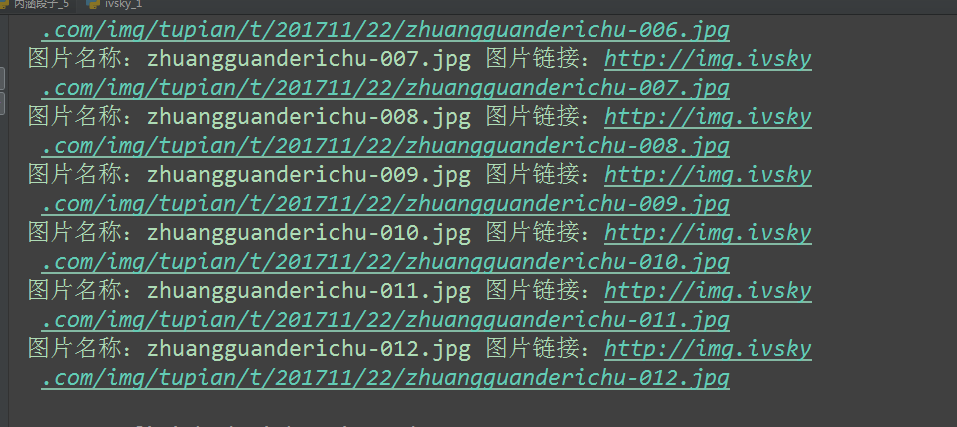
第二部分:函式版本
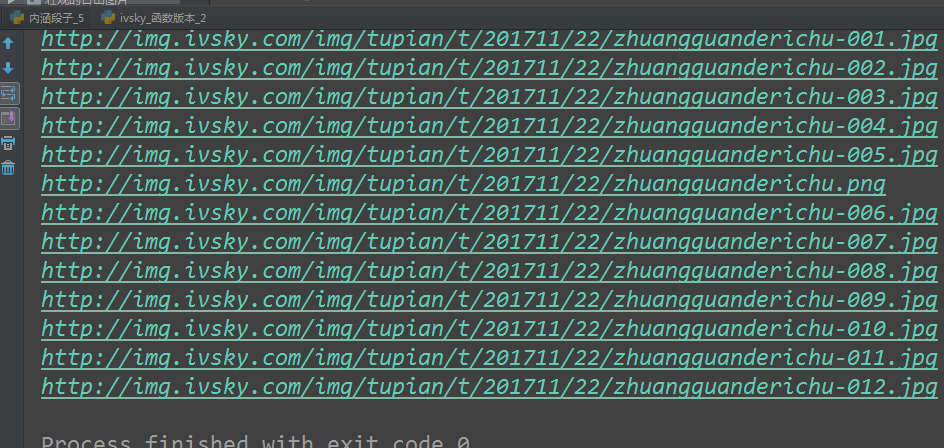
完整程式碼:# -*- coding:utf-8 -*- # 網路請求包 from urllib import request, parse # 正則 import re import os # 傳送請求接收響應資料 def get_html(url): """ 根據url地址傳送請求,接收響應資料,返回響應資料 :param url: 請求地址 :return: str型別的html原始碼 """ # 構建request物件 req = request.Request( url=url, headers={ 'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:53.0) Gecko/20100101 Firefox/53.0' } ) # 發起請求 接收響應 response = request.urlopen(req) # 轉換資料 html = response.read().decode('utf-8') # 返回html原始碼 return html # 根據正則提取詳情url和分類標題 def get_detail(html): """ 根據正則提取詳情url和分類標題 :param html: 網頁原始碼 :return: """ # 1.準備正則 pattern = re.compile('div class="il_img.*?<a href="(.*?)" title="(.*?)"') # 2.提取資料 res = re.findall(pattern, html) # for 迴圈遍歷 for info in res: link = info[0] title = info[1] path = 'images/' + title if not os.path.exists(path): os.makedirs(path) # 拼接詳情url地址 detail_url = "http://www.ivsky.com" + link # 執行獲取圖片src/下載圖片的函式 get_img_src(detail_url, path) # 根據正則提取圖片地址,下載圖片 def get_img_src(url, path): # 獲取詳情頁的html html = get_html(url) pattern = re.compile('<div class="il_img.*?<img src="(.*?)"') res = re.findall(pattern, html) # 分割圖片名稱 for src in res: print(src) name = src.split('/')[-1] # 下載圖片 request.urlretrieve(src, path + '/' + name) # 爬蟲的主函式 def main(): url = "http://www.ivsky.com/tupian/ziranfengguang/" html = get_html(url) get_detail(html) # 是否在當前檔案直接執行 if __name__ == '__main__': main()
執行結果:
第三部分:類版本
完整程式碼
# -*- coding:utf-8 -*-
# 網路請求包
from urllib import request, parse
# 正則
import re
import os
# 風景爬蟲類
class IvskySpider(object):
def __init__(self):
# 爬蟲的初始地址
self.url = "http://www.ivsky.com/tupian/ziranfengguang/"
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64; rv:53.0) Gecko/20100101 Firefox/53.0'
}
self.html = ''
def get_html(self):
# 構建請求物件
req = request.Request(self.url, headers=self.headers)
# 發起請求
response = request.urlopen(req)
# 轉換html
html = response.read().decode('utf-8')
# 給物件屬性賦值
self.html = html
# return html
# 解析詳情連結和title
def parse_detail(self):
# 1.準備正則
pattern = re.compile('div class="il_img.*?<a href="(.*?)" title="(.*?)"')
# 2.提取資料
res = re.findall(pattern, self.html)
# for 迴圈遍歷
for info in res:
link = info[0]
title = info[1]
path = 'images/' + title
if not os.path.exists(path):
# # 切換到images
# os.chdir('images/')
# os.makedirs(title)
os.makedirs(path)
# 拼接詳情url地址
detail_url = "http://www.ivsky.com" + link
# 賦值
self.url = detail_url
# 新增屬性
self.path = path
# 呼叫解析下載圖片函式
self.parse_src_download()
# 解析詳情頁面每張圖片的連結,並下載儲存
def parse_src_download(self):
# 獲取詳情頁面的html原始碼
self.get_html()
pattern = re.compile('<div class="il_img.*?<img src="(.*?)"')
res = re.findall(pattern, self.html)
# 分割圖片名稱
for src in res:
print(src)
name = src.split('/')[-1]
# 下載圖片
request.urlretrieve(src, self.path + '/' + name)
# 定義啟動爬蟲的函式
def start(self):
self.get_html()
self.parse_detail()
if __name__ == '__main__':
ivsky = IvskySpider()
ivsky.start()
執行結果: