
網際網路公司計算機網路熱門面試題整理
1.體系結構
OSI七層體系機構:物理層 資料鏈路層 網路層 運輸層 會話層 表示層 應用層
五層體系結構:物理層 資料鏈路層 網路層 傳輸層 應用層
資料傳輸的基本單位:傳輸層(TCP(報文段)UDP(使用者資料包))、網路層(IP資料報或分組)、資料鏈路層(幀)、物理層(位元)
2.HTTP協議相關
1)HTTP是不儲存狀態的協議:
HTTP是一種不儲存狀態的協議,即無狀態的協議。HTTP協議自身不對請求和響應之間的通訊狀態進行儲存。每當有新的請求,就會有對應的新響應產生。協議本身並不保留之前一切的請求或響應資訊,所以在購物網站中一般使用Cookie技術。
2)HTTP/1.0和HTTP/1.1的區別
HTTP/1.1預設支援長連線,而HTTP1.0需要使用keep-alive引數來告知伺服器建立長連線。
HTTP/1.0規定瀏覽器與伺服器只保持短暫的連線,瀏覽器每次都需要與伺服器建立一個TCP連線,伺服器完成請求後,立即斷開TCP連線,也就是說,同一個客戶第二次訪問同一個伺服器上的頁面時,伺服器的響應過程與第一次被訪問時是相同的。舉例在收到的HTML文件後,文件中有10個圖片,每個圖片都要重新再次建立連接獲取,所以網速較慢的時候,我們有時會看到先出現網頁,每個圖片再逐一出現。
這樣做的好處:簡化了伺服器的設計,是伺服器更容易支援大量併發的HTTP請求
這樣做的缺點:每次請求都會造成無謂的TCP連線建立和斷開(連線需要三次握手,斷開需要四次揮手),增加了通訊量的開銷。
HTTP/1.1和一部分HTTP/1.0想出了持久連線,持久連線的特點:只要任意一端沒有明確提出斷開連線,則保持TCP連線狀態。持久連線的好處在於減少了TCP連線的重複建立和斷開所造成的額外開銷,減輕了伺服器的負載。Web頁面的顯示速度相應的加快。
HTTP/1.1的持續連線有非流水線方式和流水線方式
流水線方式是客戶在收到HTTP的響應報文之前就能接著傳送新的請求報文。與之相對應的非流水線方式是客戶在收到前一個響應後才能傳送下一個請求。
3)URI和URL的區別:
URI是同一資源標誌符,可以唯一標識一個資源
URL是同一資源定位符,可以提供該資源的路徑,URL是URI的子集。
舉個例子:
身份證號就是URI,通過身份證號讓我們能且僅能確定一個人。
如果採用URL方式:動物住址協議://地球/中國/浙江省/杭州市/西湖區/某個大學/12宿舍樓/23號/張三.人
4)HTTP報文結構的介紹:
HTTP有兩類報文:請求報文和響應報文
請求報文:從客戶端向伺服器傳送請求報文
響應報文:從伺服器到客戶的回答

請求報文:請求行+首部行+實體主體 其中請求行:方法+URL+版本資訊
響應報文:狀態行+首部行+實體主體 其中狀態行:版本+狀態碼+原因短語
請求報文的例子:

響應報文的例子:
請求的網頁轉移到了新的地址,則響應報文的狀態行和和一個首部行如下:

5)HTTP的GET和POST
HTTP請求行:請求方法+請求URI+協議版本
HTTP狀態行:協議版本+狀態碼+狀態碼的原因短語
請求行中的方法:
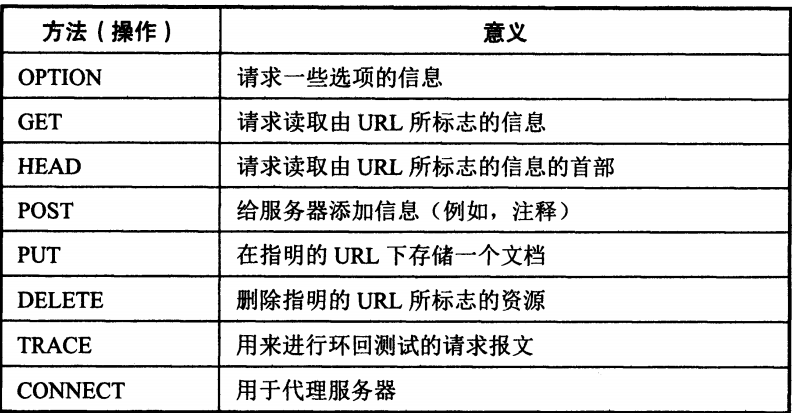
狀態行的狀態碼:
1XX:表示通知資訊的,如請求收到了或者正在進行處理
2XX:表示成功,如接收或知道了 200OK
3XX:表示重定向,如要完成請求還必須採取進一步的行動
301:永久性轉移
302:暫時性轉移
304:已快取
4XX:表示客戶的差錯,如請求中有錯誤的語法或者不能完成(404 ^-^)
5XX:表示伺服器的差錯,如伺服器失效無法完成請求
500:伺服器內部錯誤
503:服務不可用,稍等
關於Get和Post的區別,https://www.cnblogs.com/hyddd/archive/2009/03/31/1426026.html
6)Get和Post的區別:
GET和POST是我們常用的兩種HTTP Method,二者之間的區別主要包括如下五個方面:
1)從功能上講,GET一般用來從伺服器獲取資源,POST一般用來更新伺服器上的資源
2)從RESET服務角度上說,GET是冪等的,即讀取同一個資源得到相同的資料,而POST不是冪等的,因為每次請求對資源的改變並不是相同的,進一步講,GET不會改變伺服器上的資源,而POST會對伺服器資源進行改變。
3)很多人貪方便,更新資源時用了GET,將資訊通過請求行的URL欄位上傳,以?分割URL和傳輸資料,引數以& 相連,舉例:
7).HTTP和HTTPS的區別
https協議需要到CA申請證書,一般的免費證書很少,需要繳費
http是超文字傳輸協議,資訊是明文傳輸,https則是具有安全性的ssl加密傳輸協議
http和https使用的是完全不同的連線方式,所用的埠也不一樣,前者是80,後者是443.
http是超文字傳輸協議,它時使用明文的方式傳送我們的內容(沒有任何的加密),比如我們訪問了一個網址,我們需要在這個網址輸入密碼、登入賬號之類的操作,我們的賬號和密碼就會發送到網址的伺服器上面,但如果有人在中途截取了我們的資訊,那麼我們的重要的資訊就暴露了,為了解決Http在傳輸中不加密的問題,之後就增加了一個人SSL協議,這個協議提供網路連線的加密,如果我們訪問一個https的網站,我們的電腦會先和伺服器建立一個安全的連線通道,然後伺服器會先發送一份網址的安全資訊證書到我們的電腦,告訴我們的電腦,訪問的伺服器沒有問題,確認了資訊後,伺服器就會生成一個加鎖的箱子,但是這把鎖有兩把不一樣的鑰匙,一把時給我們的電腦的,一把是給伺服器自己,然後伺服器會把沒有上鎖的箱子和鑰匙發給我們的電腦,我們把資訊放在箱子裡面然後用鑰匙鎖上,然後發給伺服器,伺服器用自己的鑰匙開啟箱子來保證資訊的安全。
參考:
https://www.jianshu.com/p/650ad90bf563
https://www.bilibili.com/video/av12820479?from=search&seid=15667878026919071251
Http和Https的區別:
Http協議執行在TCP之上,明文傳輸,客戶端和伺服器都無法驗證對方身份。Https是身披SSL(Secure Socket Layer)外殼的Http,運行於SSL上,SSL執行與TCP上,是添加了加密和認證機制的HTTP。二者之間存在如下不同:
埠不同:Http與Https使用了不同的連線方式,用的埠也不一樣,前者是80,後者是443;
資源消耗:和Http通訊相比,Https通訊由於加減密處理消耗更多的CPU和記憶體資源;
開銷:Https通訊需要證書,而證書一般需要向認證機構購買;
共享金鑰加密:
加密和解密都使用同一金鑰的方式稱為共享金鑰方式稱為共享金鑰加密,也被稱為對稱金鑰加密。
公開金鑰加密:
公開金鑰加密使用一對非對稱的金鑰,一把叫做私有金鑰,另一把叫做公開金鑰。傳送密文的一方使用對方的公開金鑰進行加密處理,對方接收到被加密的資訊後,在使用自己的私有金鑰進行解密。
HTTPS採用混合加密機制:HTTPS採用共享加密和公開加密兩者並用的混合加密機制。因為公開金鑰加密和共享金鑰加密相比,處理速度慢,所以我們採用交換金鑰環節使用公開金鑰加密方式,之後的建立通訊交換報文階段則採用共享金鑰加密方式。
3.Cookie和Session
Cookie表示在HTTP伺服器和客戶端之間傳遞的狀態資訊,因為HTTP是無狀態的,但一些全球資訊網常常希望能夠識別使用者,所以全球資訊網站點可以使用Cookie來跟蹤使用者。
Cookie的工作原理:客戶端傳送一個請求,伺服器會為張三產生一個唯一的識別碼,並以此作為索引在伺服器的後端資料庫生成一個專案,接著在給客戶端的HTTP響應報文中添加了叫做Set-Cookie的首部欄位資訊,客戶端會儲存Cookie。當客戶端第二次往伺服器傳送請求時,客戶端會自動在請求報文中加入Cookie值後傳送出去。伺服器端發現客戶端傳送過來的Cookie後,會檢查究竟是從哪個客戶端傳送來的連線請求,然後對比伺服器上的記錄,最後得到狀態資訊。
舉例:





典型應用:伺服器知道使用者在什麼時間訪問了哪些頁面,以及訪問頁面的順序,如果使用者是在網上購物,伺服器可以為使用者維護一個所購物品的列表,使得張三在結束這次購物時可以一起付費。同時網址伺服器會根據使用者過去的訪問記錄向他推薦商品。
4.使用者訪問某網站的全過程
點選“百度”的頁面,其中URL是http://www.baidu.com。
(1)瀏覽器分析連結指向頁面的URL
(2)瀏覽器向DNS請求解析百度伺服器的IP地址
(3)域名系統DNS解析出百度伺服器的IP地址
(4)瀏覽器與伺服器建立TCP連線
(5)瀏覽器發出取檔案命令(一般是傳送HTTP請求)
(6)百度伺服器給出響應,把檔案傳送給瀏覽器(伺服器通過HTTP響應把頁面傳送給瀏覽器)
(7)釋放TCP連線
(8)瀏覽器顯示
5.TCP相關
1) TCP的三次握手
(1)三次握手的過程:TCP主機A向B傳送連線報文段,主機B對收到的主機A的請求報文段後,向A傳送確認,主機A再次對主機B的確認後,還要向B給出確認。
第一次握手:Client將標誌位SYN置為1,隨機產生一個值seq=J,並將該資料包傳送給Server,Client進入SYN_SENT狀態,等待Server確認。
第二次握手:Server收到資料包後由標誌位SYN=1知道Clinet請求建立連線,Server將標誌位SYN和ACK都置為1,ack=J+1,隨機產生一個值seq=K,並將該資料包傳送給Client以確認連線請求,Server進入SYN_RCVD狀態。
第三次握手:Client收到確認後,檢查ack是否為J+1,ACK是否為1,如果正確則將標誌位ACK置為1,ack= K +1,並將該資料包傳送給Server,Server檢查ack是否為K+1,ACK是否為1,如果正確則 連線建立成功,Client和Server進入ESTSBLISHED狀態,完成三次握手,隨後Client與Server之間可以開始傳輸資料了。
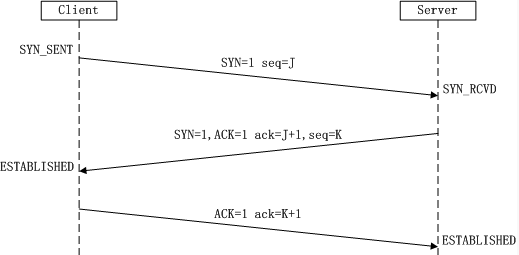
(2)為什麼要三次握手,假設A發出的第一個連線請求報文段沒有丟失,而是在某些網路結點長時間滯留了,以致延誤到連線釋放以後的某個時間才到達B,B收到這個失效的連線請求後,誤認為A又發了一次新的連線請求,於是就向A傳送確認報文段,同意建立連線,由於A並沒有傳送建立連線請求,因此不會向B傳送資料,但B卻以為連線建立了,並一直等待A傳送資料。B的許多資源就浪費了。
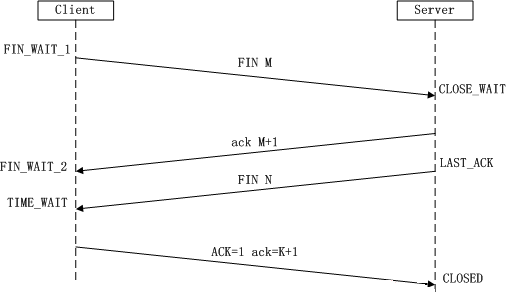
2) TCP的四次揮手(我要和你斷開連線,好的,斷吧。我也要和你斷開連線,好的,斷吧)
第一次揮手:Client傳送一個FIN,用來關閉到Clint到Server的資料傳送,Client進入FIN_WAIT_1狀態。
第二次揮手:Server收到FIN後,傳送一個ACK給Client,確認序號為收到序號+1(與SYN相同,一個FIN佔用一個序號 ),Server進入CLOSE_WAIT狀態。此時TCP連線處於半關閉狀態,即客戶端已經沒有要傳送的資料了,但是服務端若傳送資料,則客戶端仍要接收。
第三次揮手:Server傳送一個FIN,用來關閉Server到Client的資料傳送,Serve進入LAST_ACK狀態。
第四次揮手:Clinet收到FIN後,Client進入TIME_WAIT狀態,接著傳送一個ACK給Server ,確認序號為收到序號+1,Server進入CLOSED狀態,完成四次握手。
3).TCP與UDP的區別:
TCP是面向連線的,UDP是無連線的
TCP是可靠的,UDP是不可靠的
TCP只支援點對點通訊,UDP支援一對一、一對多、多對一、多對多通訊模式
TCP是面向位元組流的,UDP是面向報文的
TCP有擁塞控制機制,UDP沒有擁塞控制,適合媒體通訊
4).TCP如何保證資料的可靠性
TCP提供一種面向連線的服務。其中,面向連線意味著兩個使用TCP的應用(通常是一個客戶端和一個伺服器)在彼此交換資料之前必須建立一個TCP連線。在一個TCP連線中,僅有雙方進行彼此通訊,而位元組流服務意味著兩個應用程式通過TCP連線交換8bit位元組構成的位元組流,TCP不在位元組流中插入記錄識別符號。
資料包校驗:目標是檢測在傳輸過程中任何變化,若校驗出包有錯,則丟棄報文段並不給響應,這是TCP傳送資料段超時後會重發資料。
對失序資料包重排序:既然TCP報文段作為IP資料報來傳輸,而IP資料報可能會失序,因此TCP報文段的到達也可能會失序。TCP將對失序資料進行重排序,然後才交給應用層。
丟棄重複資料:對於重複資料,能夠丟棄重複資料
應答機制:當TCP收到發自TCP連線另一端的資料,它將傳送一個確認。這個確認不是立即傳送的,通常將推遲幾分之一秒
超時重發:當TCP傳送一個報文段後,它將啟動一個定時器,等待目的端確認收到這個報文段。如果不能即使收到一個確認,將重發這個報文段。
流量控制:TCP連線的每一方都有固定待續哦啊的緩衝空間。TCP的接收端只允許另一端傳送接收端緩衝區能接納的資料,者可以防止較快主機致使慢主機的緩衝區溢位,這就是流量控制,TCP使用的流量控制協議是可變大小的滑動視窗協議。
說明:一般叫做TCP報文段,IP資料包
5).TCP的擁塞控制:
擁塞控制就是防止過多的資料注入網路中,這樣可以使網路中的路由器或者鏈路不至於過載,擁塞控制方法主要有一下四種:
- 慢開始:
不要開始就傳送大量資料,先探測一下網路的擁塞程度,也就是說從小到大逐漸增加擁塞視窗的大小。
在一開始傳送的時候,cwnd =1 ,傳送第一個報文段M1,接收方收到後確認M1,傳送方收到對M1的確認後,把cwnd從1增加到2,於是傳送方傳送M2和M3兩個報文段。接收方收到M2和M3的確認。傳送方每收到對新報文段的確認就是傳送視窗乘以2,因此使用慢開始演算法,每經過一個RTT就將擁塞視窗cwnd加倍。
補充擁塞視窗cwnd:傳送方讓自己的傳送視窗等於擁塞視窗。
- 擁塞避免
當cwnd達到慢開始門限ssthresh時,改用擁塞避免演算法,擁塞避免演算法的思路是讓擁塞視窗cwnd緩慢地增大,即每經過一個RTT就把傳送法方的擁塞視窗cwnd加1,而不是加倍。這樣,擁塞視窗cwnd按線性規律緩慢增長。
補充:慢開始門限ssthresh:
當cwnd<ssthresh時,使用上述慢開始演算法
當cwnd>ssthresh時,使用擁塞避免演算法
無論在慢開始還是擁塞避免階段,只要出現超時(即很可能出現網路擁塞),就把慢開始門限值ssthresh設定為擁塞視窗的一半,與此同時開始執行慢開始演算法。
- 快重傳
快重傳要求接收方每收到一個失序的報文段後就立即發出重複確認(為的是傳送方及早知道有報文段沒有到達物件)而不要等待自己傳送資料時才捎帶確認。傳送方只要一連收到三個重複確認就應當立即重傳對方尚未收到的報文段,而不必繼續等待為報文段設定的重傳計時器到期。
- 快恢復
當傳送方收到三個重複確認時,就執行“乘法減小”演算法,把慢開始門限ssthresh減半。這是為了預防網路發生擁塞。
由於傳送方現在認為網路很可能沒有發生擁塞(如果網路發生了擁塞,就不會一連有好幾個報文段連續到達接收方,就不會導致接收方連續傳送重複確認),因此現在不執行慢開始演算法,而是把cwnd值設定為慢開始門限ssthresh減半後的值,然後執行擁塞避免演算法
6.ARP協議
ARP是解決同一區域網上的主機或路由器的IP地址和硬體地址的對映問題。
ARP解決這個問題的方法:在主機ARP快取記憶體中存放一個從IP地址到硬體地址的對映表。
主機A向主機B傳送IP資料報,首先A會在其ARP快取記憶體中檢視有無B的IP地址,如果有就查出其對應的硬體地址,再把這個硬體地址寫入MAC幀。如果沒有,主機A就會自行執行ARP,ARP程序在本區域網上廣播發送一個ARP請求分組,在本區域網中的所有主機上執行的ARP程序都會收到這個ARP請求分組, 主機B收到這個請求分組後,就會向A傳送一個ARP響應分組,並寫入自己的硬體地址。主機A收到主機B的ARP分組後,就在其ARP快取記憶體中寫入主機的IP地址與硬體地址的對映。
注意:ARP是解決同一個區域網上的主機或者路由器的IP地址和硬體地址的對映問題。ARP請求是通過廣播傳送的,而ARP響應是通過單播傳送的。
7.DNS域名系統和Hosts
域名方便人使用,但是機器習慣處理數字(IP地址),機器不是識別字母。
例如:把門我們把域名http://www.google。com輸入到瀏覽器後,需要DNS來把http://google.com轉換成谷歌搜尋的IP地址。
Hosts:網際網路早期,網路只有幾臺電腦,所以可以使用Hosts檔案記錄域名到IP的對映,後來網路越來越大,hosts就無法記錄這麼多對映關係了,所以現在都是使用DNS來完成從域名到IP地址的解析,但是Hosts檔案仍然儲存在作業系統中,Hosts檔案的優先順序高於DNS查詢,作業系統會在Hosts檔案中找域名對應的IP地址,沒有找到它才會去問DNS伺服器。
參考: https://www.cloudxns.net/Support/detail/id/1689.html
8.客戶端不斷請求連線會怎麼樣?DDos(Distributed Denial of Service分散式拒絕服務)攻擊?
伺服器會為每個請求建立一個連線,並向其傳送確認報文,然後等待客戶端進行確認
1)DDos攻擊
客戶端向伺服器傳送請求連線資料包
服務端向客戶端傳送確認資料包
客戶端不想伺服器傳送確認資料包,伺服器一直等待來自客戶端的確認
2)DDos(沒有徹底根治的辦法,除非不使用TCP)
限制同時開啟SYN半連線的數目
縮短SYN半連線的Time out時間
關閉不必必要的服務