
EM演算法原理詳解與高斯混合模型
藉助於machine learning cs229和文章【1】中的內容把EM演算法的過程順一遍,加深一下印象。
關於EM公式的推導,一般會有兩個證明,一個是利用Jesen不等式,另一個是將其分解成KL距離和L函式,本質是類似的。
下面介紹Jensen EM的整個推導過程。
Jensen不等式
回顧優化理論中的一些概念。設f是定義域為實數的函式,如果對於所有的實數x,
f′′(x)≥0 ,那麼f是凸函式。當x是向量時,如果其hessian矩陣H是半正定的(H≥0 ),那麼f是凸函式。如果f′′(x)>0 或者H>0 ,那麼稱f是嚴格凸函式。Jensen不等式表述如下:
如果f是凸函式,X是隨機變數,那麼
E[f(x)]≥f(E[x])
特別地,如果f是嚴格凸函式,那麼
E[f(x)]>f(E[x]) 當且僅當p(X=E(X))=1 ,也就是說X是常量。這裡我們將
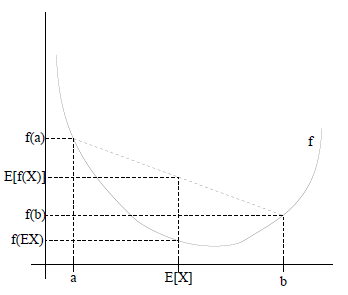
f(E[X]) 簡寫為f(EX) 。如果用圖表示會很清晰:
圖中,實線
f 是凸函式,X 是隨機變數,有0.5 的概率是a ,有0.5 的概率是b 。(就像擲硬幣一樣)。X 的期望值就是a 和b 的中值了,圖中可以看到E[f(x)]≥f(E[x]) 成立。當
f 是(嚴格)凹函式當且僅當−f 是(嚴格)凸函式。Jensen不等式應用於凹函式時,不等號方向反向,也就是
E[f(x)]≤f(E[x]) 。
EM演算法
給定的訓練樣本是
{x(1) ,樣例間獨立,我們想找到每個樣例隱含的類別z,能使得p(x,z)最大。p(x,z)的最大似然估計如下:,...,x(m)}
第一步是對極大似然取對數,第二步是對每個樣例的每個可能類別z求聯合分佈概率和。但是直接求
EM是一種解決存在隱含變數優化問題的有效方法。既然不能直接最大化
對於每一個樣例i,讓
可以由前面闡述的內容得到下面的公式:
相關推薦
EM演算法原理詳解與高斯混合模型
藉助於machine learning cs229和文章【1】中的內容把EM演算法的過程順一遍,加深一下印象。 關於EM公式的推導,一般會有兩個證明,一個是利用Jesen不等式,另一個是將其分解成KL距離和L函式,本質是類似的。 下面介紹Jensen EM的
EM演算法與高斯混合模型
由k個高斯模型加權組成,α是各高斯分佈的權重,Θ是引數。對GMM模型的引數估計,就要用EM演算法。更一般的講,EM演算法適用於帶有隱變數的概率模型的估計,即不同的高斯分佈所對應的類別變數。 為何不能使用極大似然估計,如果直接使用極大似然估計
EM演算法-原理詳解
1. 前言 概率模型有時既含有觀測變數(observable variable),又含有隱變數或潛在變數(latent variable),如果僅有觀測變數,那麼給定資料就能用極大似然估計或貝葉斯估計來估計model引數;但是當模型含有隱變數時,需要一種含有隱變數的概率模型引數估計的極大似然方法估計——EM
隨機森林 演算法原理詳解與實現步驟
#include <cv.h> // opencv general include file #include <ml.h> // opencv machine learning include file #include <stdio.h>
Stanford機器學習課程筆記4-Kmeans與高斯混合模型
這一部分屬於無監督學習的內容,無監督學習內容主要包括:Kmeans聚類演算法、高斯混合模型及EM演算法、Factor Analysis、PCA、ICA等。本文是Kmeans聚類演算法、高斯混合模型的筆記,EM演算法是適用於存在latent/hidden變數的通用演算法,高斯混
EM演算法及GMM(高斯混合模型)的詳解
一、預備知識 1.1、協方差矩陣 在高維計算協方差的時候,分母是n-1,而不是n。協方差矩陣的大小與維度相同。 1.2、黑塞矩陣 1.3、正定矩陣 二、高斯混合模型 點模式的分析中,一般會考察如下五種內容
高斯混合模型視訊背景建模的EM演算法與Matlab 實現
1.問題描述 影像的背景前景分離. 輸⼊為影像監控的1000 幀 (如下⽅圖中左邊所⽰), 要求輸出是背景和前景 (如下⽅圖中右邊所⽰). 2.背景知識 觀察待處理的監控影像,可以發現,前景主要是來來往往的行人,背景始終是攝像頭對準的固定區域,
EM演算法在高斯混合模型中的應用(詳細解釋與求解)
1、高斯混合模型GMM 是指具有以下概率分佈的模型: P ( y
[從今天開始修煉資料結構]圖的最短路徑 —— 迪傑斯特拉演算法和弗洛伊德演算法的詳解與Java實現
在網圖和非網圖中,最短路徑的含義不同。非網圖中邊上沒有權值,所謂的最短路徑,其實就是兩頂點之間經過的邊數最少的路徑;而對於網圖來說,最短路徑,是指兩頂點之間經過的邊上權值之和最少的路徑,我們稱路徑上第一個頂點是源點,最後一個頂點是終點。 我們講解兩種求最短路徑的演算法。第一種,從某個源點到其餘各頂點的最短路徑
px em rem的詳解與區別
聲明 -c -s 項目 屏幕分辨率 div 推薦 項目開發 pre 在前端項目開發中,px,em,以及rem都是頁面布局常用的單位,雖然它們是長度單位,但是所含的意義不一樣。通過復習和查閱,總結了以下知識。 px像素(Pixel) 定義:相對長度單位
【機器學習】EM演算法在高斯混合模型學習中的應用
前言 EM演算法,此部落格介紹了EMEM演算法相關理論知識,看本篇部落格前先熟悉EMEM演算法。 本篇部落格打算先從單個高斯分佈說起,然後推廣到多個高斯混合起來,最後給出高斯混合模型引數求解過程。 單個高斯分佈 假如我們有一些資料,這些資料來自同一個
hash演算法原理詳解
一.概念 雜湊表就是一種以 鍵-值(key-indexed) 儲存資料的結構,我們只要輸入待查詢的值即key,即可查詢到其對應的值。 雜湊的思路很簡單,如果所有的鍵都是整數,那麼就可以使用一個簡單的無序陣列來實現:將鍵作為索引,值即為其對應的值,這樣就可以快速訪問任意
Adaboost演算法原理詳解
Adaboost介紹 Adaboost,是英文Adaptive Boosting(自適應增強)的縮寫,它的自適應在於:前一個基本分類器分錯的樣本會得到加強,加權後的全體樣本再次被用來訓練下一個基本分類器,同時,在每一輪中加入一個新的弱分類器,直到達到某個預定的足
Skip List(跳躍表)原理詳解與實現
#include<stdio.h> #include<stdlib.h> #define MAX_LEVEL 10 //最大層數 //節點 typedef struct nodeStructure { int key; int value
KNN(k-nearest neighbor的縮寫)最近鄰演算法原理詳解
k-最近鄰演算法是基於例項的學習方法中最基本的,先介紹基於例項學習的相關概念。 基於例項的學習 已知一系列的訓練樣例,很多學習方法為目標函式建立起明確的一般化描述;但與此不同,基於例項的學習方法只是簡單地把訓練樣例儲存起來。 從這些例項中泛化的工作被推遲到必須分類新的例
基於MeanShift的Camshift演算法原理詳解(opencv實現,有原始碼)
基於MeanShift的Camshift演算法原理詳解(整理) 第一篇MeanShift原理和實現 1 MeanShift原理 如下圖所示:矩形視窗中的紅色點代表特徵資料點,矩形中的圓圈代表選取視窗。meanshift演算法的目的是找到含有最多特徵的視窗區域,即使圓心與概
05 EM演算法 - 高斯混合模型 - GMM
04 EM演算法 - EM演算法收斂證明 __GMM__(Gaussian Mixture Model, 高斯混合模型)是指該演算法由多個高斯模型線性疊加混合而成。每個高斯模型稱之為component。 __GMM演算法__描述的是資料的本身存在的一種分佈,即樣本特徵屬性的分佈,和預測值Y無關。顯然G
faster-RCNN演算法原理詳解
縮排經過RCNN和Fast RCNN的積澱,Ross B. Girshick在2016年提出了新的Faster RCNN,在結構上,Faster RCN已經將特徵抽取(feature extraction),proposal提取,bounding box regr
蟻群演算法原理詳解和matlab程式碼
1原理: 螞蟻在尋找食物源的時候,能在其走過的路徑上釋放一種叫資訊素的激素,使一定範圍內的其他螞蟻能夠察覺到。當一些路徑上通過的螞蟻越來越多時,資訊素也就越來越多,螞蟻們選擇這條路徑的概率也就越高,結果導致這條路徑上的資訊素又增多,螞蟻走這條路的概率又增加,生生
密碼學_RSA演算法原理詳解
1.RSA演算法簡介: RSA公鑰加密演算法是1977年由羅納德·李維斯特(Ron Rivest)、阿迪·薩莫爾(Adi Shamir)和倫納德·阿德曼(Leonard Adleman)一