
Java 常用的八種排序演算法與程式碼實現
寫排序演算法是一個大工程,估計得好多天才可以寫完。。。就慢慢寫吧。未完待續。。。。
內部排序和外部排序
內部排序是資料記錄在記憶體中進行排序,而外部排序是因排序的資料很大,一次不能容納全部的排序記錄,在排序過程中需要訪問外存。
我們這裡說說八大排序就是內部排序。
排序演算法的穩定性?
排序演算法可以根據穩定性分為兩種:穩定和非穩定演算法。那麼怎麼區分它們?如果連結串列中存在兩個相同元素,穩定排序演算法可以在排序之後保持他兩原來的次序,而非穩定性的則不能保證。

演算法穩定性的好處:排序演算法如果是穩定的,那麼從一個鍵上排序,然後再從另一個鍵上排序,第一個鍵排序的結果可以為第二個鍵排序所用。基數排序就是這樣,先按低位排序,逐次按高位排序,低位相同的元素其順序再高位也相同時是不會改變的。
排序分類
簡單排序類別:
- 直接插入排序
- 選擇排序演算法
兩種簡單排序演算法分別是插入排序和選擇排序,兩個都是資料量小時效率高。實際中插入排序一般快於選擇排序,由於更少的比較和在有差不多有序的集合表現更好的效能。
有效演算法:
- 歸併排序演算法、
- 堆排序演算法、
- 快速排序演算法
氣泡排序和變體類別:
- 氣泡排序、
- 希爾排序、
- 梳排序
這種類別的演算法在實際中很少使用到,因為效率低下,但在理論教學中常常提到。
線性時間的排序:
- 計數排序、
- 桶排序、
- 基數排序、
1. 直接插入排序
插入排序是穩定的
思想:
將一個記錄插入到已排序好的有序表中,從而得到一個新,記錄數增1的有序表。即:先將序列的第1個記錄看成是一個有序的子序列,然後從第2個記錄逐個進行插入,直至整個序列有序為止。要點:
設立哨兵,作為臨時儲存和判斷陣列邊界之用。演算法流程圖
效率
時間複雜度:O(n^2).- 做法:
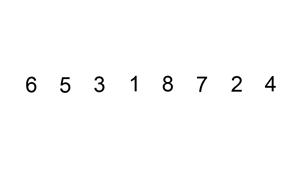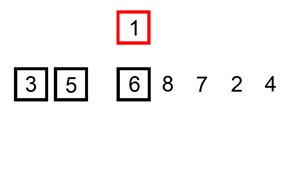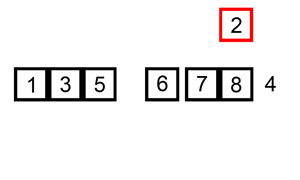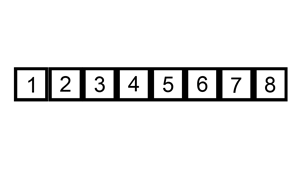
首先設定插入次數,即迴圈次數,for(int i=1;i<length;i++),1個數的那次不用插入。
設定插入數和得到已經排好序列的最後一個數的位數。insertNum和j=i-1。
從最後一個數開始向前迴圈,如果插入數小於當前數,就將當前數向後移動一位。
將當前數放置到空著的位置,即j+1。- 程式碼實現:
private static int[] insertionSort(int[] arrayToSort) {
int length = arrayToSort.length;
int 2. 希爾排序
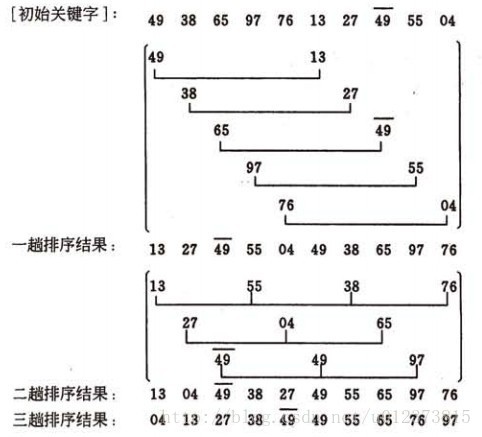
希爾排序是1959 年由D.L.Shell 提出來的,相對直接排序有較大的改進。希爾排序又叫縮小增量排序。希爾排序方法是一個不穩定的排序方法。
思想
先將整個待排序的記錄序列分割成為若干組,然後分別對每個組中的元素進行直接插入排序,待整個序列中的記錄“基本有序”時,再對全體記錄進行依次直接插入排序。(也就是將資料分組,組內巢狀插入排序)演算法流程圖
- 效率
最好:O(n log n)
最壞:即剛好與所要的順序相反,時間複雜度為O(n^2)
分組的依據(n/2)對複雜度的影響比較大。 - 做法
首先確定分的組數。
然後對組中元素進行插入排序。
然後將length/2,重複1,2步,直到length=0為止。 - 程式碼實現
private static int[] shellSort(int[] arrayToSort) {
int length = arrayToSort.length;
while (length != 0) {
length = length / 2;
for (int j = 0; j < length; j++) { //分的組數 ,length 為組的步長
for (int i = j + length; i < arrayToSort.length; i += length) { //遍歷每組中的元素,從第二個數開始 第一個元素是 j
//裡面實際上是嵌套了一個 插入排序
int x = i - length;//j為當前組有序序列最後一位的位數
int temp = arrayToSort[i];//當前要插入的元素
while (x >= 0 && arrayToSort[x] > temp) { //從後往前遍歷。
arrayToSort[x + length] = arrayToSort[x];//向後移動length位
x -= length;
}
arrayToSort[x + length] = temp;
}
}
}
return arrayToSort;
}希爾排序的時間效能優於直接插入排序的原因:
- 當檔案初態基本有序時直接插入排序所需的比較和移動次數均較少。
- 當n值較小時,n和n2的差別也較小,即直接插入排序的最好時間複雜度O(n)和最壞時間複雜度0(n2)差別不大。
- 在希爾排序開始時增量較大,分組較多,每組的記錄數目少,故各組內直接插入較快,後來增量di逐漸縮小,分組數逐漸減少,而各組的記錄數目逐漸增多,但由於已經按di-1作為距離排過序,使檔案較接近於有序狀態,所以新的一趟排序過程也較快。
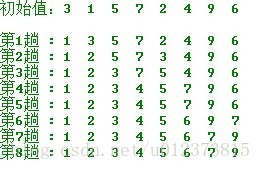
3. 簡單選擇排序
選擇排序類似於插入排序,只是是有選擇的插入
思想
在要排序的一組數中,選出最小(或者最大)的一個數與第1個位置的數交換;然後在剩下的數當中再找最小(或者最大)的與第2個位置的數交換,依次類推,直到第n-1個元素(倒數第二個數)和第n個元素(最後一個數)比較為止。演算法流程圖
- 效率
時間複雜度:n(n − 1) / 2 ∈ Θ(n2) - 做法
按照陣列順序,記錄當前數的位置 和大小,
找尋陣列中當前數以後的(也就是未排序的) 最小的數和 位置,
將最小數的位置 和數值與當前數 交換 - 程式碼實現
private static int[] simpleSelectSort(int[] arrayToSort) {
int length = arrayToSort.length;
for (int i = 0; i < length; i++) {
int key = arrayToSort[i];
int position = i; // 最小資料的位置
for (int j = i + 1; j < length; j++) { //遍歷後面的資料比較最小
if (arrayToSort[j] < key) { //如果當前資料不是最小的,則交換
//記錄最小的
key = arrayToSort[j];
position = j;
}
}
//交換
arrayToSort[position] = arrayToSort[i]; //將 最小的 位置放如 i 的值
arrayToSort[i] = key; //將最小的值放入 i
}
return arrayToSort;
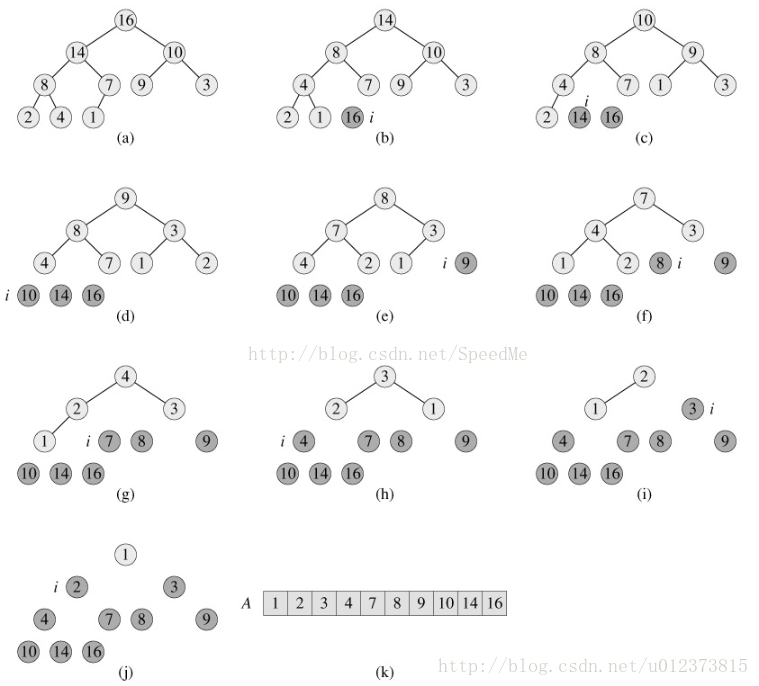
}4. 堆排序
堆排序是選擇排序種類的一部分 不是穩定的排序。堆排序是一種樹形選擇排序,是對直接選擇排序的有效改進。
- 思想
通過建立大頂堆(堆總是一棵完全二叉樹。),篩選出序列中最大的元素,進行排列。 - 演算法流程圖
下圖中是堆最大堆進行排序的行為。
- 效率
時間複雜度是O(nlogn) - 做法
將序列構建成大頂堆。
將根節點與最後一個節點交換,然後斷開最後一個節點。
重複第一、二步,直到所有節點斷開。 - 程式碼實現

private static int[] heapSort(int[] arrayToSort) {
int arrayLength = arrayToSort.length;
//迴圈建堆
for (int i = 0; i < arrayLength - 1; i++) {
//建大頂堆
buildMaxHeap(arrayToSort, arrayLength - 1 - i);
//交換堆頂和最後一個元素
swap(arrayToSort, 0, arrayLength - 1 - i);
}
return arrayToSort;
}
private static void swap(int[] data, int i, int j) {
int tmp = data[i];
data[i] = data[j];
data[j] = tmp;
}
/**
* 對data陣列從0到lastIndex建大頂堆
*
* @param data
* @param lastIndex
*/
private static void buildMaxHeap(int[] data, int lastIndex) {
// 從lastIndex處節點(最後一個節點)的父節點開始
// (lastIndex - 1) / 2 為最後的一個根節點的索引
for (int i = (lastIndex - 1) / 2; i >= 0; i--) {
//k儲存正在判斷的節點
int k = i;
//如果當前k節點的子節點存在
while (k * 2 + 1 <= lastIndex) {
//k節點的左子節點的索引
int biggerIndex = 2 * k + 1;
//如果biggerIndex小於lastIndex,即biggerIndex+1代表的k節點的右子節點存在
if (biggerIndex < lastIndex) {
//若果右子節點的值較大
if (data[biggerIndex] < data[biggerIndex + 1]) {
//若左節點小於右節點,則biggerIndex+1 此時 則biggerIndex 實際為右節點的索引,所以biggerIndex總是記錄較大子節點的索引
biggerIndex++;
}
}
//如果k節點(k為根節點)的值小於其較大的子節點的值
if (data[k] < data[biggerIndex]) {
//交換他們
swap(data, k, biggerIndex);
//將biggerIndex賦予k,開始while迴圈的下一次迴圈,重新保證k節點的值大於其左右子節點的值
} else {
break;
}
}
}
}5. 氣泡排序
這種類別的演算法在實際中很少使用到,因為效率低下,但在理論教學中常常提到。
- 思想
將序列中所有元素兩兩比較,將最大的放在最後面。讓較大的數往下沉,較小的往上冒
將剩餘序列中所有元素兩兩比較,將最大的放在最後面。 - 演算法流程圖
- 效率
氣泡排序效率非常低,效率還不如插入排序。 - 做法
將序列中所有元素兩兩比較,將最大的放在最後面。
將剩餘序列中所有元素兩兩比較,將最大的放在最後面。
重複第二步,直到只剩下一個數。 - 程式碼實現
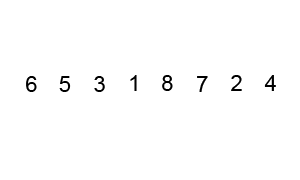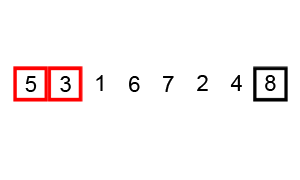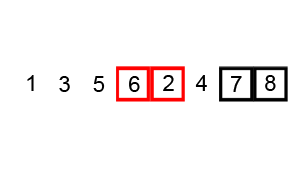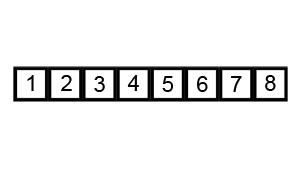
private static int[] bubbleSort(int[] arrayToSort) {
int arrayLength = arrayToSort.length;
for (int i = 0; i < arrayLength; i++) {//i為拍好序的元素個數
for (int j = 0; j < arrayLength - i - 1; j++) { //j 為未排序的元素個數
if (arrayToSort[j + 1] < arrayToSort[j]) {
int tmp = arrayToSort[j + 1];
arrayToSort[j + 1] = arrayToSort[j];
arrayToSort[j] = tmp;
}
}
System.out.println();
print(arrayToSort);
}
return arrayToSort;
}氣泡排序優化
- 思想
對氣泡排序常見的改進方法是加入一標誌性變數exchange,用於標誌某一趟排序過程中是否有資料交換,如果進行某一趟排序時並沒有進行資料交換,則說明資料已經按要求排列好,可立即結束排序,避免不必要的比較過程。 - 做法
設定一標誌性變數pos,用於記錄每趟排序中最後一次進行交換的位置。由於pos位置之後的記錄均已交換到位,
故在進行下一趟排序時只要掃描到pos位置即可。 - 程式碼實現
private static int[] bubbleSort2(int[] arrayToSort) {
int arrayLength = arrayToSort.length;
for (int i = 0; i < arrayLength; i++) {//i為拍好序的元素個數
int pos = 0;
for (int j = 0; j < arrayLength - i - 1; j++) { //j 為未排序的元素個數
if (arrayToSort[j + 1] < arrayToSort[j]) {
int tmp = arrayToSort[j + 1];
arrayToSort[j + 1] = arrayToSort[j];
arrayToSort[j] = tmp;
pos = 1;
}
}
if (pos == 0) {// pos 等於 0 時,說明已經排序好了,就不需要再做比較了
break;
}
}
return arrayToSort;
}6. 快速排序
快速排序(類似於歸併演算法)是一種分而治之演算法。首先它將列表分為兩個更小的子列表:一個大一個小。然後遞迴排序這些子列表。下面就用分而治之的方法來排序子陣列。快速排序是一個不穩定的排序方法。
- 思想
1)選擇一個基準元素,通常選擇第一個元素或者最後一個元素,
2)通過一趟排序講待排序的記錄分割成獨立的兩部分,其中一部分記錄的元素值均比基準元素值小。另一部分記錄的 元素值比基準值大。
3)此時基準元素在其排好序後的正確位置
4)然後分別對這兩部分記錄用同樣的方法繼續進行排序,直到整個序列有序。 - 演算法流程圖
第一趟的排序圖
遞迴排序的全過程
- 效率
快速排序:是目前基於比較的內部排序中被認為是最好的方法,當待排序的關鍵字是隨機分佈時,快速排序的平均時間最短; - 做法
選擇第一個數為p,小於p的數放在左邊,大於p的數放在右邊。
遞迴的將p左邊和右邊的數都按照第一步進行,直到不能遞迴。 - 程式碼實現


private static int[] quickSort(int[] arrayToSort, int start, int end) {
if (start < end) {
int base = arrayToSort[start]; // 選定的基準值(第一個數值作為基準值)
int temp; // 記錄臨時中間值
int i = start, j = end;
do {
while (arrayToSort[i] < base && i < end)// 左邊 i < end 陣列不能越界
i++;
while (arrayToSort[j] > base && j > start)// 右邊 j > start 陣列不能越界
j--;
if (i <= j) {//得到上邊兩個while的不滿足條件,比如 下標 i 的值大於 base 和 下標 j 的值小於 base 交換位置
temp = arrayToSort[i];
arrayToSort[i] = arrayToSort[j];
arrayToSort[j] = temp;
i++;
j--;
}
} while (i <= j);// i <= j 說明第一趟還沒有比較完。
// 由於第一趟的兩個 while i++和 j-- 操作,i 和j之間的元素都是排序好的,但是i和j 之間相差的元素個數不確定。
if (start < j) {
quickSort(arrayToSort, start, j); //遞迴比較第一趟的左邊部分,第一趟迴圈完畢,下標 j 是小於 base 的 所以 j 之前的就是 左邊部分
}
if (end > i) {
quickSort(arrayToSort, i, end);//遞迴比較第一趟的右邊邊部分,下標 i 是大於 base 的 所以 j 之前的就是 右邊部分
}
}
return arrayToSort;
}7. 歸併排序
- 思想
- 演算法流程圖
- 效率
- 做法
- 程式碼實現
8. 基數排序
- 思想
- 演算法流程圖
- 效率
- 做法
- 程式碼實現
未完待續。。。