
Kafka消費組(consumer group)
在開始之前,我想花一點時間先來明確一些概念和術語,這會極大地方便我們下面的討論。另外請原諒這文章有點長,畢竟要討論的東西很多,雖然已然刪除了很多太過細節的東西。
一、 誤區澄清與概念明確
1 Kafka的版本
很多人在Kafka中國社群(替群主做個宣傳,QQ號:162272557)提問時的開頭經常是這樣的:“我使用的kafka版本是2.10/2.11, 現在碰到一個奇怪的問題。。。。” 無意冒犯,但這裡的2.10/2.11不是kafka的版本,而是編譯kafka的Scala版本。Kafka的server端程式碼是由Scala語言編寫的,目前Scala主流的3個版本分別是2.10、2.11和2.12。實際上Kafka現在每個PULL request都已經自動增加了這三個版本的檢查。下圖是我的一個PULL request,可以看到這個fix會同時使用3個scala版本做編譯檢查:
目前廣泛使用kafka的版本應該是這三個大版本:0.8.x, 0.9.x和0.10.* 。 這三個版本對於consumer和consumer group來說都有很大的變化,我們後面會詳談。
2 新版本 VS 老版本
“我的kafkaoffsetmonitor為什麼無法監控到offset了?”——這是我在Kafka中國社群見到最多的問題,沒有之一!實際上,Kafka 0.9開始提供了新版本的consumer及consumer group,位移的管理與儲存機制發生了很大的變化——新版本consumer預設將不再儲存位移到zookeeper中,而目前kafkaoffsetmonitor還沒有應對這種變化(雖然已經有很多人在要求他們改了,詳見
二、消費者組 (Consumer Group)
1 什麼是消費者組
其實對於這些基本概念的普及,網上資料實在太多了。我本不應該再畫蛇添足了,但為了本文的完整性,我還是要花一些篇幅來重談consumer group,至少可以說說我的理解。值得一提的是,由於我們今天基本上只探討consumer group,對於單獨的消費者不做過多討論。
什麼是consumer group? 一言以蔽之,consumer group是kafka提供的可擴充套件且具有容錯性的消費者機制。既然是一個組,那麼組內必然可以有多個消費者或消費者例項(consumer instance),它們共享一個公共的ID,即group ID。組內的所有消費者協調在一起來消費訂閱主題(subscribed topics)的所有分割槽(partition)。當然,每個分割槽只能由同一個消費組內的一個consumer來消費。(網上文章中說到此處各種炫目多彩的圖就會緊跟著丟擲來,我這裡就不畫了,請原諒)。個人認為,理解consumer group記住下面這三個特性就好了:
- consumer group下可以有一個或多個consumer instance,consumer instance可以是一個程序,也可以是一個執行緒
- group.id是一個字串,唯一標識一個consumer group
- consumer group下訂閱的topic下的每個分割槽只能分配給某個group下的一個consumer(當然該分割槽還可以被分配給其他group)
2 消費者位置(consumer position)
消費者在消費的過程中需要記錄自己消費了多少資料,即消費位置資訊。在Kafka中這個位置資訊有個專門的術語:位移(offset)。很多訊息引擎都把這部分資訊儲存在伺服器端(broker端)。這樣做的好處當然是實現簡單,但會有三個主要的問題:1. broker從此變成有狀態的,會影響伸縮性;2. 需要引入應答機制(acknowledgement)來確認消費成功。3. 由於要儲存很多consumer的offset資訊,必然引入複雜的資料結構,造成資源浪費。而Kafka選擇了不同的方式:每個consumer group儲存自己的位移資訊,那麼只需要簡單的一個整數表示位置就夠了;同時可以引入checkpoint機制定期持久化,簡化了應答機制的實現。
3 位移管理(offset management)
3.1 自動VS手動
Kafka預設是定期幫你自動提交位移的(enable.auto.commit = true),你當然可以選擇手動提交位移實現自己控制。另外kafka會定期把group消費情況儲存起來,做成一個offset map,如下圖所示:
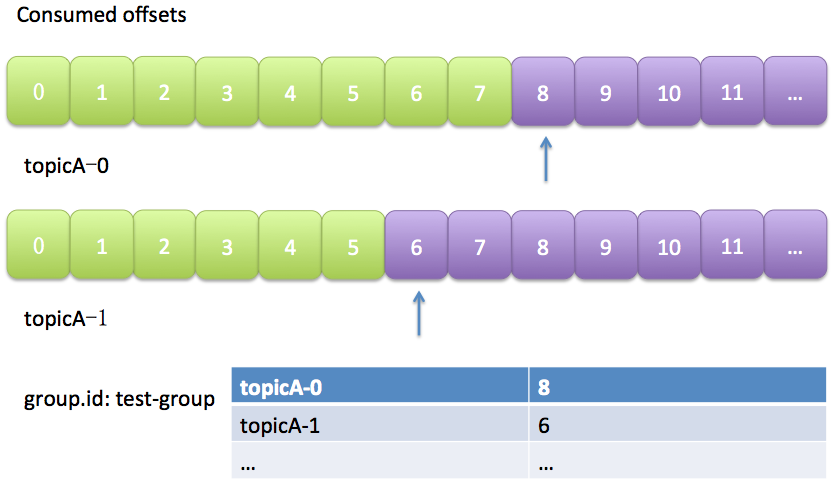
上圖中表明瞭test-group這個組當前的消費情況。
3.2 位移提交
老版本的位移是提交到zookeeper中的,圖就不畫了,總之目錄結構是:/consumers/<group.id>/offsets/<topic>/<partitionId>,但是zookeeper其實並不適合進行大批量的讀寫操作,尤其是寫操作。因此kafka提供了另一種解決方案:增加__consumeroffsets topic,將offset資訊寫入這個topic,擺脫對zookeeper的依賴(指儲存offset這件事情)。__consumer_offsets中的訊息儲存了每個consumer group某一時刻提交的offset資訊。依然以上圖中的consumer group為例,格式大概如下:

__consumers_offsets topic配置了compact策略,使得它總是能夠儲存最新的位移資訊,既控制了該topic總體的日誌容量,也能實現儲存最新offset的目的。compact的具體原理請參見:Log Compaction
4 Rebalance
4.1 什麼是rebalance?
rebalance本質上是一種協議,規定了一個consumer group下的所有consumer如何達成一致來分配訂閱topic的每個分割槽。比如某個group下有20個consumer,它訂閱了一個具有100個分割槽的topic。正常情況下,Kafka平均會為每個consumer分配5個分割槽。這個分配的過程就叫rebalance。
4.2 什麼時候rebalance?
這也是經常被提及的一個問題。rebalance的觸發條件有三種:
- 組成員發生變更(新consumer加入組、已有consumer主動離開組或已有consumer崩潰了——這兩者的區別後面會談到)
- 訂閱主題數發生變更——這當然是可能的,如果你使用了正則表示式的方式進行訂閱,那麼新建匹配正則表示式的topic就會觸發rebalance
- 訂閱主題的分割槽數發生變更
4.3 如何進行組內分割槽分配?
之前提到了group下的所有consumer都會協調在一起共同參與分配,這是如何完成的?Kafka新版本consumer預設提供了兩種分配策略:range和round-robin。當然Kafka採用了可插拔式的分配策略,你可以建立自己的分配器以實現不同的分配策略。實際上,由於目前range和round-robin兩種分配器都有一些弊端,Kafka社群已經提出第三種分配器來實現更加公平的分配策略,只是目前還在開發中。我們這裡只需要知道consumer group預設已經幫我們把訂閱topic的分割槽分配工作做好了就行了。
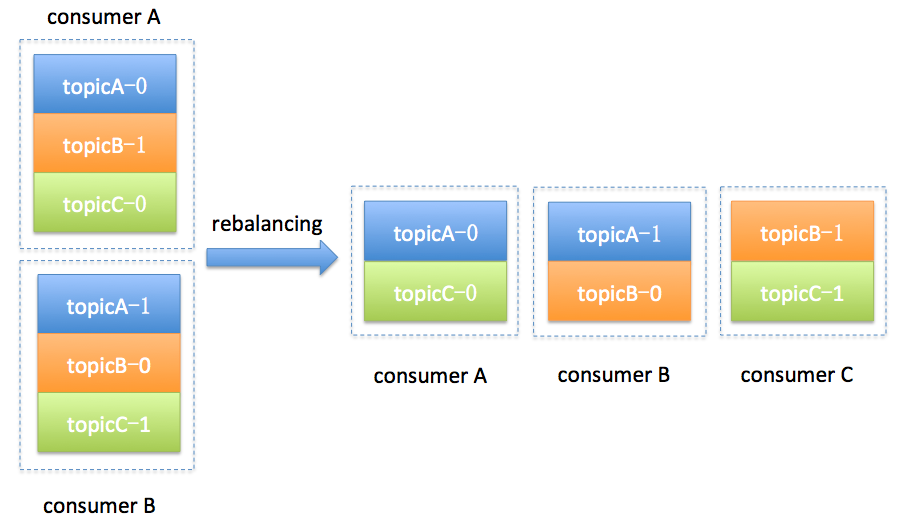
簡單舉個例子,假設目前某個consumer group下有兩個consumer: A和B,當第三個成員加入時,kafka會觸發rebalance並根據預設的分配策略重新為A、B和C分配分割槽,如下圖所示:
4.4 誰來執行rebalance和consumer group管理?
Kafka提供了一個角色:coordinator來執行對於consumer group的管理。坦率說kafka對於coordinator的設計與修改是一個很長的故事。最新版本的coordinator也與最初的設計有了很大的不同。這裡我只想提及兩次比較大的改變。
首先是0.8版本的coordinator,那時候的coordinator是依賴zookeeper來實現對於consumer group的管理的。Coordinator監聽zookeeper的/consumers/<group>/ids的子節點變化以及/brokers/topics/<topic>資料變化來判斷是否需要進行rebalance。group下的每個consumer都自己決定要消費哪些分割槽,並把自己的決定搶先在zookeeper中的/consumers/<group>/owners/<topic>/<partition>下注冊。很明顯,這種方案要依賴於zookeeper的幫助,而且每個consumer是單獨做決定的,沒有那種“大家屬於一個組,要協商做事情”的精神。
基於這些潛在的弊端,0.9版本的kafka改進了coordinator的設計,提出了group coordinator——每個consumer group都會被分配一個這樣的coordinator用於組管理和位移管理。這個group coordinator比原來承擔了更多的責任,比如組成員管理、位移提交保護機制等。當新版本consumer group的第一個consumer啟動的時候,它會去和kafka server確定誰是它們組的coordinator。之後該group內的所有成員都會和該coordinator進行協調通訊。顯而易見,這種coordinator設計不再需要zookeeper了,效能上可以得到很大的提升。後面的所有部分我們都將討論最新版本的coordinator設計。
4.5 如何確定coordinator?
上面簡單討論了新版coordinator的設計,那麼consumer group如何確定自己的coordinator是誰呢? 簡單來說分為兩步:
- 確定consumer group位移資訊寫入__consumers_offsets的哪個分割槽。具體計算公式:
- __consumers_offsets partition# = Math.abs(groupId.hashCode() % groupMetadataTopicPartitionCount) 注意:groupMetadataTopicPartitionCount由offsets.topic.num.partitions指定,預設是50個分割槽。
- 該分割槽leader所在的broker就是被選定的coordinator
4.6 Rebalance Generation
JVM GC的分代收集就是這個詞(嚴格來說是generational),我這裡把它翻譯成“屆”好了,它表示了rebalance之後的一屆成員,主要是用於保護consumer group,隔離無效offset提交的。比如上一屆的consumer成員是無法提交位移到新一屆的consumer group中。我們有時候可以看到ILLEGAL_GENERATION的錯誤,就是kafka在抱怨這件事情。每次group進行rebalance之後,generation號都會加1,表示group進入到了一個新的版本,如下圖所示: Generation 1時group有3個成員,隨後成員2退出組,coordinator觸發rebalance,consumer group進入Generation 2,之後成員4加入,再次觸發rebalance,group進入Generation 3.

4.7 協議(protocol)
前面說過了, rebalance本質上是一組協議。group與coordinator共同使用它來完成group的rebalance。目前kafka提供了5個協議來處理與consumer group coordination相關的問題:
- Heartbeat請求:consumer需要定期給coordinator傳送心跳來表明自己還活著
- LeaveGroup請求:主動告訴coordinator我要離開consumer group
- SyncGroup請求:group leader把分配方案告訴組內所有成員
- JoinGroup請求:成員請求加入組
- DescribeGroup請求:顯示組的所有資訊,包括成員資訊,協議名稱,分配方案,訂閱資訊等。通常該請求是給管理員使用
Coordinator在rebalance的時候主要用到了前面4種請求。
4.8 liveness
consumer如何向coordinator證明自己還活著? 通過定時向coordinator傳送Heartbeat請求。如果超過了設定的超時時間,那麼coordinator就認為這個consumer已經掛了。一旦coordinator認為某個consumer掛了,那麼它就會開啟新一輪rebalance,並且在當前其他consumer的心跳response中新增“REBALANCE_IN_PROGRESS”,告訴其他consumer:不好意思各位,你們重新申請加入組吧!
4.9 Rebalance過程
終於說到consumer group執行rebalance的具體流程了。很多使用者估計對consumer內部的工作機制也很感興趣。下面就跟大家一起討論一下。當然我必須要明確表示,rebalance的前提是coordinator已經確定了。
總體而言,rebalance分為2步:Join和Sync
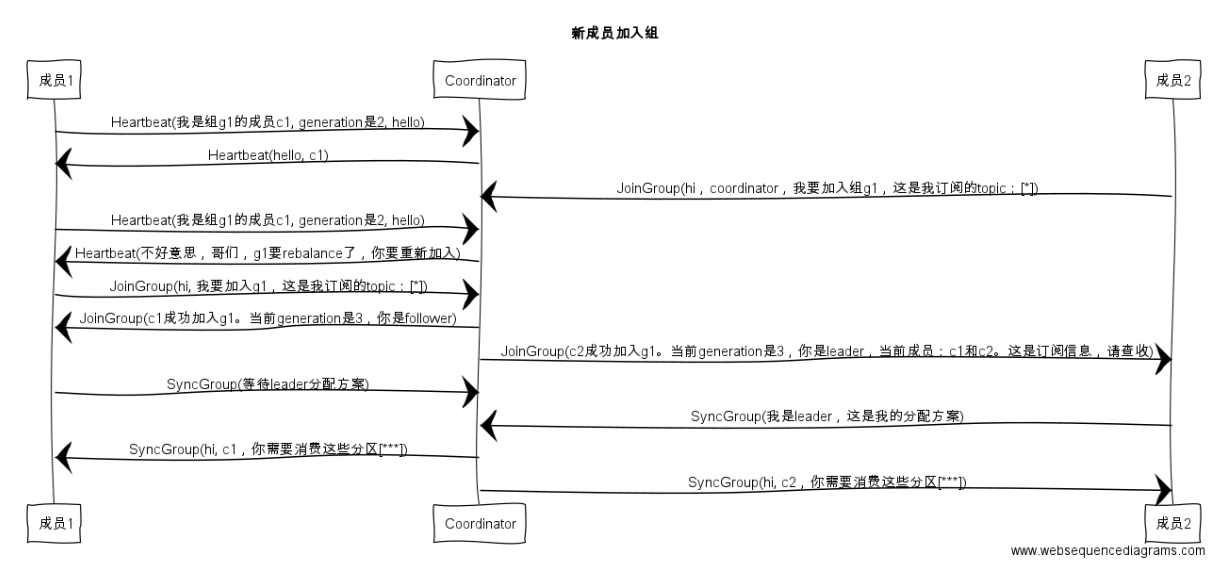
1 Join, 顧名思義就是加入組。這一步中,所有成員都向coordinator傳送JoinGroup請求,請求入組。一旦所有成員都發送了JoinGroup請求,coordinator會從中選擇一個consumer擔任leader的角色,並把組成員資訊以及訂閱資訊發給leader——注意leader和coordinator不是一個概念。leader負責消費分配方案的制定。
2 Sync,這一步leader開始分配消費方案,即哪個consumer負責消費哪些topic的哪些partition。一旦完成分配,leader會將這個方案封裝進SyncGroup請求中發給coordinator,非leader也會發SyncGroup請求,只是內容為空。coordinator接收到分配方案之後會把方案塞進SyncGroup的response中發給各個consumer。這樣組內的所有成員就都知道自己應該消費哪些分割槽了。
還是拿幾張圖來說明吧,首先是加入組的過程:

值得注意的是, 在coordinator收集到所有成員請求前,它會把已收到請求放入一個叫purgatory(煉獄)的地方。記得國內有篇文章以此來證明kafka開發人員都是很有文藝範的,寫得也是比較有趣,有興趣可以去搜搜。
然後是分發分配方案的過程,即SyncGroup請求:

注意!! consumer group的分割槽分配方案是在客戶端執行的!Kafka將這個權利下放給客戶端主要是因為這樣做可以有更好的靈活性。比如這種機制下我可以實現類似於Hadoop那樣的機架感知(rack-aware)分配方案,即為consumer挑選同一個機架下的分割槽資料,減少網路傳輸的開銷。Kafka預設為你提供了兩種分配策略:range和round-robin。由於這不是本文的重點,這裡就不再詳細展開了,你只需要記住你可以覆蓋consumer的引數:partition.assignment.strategy來實現自己分配策略就好了。
4.10 consumer group狀態機
和很多kafka元件一樣,group也做了個狀態機來表明組狀態的流轉。coordinator根據這個狀態機會對consumer group做不同的處理,如下圖所示(完全是根據程式碼註釋手動畫的,多見諒吧)

簡單說明下圖中的各個狀態:
- Dead:組內已經沒有任何成員的最終狀態,組的元資料也已經被coordinator移除了。這種狀態響應各種請求都是一個response: UNKNOWN_MEMBER_ID
- Empty:組內無成員,但是位移資訊還沒有過期。這種狀態只能響應JoinGroup請求
- PreparingRebalance:組準備開啟新的rebalance,等待成員加入
- AwaitingSync:正在等待leader consumer將分配方案傳給各個成員
- Stable:rebalance完成!可以開始消費了~
至於各個狀態之間的流程條件以及action,這裡就不具體展開了。
三、rebalance場景剖析
上面詳細闡述了consumer group是如何執行rebalance的,可能依然有些雲裡霧裡。這部分對其中的三個重要的場景做詳盡的時序展開,進一步加深對於consumer group內部原理的理解。由於圖比較直觀,所有的描述都將以圖的方式給出,不做過多的文字化描述了。
1 新成員加入組(member join)
2 組成員崩潰(member failure)
前面說過了,組成員崩潰和組成員主動離開是兩個不同的場景。因為在崩潰時成員並不會主動地告知coordinator此事,coordinator有可能需要一個完整的session.timeout週期才能檢測到這種崩潰,這必然會造成consumer的滯後。可以說離開組是主動地發起rebalance;而崩潰則是被動地發起rebalance。okay,直接上圖:

3 組成員主動離組(member leave group)

4 提交位移(member commit offset)

總結一下,本文著重討論了一下新版本的consumer group的內部設計原理,特別是consumer group與coordinator之間的互動過程,希望對各位有所幫助。