
scrapy爬蟲代理——利用crawlera神器,無需再尋找代理IP
阿新 • • 發佈:2019-01-25
一、crawlera平臺註冊
首先申明,註冊是免費的,使用的話除了一些特殊定製外都是free的。
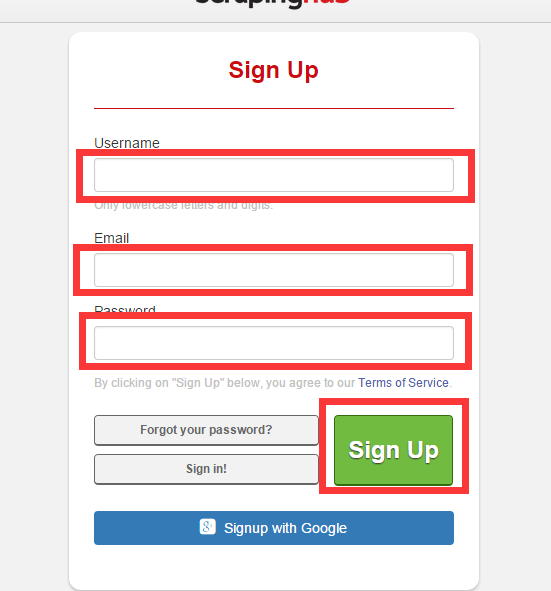
填寫使用者名稱、密碼、郵箱,註冊一個crawlera賬號並激活
2、建立Organizations,然後新增crawlear服務
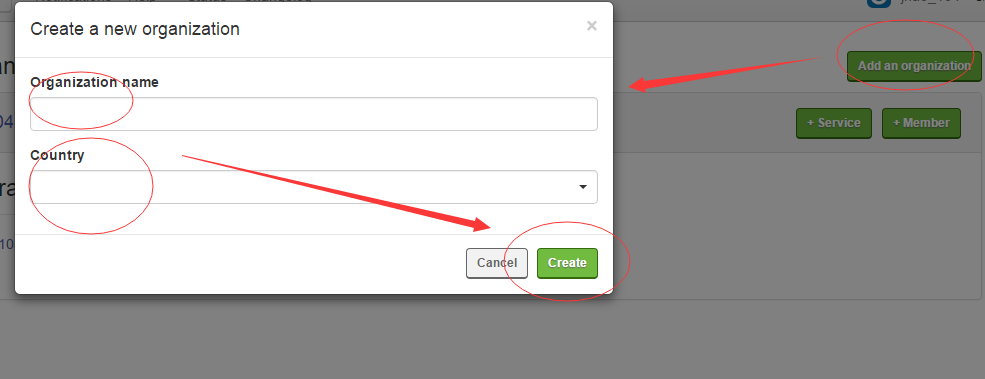
然後點選 +Service ,在彈出的介面點選Crawlear,輸入名字,選擇資訊就建立成功了。
建立成功過後點選你的Crawlear名字便可以看到API的詳細資訊。
二、部署到srcapy專案
1、安裝scarpy-crawlera
pip install 、easy_install 隨便你採用什麼安裝方式都可以
| 1 |
pip install scrapy-crawlera
|
2、修改settings.py
如果你之前設定過代理ip,那麼請註釋掉,加入crawlera的代理
| 1 2 3 4 5 |
DOWNLOADER_MIDDLEWARES = {
# 'scrapy.contrib.downloadermiddleware.httpproxy.HttpProxyMiddleware': 110,
# 'partent.middlewares.ProxyMiddleware': 100,
'scrapy_crawlera.CrawleraMiddleware': 600
}
|
為了是crawlera生效,需要新增你建立的api資訊(如果填寫了API key的話,pass填空字串便可)
| 1 2 3 |
CRAWLERA_ENABLED = True
CRAWLERA_USER = '<API key>'
CRAWLERA_PASS = ''
|
為了達到更高的抓取效率,可以禁用Autothrottle擴充套件和增加併發請求的最大數量,以及設定下載超時,程式碼如下
?| 1 2 3 4 |
CONCURRENT_REQUESTS = 32
CONCURRENT_REQUESTS_PER_DOMAIN = 32
AUTOTHROTTLE_ENABLED = False
DOWNLOAD_TIMEOUT = 600
|
如果在程式碼中設定有 DOWNLOAD_DELAY的話,需要在setting.py中新增
?| 1 |
CRAWLERA_PRESERVE_DELAY = True
|
如果你的spider中保留了cookies,那麼需要在Headr中新增
| 1 2 3 4 5 |
DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
# 'Accept-Language': 'zh-CN,zh;q=0.8',
'X-Crawlera-Cookies': 'disable'
}
|
三、執行爬蟲
這些都設定好了過後便可以執行你的爬蟲了。這時所有的request都是通過crawlera發出的,資訊如下
