
poi實現doc轉html獲取帶樣式內容,並在ueditor中顯示
阿新 • • 發佈:2019-01-25
doc轉html獲取帶樣式內容,並在ueditor中顯示
工具類:
獲取返回的內容,存到資料庫。
package com.wb.core.utils; import org.apache.poi.hwpf.HWPFDocument; import org.apache.poi.hwpf.converter.WordToHtmlConverter; import org.apache.poi.xwpf.converter.xhtml.XHTMLConverter; import org.apache.poi.xwpf.converter.xhtml.XHTMLOptions; import org.apache.poi.xwpf.usermodel.XWPFDocument; import org.w3c.dom.Document; import javax.xml.parsers.DocumentBuilderFactory; import javax.xml.parsers.ParserConfigurationException; import javax.xml.transform.OutputKeys; import javax.xml.transform.Transformer; import javax.xml.transform.TransformerException; import javax.xml.transform.TransformerFactory; import javax.xml.transform.dom.DOMSource; import javax.xml.transform.stream.StreamResult; import java.io.*; public class DocToHtml { public static void main(String argv[]) { try { String content=wordToHtml("D:\\a.doc"); System.out.println(content); String content1=wordToHtml("D:\\b.docx"); System.out.println(content1); } catch (Exception e) { e.printStackTrace(); } } public static String wordToHtml(String filePath) throws Exception{ if(filePath.endsWith(".doc")){ String content=convert2Html(filePath); return content; } if(filePath.endsWith(".docx")){ String content=docxToHtml(filePath); return content; } return null; } //docx轉html //生成html檔案 //輸出html標籤和內容 public static String docxToHtml(String sourceFileName) throws Exception { String htmlPath=sourceFileName.substring(0,sourceFileName.indexOf("."))+".html"; XWPFDocument document = new XWPFDocument(new FileInputStream(sourceFileName)); XHTMLOptions options = XHTMLOptions.create().indent(4); File outFile = new File(htmlPath); outFile.getParentFile().mkdirs(); OutputStream out = new FileOutputStream(outFile); XHTMLConverter.getInstance().convert(document,out, options); ByteArrayOutputStream baos = new ByteArrayOutputStream(); XHTMLConverter.getInstance().convert(document, baos, options); baos.close(); String content =new String(baos.toByteArray()); //替換UEditor無法識別的轉義字元 String htmlContent1=content.replaceAll("“","\"").replaceAll("”","\"").replaceAll("—","-"); return htmlContent1; } //doc 轉 html public static String convert2Html(String fileName) throws TransformerException, IOException, ParserConfigurationException { HWPFDocument wordDocument = new HWPFDocument(new FileInputStream(fileName));//WordToHtmlUtils.loadDoc(new FileInputStream(inputFile)); //相容2007 以上版本 WordToHtmlConverter wordToHtmlConverter = new WordToHtmlConverter( DocumentBuilderFactory.newInstance().newDocumentBuilder() .newDocument()); wordToHtmlConverter.processDocument(wordDocument); //解析html Document htmlDocument = wordToHtmlConverter.getDocument(); ByteArrayOutputStream out = new ByteArrayOutputStream(); DOMSource domSource = new DOMSource(htmlDocument); StreamResult streamResult = new StreamResult(out); TransformerFactory tf = TransformerFactory.newInstance(); Transformer serializer = tf.newTransformer(); serializer.setOutputProperty(OutputKeys.ENCODING, "GB2312"); serializer.setOutputProperty(OutputKeys.INDENT, "yes"); serializer.setOutputProperty(OutputKeys.METHOD, "HTML"); serializer.transform(domSource, streamResult); out.close(); String htmlContent=new String(out.toByteArray()); //替換UEditor無法識別的轉義字元 String htmlContent1=htmlContent.replaceAll("“","\"").replaceAll("”","\"").replaceAll("—","-"); return htmlContent1; } }
1.在ueditor.all.js檔案內搜尋allowDivTransToP,找到如下的程式碼,將true設定為false,即不使用預設的過濾處理,預設是過濾掉html,style的。
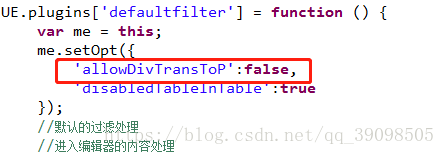
2.在下邊的addInputRule方法中將switch程式碼段中的case style,script都給註釋或者刪掉,防止UEditor將html,<style>轉化成其他標籤。

3.在ueditor.config.js中新增xss的白名單html,head,body,style,不過濾這些標籤,就可以在UEditor上顯示樣式。

注意:如果還是不顯示樣式,看下引入的是不是ueditor.all.js。