
知乎爬蟲之爬取專欄資訊
阿新 • • 發佈:2019-01-24
接著昨天的模擬登陸,今天來爬取一下專欄資訊
我們將對專欄https://zhuanlan.zhihu.com/Entertainmentlaw進行抓取
首先還是進行抓包分析,可以發現這裡有我們想要的專欄的名稱,作者,關注人數等資訊
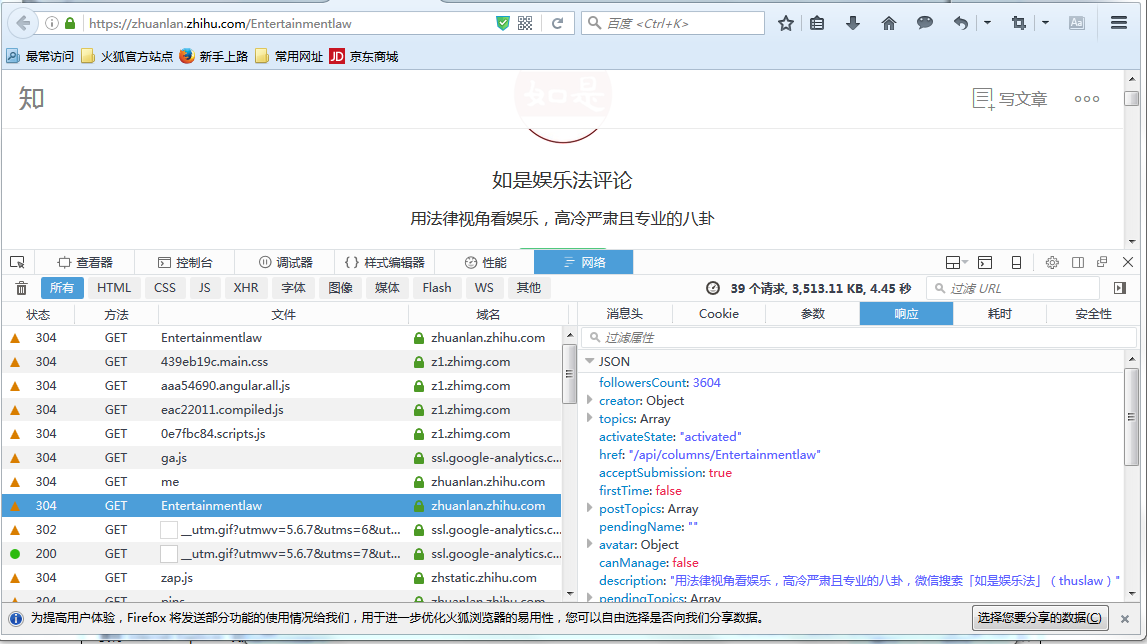
然後我們看一下訊息頭,看一下請求的URL和請求頭
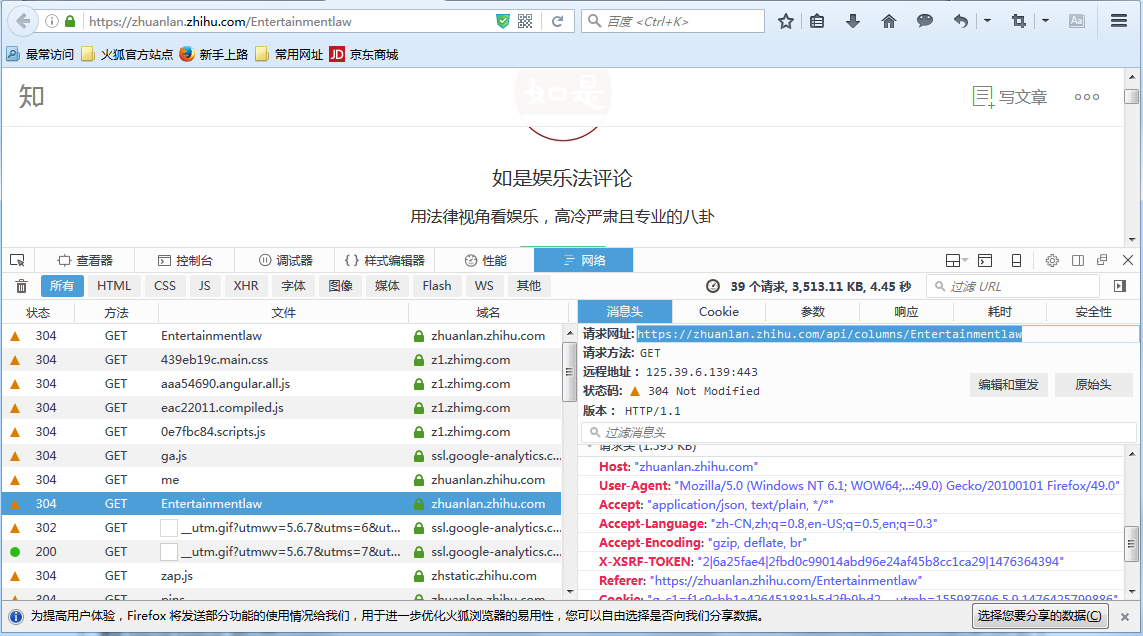
然後就可以編寫程式碼了
# -*- coding:utf-8 -*-
__author__="weikairen"
import requests
from bs4 import BeautifulSoup
import time
BASE_URL='https://www.zhihu.com/' 執行就可以看見結果了
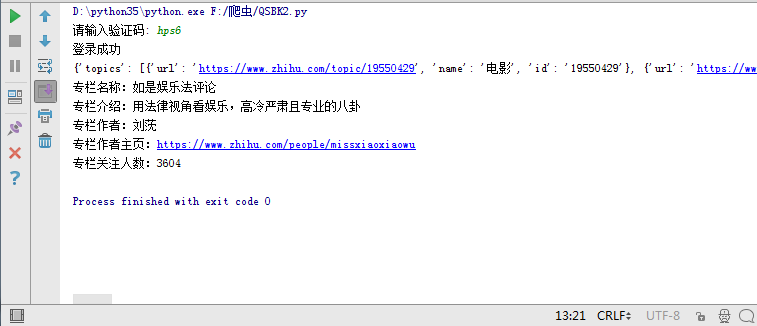
好的,下面我們看一下程式碼,程式碼中帶有註釋
# -*- coding:utf-8 -*-
__author__="weikairen"
import requests
from bs4 import BeautifulSoup
import time
BASE_URL='https://www.zhihu.com/'
LOGIN_URL=BASE_URL+'login/phone_num'
CAPTCHA_URL=BASE_URL+'captcha.gif?r='+str(int(time.time())*1000)+'&type=login'
BLOGS_BASE_URL='https://zhuanlan.zhihu.com/Entertainmentlaw' #專欄地址
BLOGS_API_URL='https://zhuanlan.zhihu.com/api/columns/Entertainmentlaw' #專欄資訊地址,如關注數
BLOGS_URL='https://zhuanlan.zhihu.com/api/columns/Entertainmentlaw/posts?limit=20&offset='#專欄文章的請求構造地址
session = requests.session() #session建立為全域性變數是為了能在不同的函式中使用一個相同的session
#在登入過後 session會儲存伺服器返回的cookie,爬取專欄資訊的時候用這個session,伺服器就會認為你已經登入,就不會拒絕你的請求了
def login():
headers={
'host':'www.zhihu.com',
'user-agent':'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:48.0) Gecko/20100101 Firefox/48.0',
'referer':"https://www.zhihu.com/",
'X - Requested - With': "XMLHttpRequest"
} #構造請求頭,講它偽裝成為瀏覽器
captcha_content=requests.get(CAPTCHA_URL,headers=headers).content
with open('C:\cap.gif','wb') as cap: #將驗證碼圖片下載下來儲存到C盤的根目錄下面
cap.write(captcha_content)
captcha=input('請輸入驗證碼: ')
data={
'_xsrf': "94b6a3f4ba711971716bd8b863d9c91c",
'password': "********",
'captcha_type': "cn",
'remember_me': "true",
'phone_num': "********"
}
response=session.post(LOGIN_URL,data=data,headers=headers)
print(response.json()['msg'])
def blogs():
headers = {
'host': "zhuanlan.zhihu.com",
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64; rv:48.0) Gecko/20100101 Firefox/48.0',
'referer': "https://zhuanlan.zhihu.com/Entertainmentlaw"
}
#session.headers.update(headers)
response = session.get(BLOGS_API_URL,headers=headers).json()
print(response)
print('專欄名稱:'+response['name'])
print('專欄介紹:' + response['intro'])
print('專欄作者:' + response['creator']['name'])
print('專欄作者主頁:' + response['creator']['profileUrl'])
print('專欄關注人數:' + str(response['followersCount']))
blogIndex=0
end=0
while not (end):
response=session.get(BLOGS_URL+str(blogIndex),headers=headers).json()
for blog in response:
#print('文章序號:'+str(blogId))
print('文章名稱:'+blog['title'])
print('文章作者:' + blog['author']['name'])
print('傳送時間:' + blog['publishedTime'])
print('文章連結:' +BLOGS_BASE_URL+ blog['url'])
if len(response)<20:
end=1
blogIndex += 20
login()
blogs()結果如下:
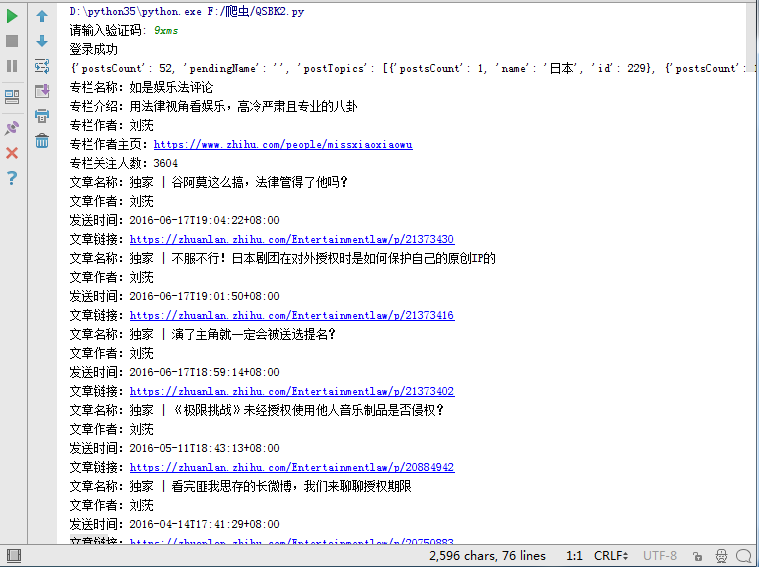
每天進步一點點