
時間序列分析——ARIMA模型預測(R)
讀取資料(
scan() 及read.csv() 等函式,row.names 引數可以用來指定索引列)觀察檢驗時間序列是否平滑,對不平滑的時間序列要進行差分(
diff() 函式),差分的階數=arima(p,d,q) 中d引數的值acf()和 pacf()兩個函式分別檢視時間序列的自相關圖和偏自相關圖,並得出相應的q,p值
模型初步選擇,可以用函式
AIC(arima(objts,order=c(p,d,q),method="ML")) 檢視模型的AIC值初步進行判斷ARIMA模型擬合,呼叫
arima(objts,order=c(p,d,q)) 來擬合數據,可用tsdiag(a1) 對模型進行檢驗。也可用a 來自動進行擬合。rimamodel<−auto.arima(objts,trace=T)預測,呼叫
forecast.Arima(objarima,h=?,level=c(99.5)) 獲得要預測的未來某“長度”內的資料。可以用plot.forecast(objforecast) 檢視預測的序列。殘差檢驗,對預測的殘差進行檢驗,如果殘差是一個白噪聲序列,說明殘差中已經不再含有有用的資訊,模型已經不需要優化了。殘差檢驗可呼叫
Box.test(objforecast$residuals,lag=20,type="Ljung−Box") *統計量為17.4,自由度為20,並且P值是0.6(置信度只有40%)這樣的值不足以拒絕“預測誤差在1-20階是非零自相關,證明預測誤差在1-20階是非零自相關的。*
Ps: p值大,說明為純隨機序列。p值小,非純隨機序列,置信水平(1-p).或者用
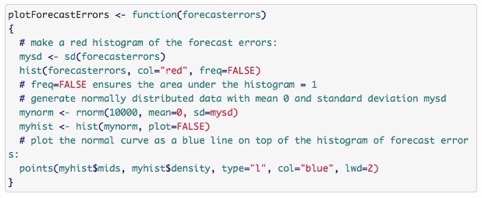
plotForecastErrors(objforecast$residuals) 看預測的殘差是否滿足一個正態分佈,這個函式使用前要先定義:
或者用
acf(objforecast$residuals,lag.max=20) 檢視殘差的自相關圖。
以前沒有接觸過時序分析,為免以後忘記,先粗淺的大概總結了下流程吧,最近因為做題才接觸到這一塊兒,統計方面很多內因都還不太懂,慢慢理解後再行擴充吧。