
負載均衡演算法(1):簡單介紹
負載均衡(Load Balance)是分散式系統架構設計中必須考慮的因素之一,它通常是指,將請求/資料【均勻】分攤到多個操作單元上執行,負載均衡的關鍵在於【均勻】。常見網際網路分散式架構如上,分為客戶端層、反向代理nginx層、站點層、服務層、資料層。
什麼是負載均衡
負載均衡(Load Balance)是分散式系統架構設計中必須考慮的因素之一,它通常是指,將請求/資料【均勻】分攤到多個操作單元上執行,負載均衡的關鍵在於【均勻】。
常見的負載均衡方案
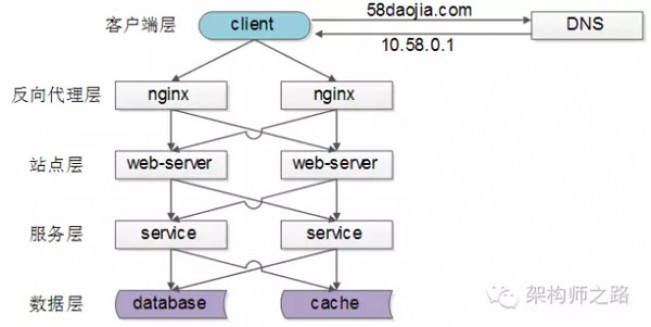
常見網際網路分散式架構如上,分為客戶端層、反向代理nginx層、站點層、服務層、資料層。可以看到,每一個下游都有多個上游呼叫,只需要做到,每一個上游都均勻訪問每一個下游,就能實現“將請求/資料【均勻】分攤到多個操作單元上執行”。
【客戶端層->反向代理層】的負載均衡
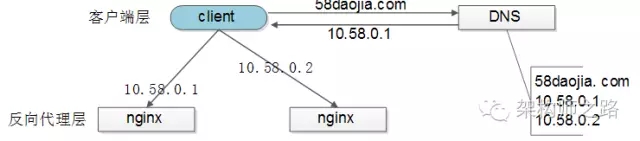
【客戶端層】到【反向代理層】的負載均衡,是通過“DNS輪詢”實現的:DNS-server對於一個域名配置了多個解析ip,每次DNS解析請求來訪問DNS-server,會輪詢返回這些ip,保證每個ip的解析概率是相同的。這些ip就是nginx的外網ip,以做到每臺nginx的請求分配也是均衡的。
【反向代理層->站點層】的負載均衡
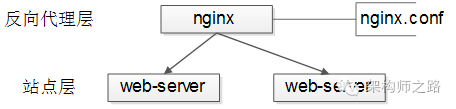
【反向代理層】到【站點層】的負載均衡,是通過“nginx”實現的。通過修改nginx.conf,可以實現多種負載均衡策略:
1)請求輪詢:和DNS輪詢類似,請求依次路由到各個web-server
2)最少連線路由:哪個web-server的連線少,路由到哪個web-server
3)ip雜湊:按照訪問使用者的ip雜湊值來路由web-server,只要使用者的ip分佈是均勻的,請求理論上也是均勻的,ip雜湊均衡方法可以做到,同一個使用者的請求固定落到同一臺web-server上,此策略適合有狀態服務,例如session(58沈劍備註:可以這麼做,但強烈不建議這麼做,站點層無狀態是分散式架構設計的基本原則之一,session最好放到資料層儲存)
4)…
【站點層->服務層】的負載均衡
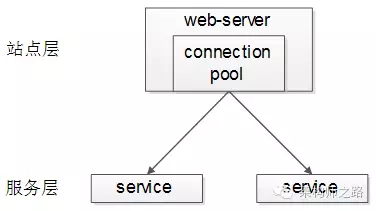
【站點層】到【服務層】的負載均衡,是通過“服務連線池”實現的。
上游連線池會建立與下游服務多個連線,每次請求會“隨機”選取連線來訪問下游服務。
上一篇文章《RPC-client實現細節》中有詳細的負載均衡、故障轉移、超時處理的細節描述,歡迎點選link查閱,此處不再展開。
【資料層】的負載均衡
在資料量很大的情況下,由於資料層(db,cache)涉及資料的水平切分,所以資料層的負載均衡更為複雜一些,它分為“資料的均衡”,與“請求的均衡”。
資料的均衡是指:水平切分後的每個服務(db,cache),資料量是差不多的。
請求的均衡是指:水平切分後的每個服務(db,cache),請求量是差不多的。
業內常見的水平切分方式有這麼幾種:
一、按照range水平切分
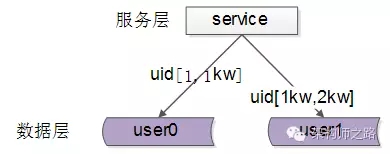
每一個數據服務,儲存一定範圍的資料,上圖為例:
user0服務,儲存uid範圍1-1kw
user1服務,儲存uid範圍1kw-2kw
這個方案的好處是:
(1)規則簡單,service只需判斷一下uid範圍就能路由到對應的儲存服務
(2)資料均衡性較好
(3)比較容易擴充套件,可以隨時加一個uid[2kw,3kw]的資料服務
不足是:
(1)請求的負載不一定均衡,一般來說,新註冊的使用者會比老使用者更活躍,大range的服務請求壓力會更大
二、按照id雜湊水平切分
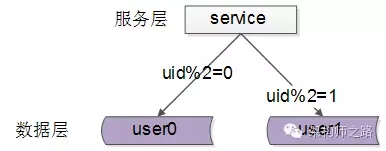
每一個數據服務,儲存某個key值hash後的部分資料,上圖為例:
user0服務,儲存偶數uid資料
user1服務,儲存奇數uid資料
這個方案的好處是:
(1)規則簡單,service只需對uid進行hash能路由到對應的儲存服務
(2)資料均衡性較好
(3)請求均勻性較好
不足是:
(1)不容易擴充套件,擴充套件一個數據服務,hash方法改變時候,可能需要進行資料遷移
總結
負載均衡(Load Balance)是分散式系統架構設計中必須考慮的因素之一,它通常是指,將請求/資料【均勻】分攤到多個操作單元上執行,負載均衡的關鍵在於【均勻】。
(1)【客戶端層】到【反向代理層】的負載均衡,是通過“DNS輪詢”實現的
(2)【反向代理層】到【站點層】的負載均衡,是通過“nginx”實現的
(3)【站點層】到【服務層】的負載均衡,是通過“服務連線池”實現的
(4)【資料層】的負載均衡,要考慮“資料的均衡”與“請求的均衡”兩個點,常見的方式有“按照範圍水平切分”與“hash水平切分”
-------------------------------------------------------------------------------------------------------------------------------------------------------------------------
負載均衡演算法介紹:
輪詢排程
以輪詢的方式依次請求排程不同的伺服器;實現時,一般為伺服器帶上權重;這樣有兩個好處:
- 針對伺服器的效能差異可分配不同的負載;
- 當需要將某個結點剔除時,只需要將其權重設定為0即可;
優點:實現簡單、高效;易水平擴充套件;
缺點:請求到目的結點的不確定,造成其無法適用於有寫的場景(快取,資料庫寫)
應用場景:資料庫或應用服務層中只有讀的場景;
隨機方式
請求隨機分佈到各個結點;在資料足夠大的場景能達到一個均衡分佈;
優點:實現簡單、易水平擴充套件;
缺點:同Round Robin,無法用於有寫的場景;
應用場景:資料庫負載均衡,也是隻有讀的場景;
雜湊:
根據key來計算需要落在的結點上,可以保證一個同一個鍵一定落在相同的伺服器上;
優點:相同key一定落在同一個結點上,這樣就可用於有寫有讀的快取場景;
缺點:在某個結點故障後,會導致雜湊鍵重新分佈,造成命中率大幅度下降;
解決:一致性雜湊 or 使用keepalived保證任何一個結點的高可用性,故障後會有其它結點頂上來;
應用場景:快取,有讀有寫;
一致性雜湊:
在伺服器一個結點出現故障時,受影響的只有這個結點上的key,最大程度的保證命中率;
如twemproxy中的ketama方案;
生產實現中還可以規劃指定子key雜湊,從而保證區域性相似特徵的鍵能分佈在同一個伺服器上;
優點:結點故障後命中率下降有限;
應用場景:快取;
根據鍵的範圍來負載:
根據鍵的範圍來負載,前1億個鍵都存放到第一個伺服器,1~2億在第二個結點;
優點:水平擴充套件容易,儲存不夠用時,加伺服器存放後續新增資料;
缺點:負載不均;資料庫的分佈不均衡;(資料有冷熱區分,一般最近註冊的使用者更加活躍,這樣造成後續的伺服器非常繁忙,而前期的結點空閒很多)
適用場景:資料庫分片負載均衡;
根據鍵對伺服器結點數取模來負載:
根據鍵對伺服器結點數取模來負載;比如有4臺伺服器,key取模為0的落在第一個結點,1落在第二個結點上。
優點:資料冷熱分佈均衡,資料庫結點負載均衡分佈;
缺點:水平擴充套件較難;
適用場景:資料庫分片負載均衡;
純動態結點負載均衡:
根據CPU、IO、網路的處理能力來決策接下來的請求如何排程;
優點:充分利用伺服器的資源,保證個結點上負載處理均衡;
缺點:實現起來複雜,真實使用較少;
不用主動負載均衡:
使用訊息佇列轉為非同步模型,將負載均衡的問題消滅
負載均衡是一種推模型,一直向你發資料,那麼,將所有的使用者請求發到訊息佇列中,所有的下游結點誰空閒,誰上來取資料處理;轉為拉模型之後,訊息了負載的問題;
優點:通過訊息佇列的緩衝,保護後端系統,請求劇增時不會沖垮後端伺服器;
水平擴充套件容易,加入新結點後,直接取queue即可;
缺點:不具有實時性;
應用場景:不需要實時返回的場景;
比如,12036下訂單後,立刻返回提示資訊:您的訂單進去排隊了…等處理完畢後,再非同步通知;