
挖掘演算法中的資料結構(四):堆排序之 二叉堆(Heapify、原地堆排序優化)
不同於前面幾篇O(n^2)或O(n*logn)排序演算法,此篇文章將講解另一個排序演算法——堆排序,也是此係列的第一個資料結構—–堆,需要注意的是在堆結構中排序是次要的,重要的是堆結構及衍生出來的資料結構問題,排序只是堆應用之一。
此篇涉及的知識點有:
- 堆的基本儲存
- Shift Up和Shift Down
- 基礎堆排序和Heapify
- 優化的堆排序
一. 堆結構
1. 優先佇列
首先來了解堆的經典應用—–優先佇列,此概念並不陌生:
- 普通佇列:先進先出,後進後出。關鍵為由時間順序決定出隊順序。
- 優先佇列:出隊順序和入隊順序無關,和優先順序相關。
優先佇列在OS的使用
而優先佇列這種機制在計算機中被大量使用,最典型應用就是作業系統執行任務,它需要同時執行多個任務,而實際上是將CPU執行週期劃分時間片,在時間片中執行一個任務,每一個任務都有優先順序,OS動態選擇優先順序最高的任務執行,所以需要使用優先佇列,所有任務進行優先佇列,由佇列來進行排程需要執行哪個任務。
為什麼使用優先佇列?
注意“動態”的重要性,如果任務是固定的話,可以將這些任務排序好安裝優先順序最高到最低依次執行,可是實際處理確要複雜得多。如下圖:藍色任務處理中心就類似CPU,由它來處理所有請求(紅色代表Request)。選擇執行某個請求後,下一步不是簡單地選擇另一個請求執行,與此同時可能會來新的任務,不僅如此,舊的任務優先順序可能會發生改變,所以將所有任務按優先順序排序再依次執行是不現實的。
所以優先佇列模型不僅適用於OS,更存在與生活中方方面面,例如大家同時請求某個網頁,伺服器端需要依次迴應請求,迴應的順序通常是按照優先佇列決定的。

優先佇列處理“靜態問題”
前面一直在強調優先佇列善於處理“動態”的情況,但其實對於“靜態”也是十分擅長,例如在1,000,000個元素中選出前100名,也就是“在N個元素中選出前M個元素”。
在前三篇博文中學習了排序演算法後,很快得到將所有元素排序,選出前M個元素即可,時間複雜度為O(n*logn)。但是使用了優先佇列,可將時間複雜度降低為O(n *logM)!具體實現涉及到優先佇列實現,後續介紹。
優先佇列主要操作
- 入隊
- 出隊(取出優先順序最高的元素)
優先佇列採用的資料結構:
- 陣列:最簡單的資料結構實現方式,有兩種形式
- 普通陣列:入隊直接插入陣列最後一個位置,而取出優先順序最高的元素需要掃描整個陣列。
- 順序陣列: 維護陣列有序性,入隊時需要遍歷陣列找到合適位置,而出隊時取出隊頭即可。
- 堆:以上兩種實現方式有其侷限性,無法很好平衡出入對操作。而使用堆這種資料結構雖然出入隊時是蠻於前兩者的,但是平均而言維持優先佇列完成系統任務所用時間大大低於使用陣列。
舉個例子,對於總共N個請求:
- 使用普通陣列或者順序陣列,最差情況:O(n^2)
- 使用堆:O(nlgn)

2. 二叉堆(Binary Heap)的基本儲存
因此若要實現優先佇列,必須採用堆資料結構,下面介紹堆有關知識及如何實現。
(1)概念特徵
在以上了解堆中操作都是O(n *logn)級別,應當知道堆相應的是一種樹形結構,其中最為經典的是二叉堆,類似於二叉樹,每一個節點可以有兩個子節點,特點:
- 在二叉樹上任何一個子節點都不大於其父節點。
- 必須是一棵完全的二叉樹,即除了最後一層外,以上層數的節點都必須存在並且狐妖集中在左側。
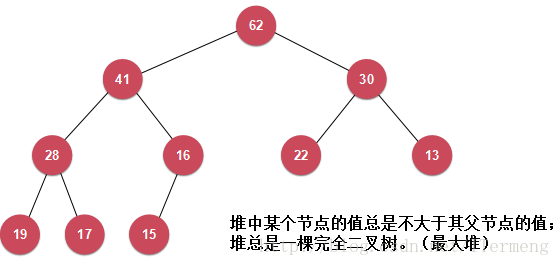
注意:第一個特徵中說明在二叉樹上任何一個子節點都不大於其父節點,並不意味著層數越高節點數越大,這都是相對父節點而言的。例如第三層的19比第二層的16大。
這樣的二叉堆又被稱為“最大堆”,父節點總是比子節點大,同理而言“最小堆”中父節點總是比子節點小,這裡只講解“最大堆”。
(2)結構實現
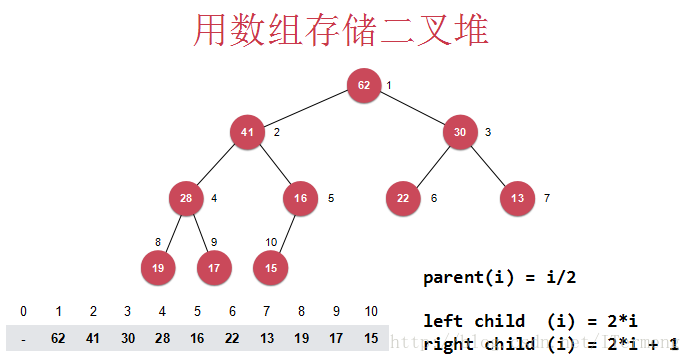
對於其具體實現,熟悉樹形結構的同學可能認為需要兩個指標來實現左、右節點,當然可以這樣實現,但是還有一個經典實現方式——通過陣列實現,正是因為堆是一棵完全的二叉樹。
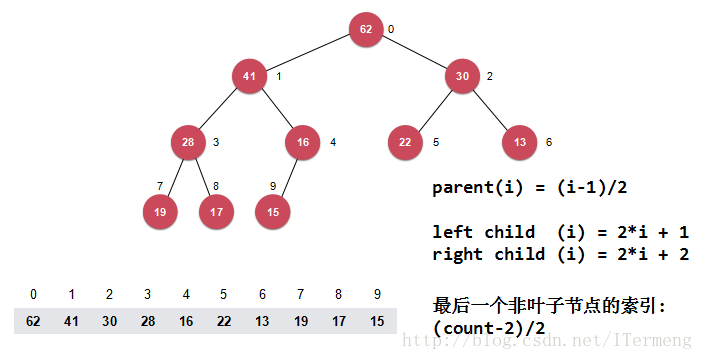
將這棵二叉樹自上到下、自左到右地給每一個節點標上一個序列號,如下圖所示。對於每一個父節點而言:
- 它的左孩子序列號都是本身序列號的 2倍
- 它的右孩子序列號都是本身序列號的 2倍+1
(這裡的根節點下標是由1開始而得出以上規則,但其實由0開始也可得出相應的規則,此部分重點還是放在下標1開始)
(3)基本結構程式碼實現
template<typename Item>
class MaxHeap{
private:
Item *data;
int count;
public:
// 建構函式, 構造一個空堆, 可容納capacity個元素
MaxHeap(int capacity){
data = new Item[capacity+1];
count = 0;
}
~MaxHeap(){
delete[] data;
}
// 返回堆中的元素個數
int size(){
return count;
}
// 返回一個布林值, 表示堆中是否為空
bool isEmpty(){
return count == 0;
}
};
// 測試 MaxHeap
int main() {
MaxHeap<int> maxheap = MaxHeap<int>(100);
cout<<maxheap.size()<<endl;
return 0;
}以上C++程式碼並不複雜,只是簡單實現了最大堆(MaxHeap)的基本結構,定義了data值,因為不知道值的具體型別,通過模板(泛型)結合指標來定義,提供簡單的構造、析構、簡單函式方法。
3. 二叉堆中的 Shift Up 和 Shift Down
在完成程式碼的二叉堆基本結構後,需要實現最重要的兩個操作邏輯,即Shift Up 和 Shift Down。
(1)Shift Up
下面就實現在二叉堆中如何插入一個元素,即優先佇列中“入隊操作”。以下動畫中需要插入元素52,由於二叉堆是用陣列表示,所以相當於在陣列末尾新增一個元素,相當於52是索引值11的元素。
演算法思想
注意!其實整個邏輯思想完全依賴於二叉樹的特徵,因為在二叉堆上任何一個子節點都不大於其父節點,所以需要將新插入的元素挪到合適位置來維護此特徵:
- 首先判斷新加入的元素(先歸到二叉堆中)和其父節點的大小,52比16小,所以交換位置。
- 52被換到一個新位置,再繼續檢視52是否大於其父節點,發現52比41大,繼續交換。
- 再繼續判斷,52比62小,無須挪動位置,插入完成。

程式碼實現
在MaxHeap中新增一個insert方法,傳入新增元素在二叉堆中的下標
//將下標k的新增元素放入到二叉堆中合適位置
void shiftUp(int k){
while( k > 1 && data[k/2] < data[k] ){//邊界&&迴圈與父節點比較
swap( data[k/2], data[k] );
k /= 2;
}
}
// 像最大堆中插入一個新的元素 item
void insert(Item item){
assert( count + 1 <= capacity );
data[count+1] = item;//注意下標是從1開始,所以新增元素插入位置為count+1,並非count
count ++;//數量增加1
shiftUp(count);
}注意:以上程式碼中嚴格需要注意邊界問題,因為在建立MaxHeap已設定好陣列個數MaxHeap<int> maxheap = MaxHeap<int>(100);,所以在上述insert中使用了assert函式來判斷,若超過陣列長度則不插入。其實這裡有另外一種更好的解決方法,就是超過時動態增加陣列長度,由於此篇重點為資料結構,留給各位實現。
測試:
建立一個長度為20的陣列,隨機數字迴圈插入,最後打印出來,結果如下:(測試程式碼不貼上,詳細見原始碼)

(2)Shift Down
上一部分講解了如何從二叉堆中插入一個元素,此部分講解如何取出一個元素,即優先佇列中“出隊操作”。
演算法思想
- 根據二叉堆的特徵,其根節點值最大,所以直接獲取下標1的元素,但是根節點值空缺處理,需要重新整理整個二叉樹。
- 將陣列中最後一個值替補到根節點,count陣列總數量減1。因為在二叉堆上任何一個子節點都不大於其父節點。所以需要調節根節點元素,相應的向下移,不同於Shift Up,它可以向左下移或右下移,這裡採用的標準是跟元素值較大的孩子進行交換:
- 根節點與16與52、30比較,將16和52進行交換。
- 將交換後的16與兩個孩子28、41比較,與41交換。
- 交換後的16此時只有一個孩子15,比其大,無需交換。Shift Down過程完成。

程式碼實現
void shiftDown(int k){
while( 2*k <= count ){
int j = 2*k; // 在此輪迴圈中,data[k]和data[j]交換位置
if( j+1 <= count && data[j+1] > data[j] )
j ++;
// data[j] 是 data[2*k]和data[2*k+1]中的最大值
if( data[k] >= data[j] ) break;
swap( data[k] , data[j] );
k = j;
}
}
// 從最大堆中取出堆頂元素, 即堆中所儲存的最大資料
Item extractMax(){
assert( count > 0 );
Item ret = data[1];
swap( data[1] , data[count] );
count --;
shiftDown(1);
return ret;
}測試
首先設定二叉堆長度為20,使用MaxHeap中的insert方法隨機插入20個元素,再呼叫extractMax方法將資料逐漸取出來,取出來的順序應該是按照從大到小的順序取出來的。
// 測試最大堆
int main() {
MaxHeap<int> maxheap = MaxHeap<int>(100);
srand(time(NULL));
int n = 20; // 隨機生成n個元素放入最大堆中
for( int i = 0 ; i < n ; i ++ ){
maxheap.insert( rand()%100 );
}
int* arr = new int[n];
// 將maxheap中的資料逐漸使用extractMax取出來
// 取出來的順序應該是按照從大到小的順序取出來的
for( int i = 0 ; i < n ; i ++ ){
arr[i] = maxheap.extractMax();
cout<<arr[i]<<" ";
}
cout<<endl;
// 確保arr陣列是從大到小排列的
for( int i = 1 ; i < n ; i ++ )
assert( arr[i-1] >= arr[i] );
delete[] arr;
return 0;
}結果

二. 二叉堆優化
1. Heapify
在學習以上二叉堆實現後,發現它同樣可用於排序,不斷呼叫二叉堆的extractMax方法,即可取出資料。(從大到小的順序)
// heapSort1, 將所有的元素依次新增到堆中, 在將所有元素從堆中依次取出來, 即完成了排序
// 無論是建立堆的過程, 還是從堆中依次取出元素的過程, 時間複雜度均為O(nlogn)
// 整個堆排序的整體時間複雜度為O(nlogn)
template<typename T>
void heapSort1(T arr[], int n){
MaxHeap<T> maxheap = MaxHeap<T>(n);
for( int i = 0 ; i < n ; i ++ )
maxheap.insert(arr[i]);
for( int i = n-1 ; i >= 0 ; i-- )
arr[i] = maxheap.extractMax();
}(1)測試
所以以下將二叉堆和之前所學到的O(n*logn)排序演算法比較測試,分別對
- 無序陣列
- 近乎有序陣列
- 包含大量重複值陣列
以上3組測試用例進行時間比較,結果如下(測試程式碼檢視github原始碼):
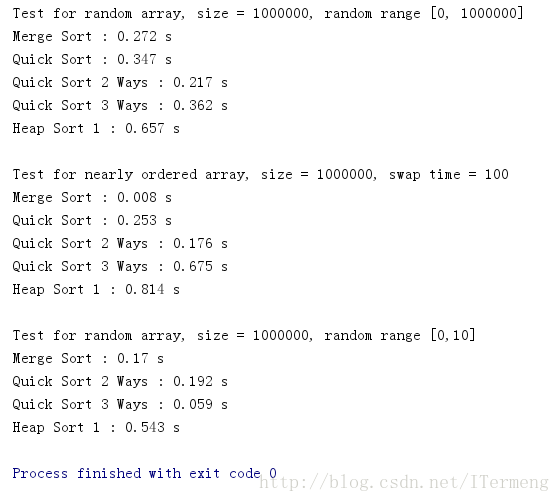
雖然二叉堆排序使用的時間相較於其它排序演算法要慢,但使用時間仍在接收範圍內。因為整個堆排序的整體時間複雜度為O(nlogn) ,無論是建立堆的過程, 還是從堆中依次取出元素的過程, 時間複雜度均為O(nlogn)。總共迴圈n此,每次迴圈二叉樹操作消耗O(logn),所以最後是O(nlogn)。
但是還可以繼續優化,使效能達到更優以上過程建立二叉堆的過程是一個個將元素插入,其實還有更好的方式——Heapify。
(2)Heapify演算法思想
給定一個數組,使這個陣列形成堆的形狀,此過程名為Heapify。例如以下陣列{15,17,19,13,22,16,28,30,41,62}:
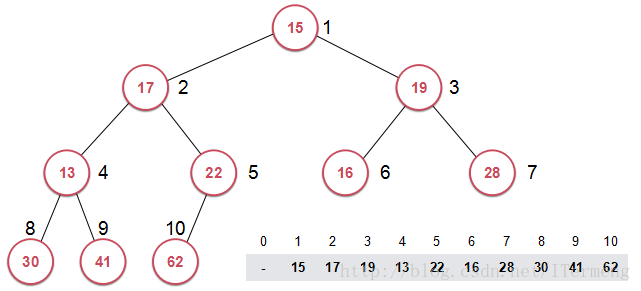
此陣列形成的二叉樹並非最大堆,不滿足特徵。但是上圖中的葉子節點,即最後一層的每個節點可看作是一個最大堆(因為只有它一個節點)。接著再向上遞進一層:
- 由最後一個節點開始,考察父節點22是否大於孩子62,不滿足則交換位置。這樣這兩個節點組成的子樹滿足最大堆特徵。
- 再考慮父節點13是否大於孩子30、41,不滿足則與最大值的孩子交換位置。
- 依次類推,其實思想與Shift Down相似。

(3)程式碼實現
所以,此堆排序的優化就是修改其建立方法,不通過一個一個元素插入來建立二叉堆,而是通過Heapify方法來完成建立,此過程消耗的時間複雜度為O(n),效能更優。
需要修改MaxHeap中的建構函式,傳入引數為無序的陣列和陣列長度,首先開闢空間,下標從1開始將陣列元素值賦值到新陣列中,再結合Shift Down方法層層遞進。
// 建構函式, 通過一個給定陣列建立一個最大堆
// 該構造堆的過程, 時間複雜度為O(n)
MaxHeap(Item arr[], int n){
data = new Item[n+1];
capacity = n;
for( int i = 0 ; i < n ; i ++ )
data[i+1] = arr[i];
count = n;
for( int i = count/2 ; i >= 1 ; i -- )
shiftDown(i);
}
template<typename T>
void heapSort2(T arr[], int n){
//優化後的建立二叉堆建構函式
MaxHeap<T> maxheap = MaxHeap<T>(arr,n);
for( int i = n-1 ; i >= 0 ; i-- )
arr[i] = maxheap.extractMax();
}(4)測試
通過優化後的建立二叉堆建構函式再次測試,結果如下:

可明顯看出優化建立二叉堆建構函式後,堆排序使用時間更少
結論
將n個元素逐個插入到一個空堆中,演算法複雜度是O(nlogn),而使用Heapify的過程,演算法複雜度為O(n)
2. 原地堆排序
不同於其他排序演算法,在堆排序中需要將陣列元素放入“堆”中,需要開闢新的陣列,相當於開了額外的O(n)空間,其實可以繼續優化不適用空間原地對元素進行排序。
引出第二個優化 —— 原地堆排序,事實上,按照堆排序的思想,可以原地進行排序,不需要任何額外空間。
演算法思想
其思想也很簡單,通過之前構造堆這個類的過程已知一個數組可以看成是佇列。因此將一個數組構造“最大堆”:
- 其第一個元素v就是根節點(最大值),在具體排序過程中最大值應在末尾位置w,將兩個值互換位置,此時最大值v在陣列末尾。
- 那麼此時包含w在內的橘黃色部分就不是最大堆了,將w位置的值進行Shift Down操作。
- 橘黃色部分再次成為“最大堆”,最大值仍在第一個位置,那堆末尾的元素(即倒數第二個位置)與第一個元素交換位置,再進行Shift Down操作。
- 依次類推

這樣所有的元素逐漸排序好,直到整個陣列都變成藍色。使用的空間複雜度是O(1),但是這裡需要注意的是,如此一來下標是從0開始並非1,所以規則需要進行相應的調整:
程式碼實現
// 優化的shiftDown過程, 使用賦值的方式取代不斷的swap,
// 該優化思想和我們之前對插入排序進行優化的思路是一致的
template<typename T>
void __shiftDown2(T arr[], int n, int k){
T e = arr[k];
while( 2*k+1 < n ){
int j = 2*k+1;
if( j+1 < n && arr[j+1] > arr[j] )
j += 1;
if( e >= arr[j] ) break;
arr[k] = arr[j];
k = j;
}
arr[k] = e;
}
// 不使用一個額外的最大堆, 直接在原陣列上進行原地的堆排序
template<typename T>
void heapSort(T arr[], int n){
// 注意,此時我們的堆是從0開始索引的
// 從(最後一個元素的索引-1)/2開始
// 最後一個元素的索引 = n-1
for( int i = (n-1-1)/2 ; i >= 0 ; i -- )
__shiftDown2(arr, n, i);
for( int i = n-1; i > 0 ; i-- ){
swap( arr[0] , arr[i] );
__shiftDown2(arr, i, 0);
}
}測試:
分別測試原始Shift Down堆排序 和 Heapify堆排序 和 原地堆排序的時間消耗。

從結構得知優化後的原地堆排序快於之前原始Shift Down堆排序和Heapify堆排序,因為新的演算法不需要額外的空間,也不需要對這些空間賦值,所以效能有所提高。
前三篇博文介紹的排序演算法及以上講解完的堆排序完成,意味著有關排序演算法已講解完畢,下面篇博文對這些排序演算法進行比較總結,並且學習另一個經典的堆結構,處於二叉堆優化之上的索引堆。
若有錯誤,虛心指教~
相關推薦
挖掘演算法中的資料結構(四):堆排序之 二叉堆(Heapify、原地堆排序優化)
不同於前面幾篇O(n^2)或O(n*logn)排序演算法,此篇文章將講解另一個排序演算法——堆排序,也是此係列的第一個資料結構—–堆,需要注意的是在堆結構中排序是次要的,重要的是堆結構及衍生出來的資料結構問題,排序只是堆應用之一。 此篇涉及的知識點有: 堆
資料結構實現 10.2:對映_基於AVL樹實現(C++版)
資料結構實現 10.2:對映_基於AVL樹實現(C++版) 1. 概念及基本框架 2. 基本操作程式實現 2.1 增加操作 2.2 刪除操作 2.3 修改操作 2.4 查詢操作 2.5 其他操作 3.
資料結構實現 5.2:對映_基於連結串列實現(C++版)
資料結構實現 5.2:對映_基於連結串列實現(C++版) 1. 概念及基本框架 2. 基本操作程式實現 2.1 增加操作 2.2 刪除操作 2.3 修改操作 2.4 查詢操作 2.5 其他操作 3. 演
資料結構實現 4.2:集合_基於連結串列實現(C++版)
資料結構實現 4.2:集合_基於連結串列實現(C++版) 1. 概念及基本框架 2. 基本操作程式實現 2.1 增加操作 2.2 刪除操作 2.3 查詢操作 2.4 其他操作 3. 演算法複雜度分析
浙大版《資料結構》習題4.5 順序儲存的二叉樹的最近的公共祖先問題 (25 分)
設順序儲存的二叉樹中有編號為i和j的兩個結點,請設計演算法求出它們最近的公共祖先結點的編號和值。 輸入格式: 輸入第1行給出正整數n(≤1000),即順序儲存的最大容量;第2行給出n個非負整數,其間以空格分隔。其中0代表二叉樹中的空結點(如果第1個結點為0,則
資料結構(C語言實現):判斷兩棵二叉樹是否相等,bug求解
判斷兩棵二叉樹是否相等。 遇到了bug,求大神幫忙!!! C語言原始碼: #include <stdio.h> #include <stdlib.h> #include <malloc.h> #define OK 1 #define
Ikaros的資料結構之二叉樹(基礎概念部分)
二叉樹(Binary Tree) 在瞭解二叉樹之前你需要了解如下內容: 1.樹(Tree):是一種非線性資料結構(非線性資料結構包含樹和圖) ①樹的資料結構: 相關術語 a.根節點(root):樹中沒有前驅的結點 注:一棵樹中只有一個根節點 b.葉子結點(le
資料結構學習之二叉樹(面試易考題整理)
【摘要】電腦科學中,二叉樹是每個節點最多有兩個子樹的樹結構。通常子樹被稱作“左子樹”(left subtree)和“右子樹”(right subtree)。二叉樹常被用於實現二叉查詢樹和二叉堆。二叉樹是遞迴定義的,因此,與二叉樹有關的題目基本都可以用遞迴思想解決
Python資料結構之二叉樹(涵蓋了構建、刪除、查詢、字典轉換、非遞迴與遞迴遍歷等)
MyTree.py #coding=utf-8 import math class BinTree: def __init__(self): self.root=None def is_empty(self):
數據結構之二叉樹(二)
創建 int iter out for 結點 spa left nbsp 輸出二叉樹中所有從根結點到葉子結點的路徑 1 #include <iostream> 2 #include <vector> 3 us
數據結構之二叉樹(一)
reorder system style 序列 urn creat 編寫程序 space ont 設計和編寫程序,按照輸入的遍歷要求(即先序、中序和後序)完成對二叉樹的遍歷,並輸出相應遍歷條件下的樹結點序列。 1 //遞歸實現 2 #include
玩轉資料結構——第四章:連結串列和遞迴
內容概要: Leetcode中和連結串列相關的問題 測試自己的Leetcode連結串列程式碼 遞迴繼承與遞迴的巨集觀語意 連結串列的天然遞迴結構性質 遞迴執行機制:遞迴的微觀解讀 遞迴演算法的除錯 更多和連結串列相關的問題 1-Leetcode中
資料結構與演算法之二叉搜尋樹插入、查詢與刪除
1 二叉搜尋樹(BSTree)的概念 二叉搜尋樹又被稱為二叉排序樹,那麼它本身也是一棵二叉樹,那麼滿足以下性質的二叉樹就是二叉搜尋樹,如圖: 若左子樹不為空,則左子樹上所有節點的值都小於根節點的值; 若它的右子樹不為空,則它的右子樹上所有節點的值都大於
Spark2.2+ES6.4.2(三十二):ES API之ndex的create(建立index時設定setting,並建立index後根據avro模板動態設定index的mapping)/update/delete/open/close
要想通過ES API對es的操作,必須獲取到TransportClient物件,讓後根據TransportClient獲取到IndicesAdminClient物件後,方可以根據IndicesAdminClient物件提供的方法對ES的index進行操作:create index,update inde
Spark2.2+ES6.4.2(三十二):ES API之ndex的create(創建index時設置setting,並創建index後根據avro模板動態設置index的mapping)/update/delete/open/close
pre hdfs -- 行操作 模板 del class max pen 要想通過ES API對es的操作,必須獲取到TransportClient對象,讓後根據TransportClient獲取到IndicesAdminClient對象後,方可以根據IndicesAd
資料結構之二叉樹(遍歷、建立、深度)
1、二叉樹的深度遍歷 二叉樹的遍歷是指從根結點出發,按照某種次序依次訪問二叉樹的所有結點,使得每個結點被訪問一次且僅被訪問一次。訪問和次序。 對於二叉樹的深度遍歷,有前
資料結構 《4》---- 一個漂亮的列印二叉樹的程式
寫二叉樹的程式時經常會遇到希望漂亮地把二叉樹給輸出,本文給出了一個小程式。 以下時列印的效果: // copyright @ L.J.SHOU Jan.16, 2014 // a fancy binary tree printer #ifndef BINARY_TREE_
【資料結構學習筆記】——根據中綴表示式構建二叉樹並輸出
要求 輸入一箇中綴表示式,構造表示式樹,以文字方式輸出樹結構。 輸入:例如,輸入a+b+c*(d+e) 輸出:以縮排表示二叉樹的層次,左(根),右(葉),上(右子樹),下(左子樹) 分析 我們有兩個核心的問題需要解決,一是如何按照中綴表示式來
資料結構與演算法隨筆之------二叉樹的遍歷(一文搞懂二叉樹的四種遍歷)
二叉樹的遍歷 二叉樹的遍歷(traversing binary tree)是指從根結點出發,按照某種次序依次訪問二叉樹中所有的結點,使得每個結點被訪問依次且僅被訪問一次。 遍歷分為四種,前序遍歷,中序遍歷,後序遍歷及層序遍歷 前序 中
資料結構實驗之二叉樹四:(先序中序)還原二叉樹 (SDUT 3343)
#include <bits/stdc++.h> using namespace std; struct node { char data; struct node *lc, *rc; }; char a[100],b[100]; int n; struct node