
《機器學習實戰》第二章 2.2用k-近鄰演算法改進約會網站的配對效果
《機器學習實戰》系列部落格主要是實現並理解書中的程式碼,相當於讀書筆記了。畢竟實戰不能光看書。動手就能遇到許多奇奇怪怪的問題。博文比較粗糙,需結合書本。博主邊查邊學,水平有限,有問題的地方評論區請多指教。書中的程式碼和資料,網上有很多請自行下載。
KNN演算法的應用
2.2.1 從文字檔案中解析資料
函式的輸入為檔名字串,輸出為訓練樣本矩陣和類標籤向量。
解析程式
def file2matrix(filename):
fr = open(filename)
numberOfLines = len(fr.readlines()) #get the number of lines in the file 匯入資料成功,檢查一下資料
>>> import kNN
>>> datingDataMat,datingLabels = kNN.file2matrix('datingTestSet2.txt')
>>> datingDataMat
array([[ 4.09200000e+04, 8.32697600e+00, 9.53952000e-01],
[ 1.44880000e+04, 7.15346900e+00, 1.67390400e+00],
[ 2.60520000e+04, 1.44187100e+00, 8.05124000e-01],
...,
[ 2.65750000e+04, 1.06501020e+01, 8.66627000e-01],
[ 4.81110000e+04, 9.13452800e+00, 7.28045000e-01],
[ 4.37570000e+04, 7.88260100e+00, 1.33244600e+00]] 相關函式學習
- open 函式
語法:open(name[, mode[, buffering]]) r:讀操作;w:寫操作;a:新增操作;b:二進位制存取操作 如果預設就是r
例如:在C:\Users\lzw\Desktop\python 目錄下新建一個txt檔案 test_open.txt
命令列輸入,就可以開啟這個檔案
>>> f=open('C:\\Users\\lzw\\Desktop\\python\\test_open.txt','r+') # "\" 是轉義符,要將他再轉義
>>> 如果是不加路徑,只有一個檔名:f = open (‘test_open.txt’) 則必須保證!!! test_open.txt儲存在我們的工作目錄中
寫檔案操作
>>> f = open('test_open.txt', 'w')
>>> f.write('hello,')
>>> f.write('python\n')
>>> f.write('this is a test\n')
>>> f.write('lzw\n')
>>> f.close()
>>> 開啟 test_open.txt,可以看到原來空的txt 寫入了內容
讀檔案操作
>>> f = open('test_open.txt')
>>> f.read(1)
'h'
>>> f.read(5)
'ello,'
>>> f.read()
'python\nthis is a test\nlzw\n'readlines 逐行讀取
>>> f = open('test_open.txt')
>>> f.readlines()
['hello,python\n', 'this is a test\n', 'lzw\n']
>>> - zeros 函式
>>> from numpy import*
>>> zeros(3)
array([ 0., 0., 0.])
>>> zeros((2,3))
array([[ 0., 0., 0.],
[ 0., 0., 0.]])
>>> zeros([2,3]) #和上一種一樣
array([[ 0., 0., 0.],
[ 0., 0., 0.]])
>>> zeros(3,int16) #預設的是float型
array([0, 0, 0], dtype=int16)
>>> a=array([[2,3],[3,4]])
>>> zeros_like(a) #返回和輸入大小相同,型別相同,用0填滿的陣列
array([[0, 0],
[0, 0]])- strip 函式 刪除頭尾字串函式
>>> a = ' \n123\tabc\r'
>>> a.strip() #刪除頭尾的字串,預設為空白符(包括'\n', '\r', '\t', ' ')
'123\tabc'
>>> a.lstrip() #刪除開頭
'123\tabc\r'
>>> a.rstrip() #刪除結尾
' \n123\tabc'
>>> a.strip('12')
' \n123\tabc\r'
>>> a = '12abc'
>>> a.strip('12')#刪除字串12
'abc'
>>> • split 函式拆分字串。通過指定分隔符對字串進行切片
>>> u = "www.doiido.com.cn"
>>> print u.split() #使用預設分隔符
['www.doiido.com.cn']
>>> print u.split('.') #以"."為分隔符
['www', 'doiido', 'com', 'cn']
>>> print u.split('.',1) #分割一次
['www', 'doiido.com.cn']
>>> print u.split('.',2) #分割兩次
['www', 'doiido', 'com.cn']
>>> print u.split('.',2)[1] #分割兩次,並取序列為1的項
doiido
>>> u1,u2,u3 = u.split('.',2)#分割兩次,並把分割後的三個部分儲存到三個檔案
>>> print u1
www
>>> print u2
doiido
>>> print u3
com.cn
2.2.2使用Matplotlib畫散點圖
kNN .py 程式裡繼續寫,注意要import Matplotlib
散點圖程式
datingDataMat,datingLabels = file2matrix('datingTestSet2.txt')
fig = plt.figure()
ax = fig.add_subplot(111)
ax.scatter(datingDataMat[:,1],datingDataMat[:,2],15.0*array(datingLabels),15.0*array(datingLabels))
plt.show()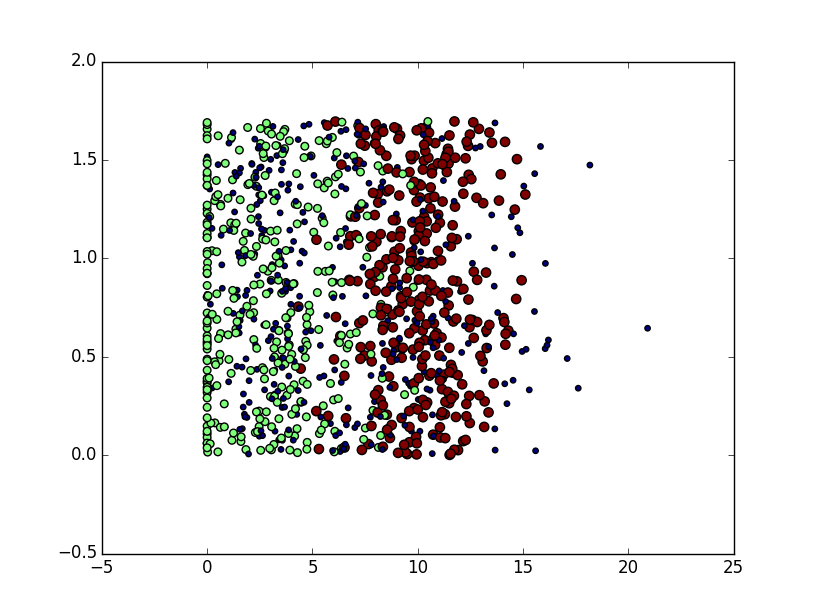
相關函式學習
fig = plt.figure() #繪製一個figure物件
ax = fig.add_subplot(223) #將畫布分割成2行2列,影象畫在從左到右從上到下的第3塊
scatter 畫散點圖
2.2.3歸一化數值
newValue = (oldValue-min)/(max-min)
歸一化程式
def autoNorm(dataSet):
minVals = dataSet.min(0) #每一列最小值
maxVals = dataSet.max(0)
ranges = maxVals - minVals
normDataSet = zeros(shape(dataSet)) #返回矩陣大小和資料矩陣一樣用0填充
m = dataSet.shape[0] #矩陣行數
normDataSet = dataSet - tile(minVals, (m,1))
normDataSet = normDataSet/tile(ranges, (m,1)) #element wise divide
return normDataSet, ranges, minVals
>>> normMat
array([[ 0.44832535, 0.39805139, 0.56233353],
[ 0.15873259, 0.34195467, 0.98724416],
[ 0.28542943, 0.06892523, 0.47449629],
...,
[ 0.29115949, 0.50910294, 0.51079493],
[ 0.52711097, 0.43665451, 0.4290048 ],
[ 0.47940793, 0.3768091 , 0.78571804]])
>>> ranges
array([ 9.12730000e+04, 2.09193490e+01, 1.69436100e+00])
>>> minVals
array([ 0. , 0. , 0.001156])
>>> 2.2.4測試演算法:用錯誤率來檢測分類器的效能
分離器效能測試程式
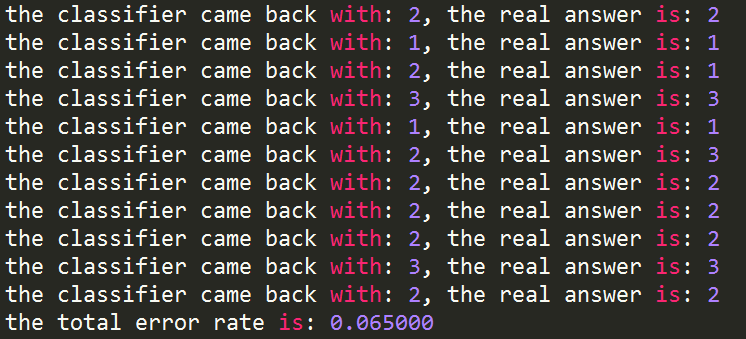
def datingClassTest():
hoRatio = 0.10 #選擇10%資料作測試
datingDataMat,datingLabels = file2matrix('datingTestSet2.txt')
normMat, ranges, minVals = autoNorm(datingDataMat)
m = normMat.shape[0]
numTestVecs = int(m*hoRatio)
errorCount = 0.0
for i in range(numTestVecs):
classifierResult = classify0(normMat[i,:],normMat[numTestVecs:m,:],datingLabels[numTestVecs:m],3)
print "the classifier came back with: %d, the real answer is: %d" % (classifierResult, datingLabels[i])
if (classifierResult != datingLabels[i]): errorCount += 1.0
print "the total error rate is: %f" % (errorCount/float(numTestVecs))
print errorCount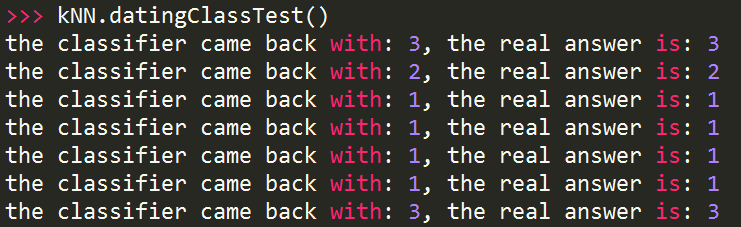
…
2.2.5構建完整可用的系統
預測程式
def classifyPerson():
resultList = ['不喜歡','魅力一般的人','極具魅力的人']
percentTats = float(raw_input("percentgage of time spent playing video game ?"))
ffMile = float(raw_input("frequent flier miles earned per year ?"))
iceCream = float(raw_input("liters of ice Cream consumed per year ?"))
datingDataMat ,datingLabels = file2matrix('datingTestSet2.txt')
normMat ,ranges ,minVals = autoNorm (datingDataMat)
inArr = array([ffMile,percentTats,iceCream])
classifierResult = classify0((inArr - minVals)/ranges, normMat,datingLabels,3)
print "You will probably like this person: ",resultList[classifierResult-1]>>> reload(kNN)
<module 'kNN' from 'kNN.py'>
>>> kNN.classifyPerson()
percentgage of time spent playing video game ? 10
frequent flier miles earned per year ?10000
liters of ice Cream consumed per year ?0.5
You will probably like this person: 魅力一般的人
>>> 相關函式學習
raw_input() 將所有輸入作為字串看待,返回字串型別
相關推薦
《機器學習實戰》第二章 2.2用k-近鄰演算法改進約會網站的配對效果
《機器學習實戰》系列部落格主要是實現並理解書中的程式碼,相當於讀書筆記了。畢竟實戰不能光看書。動手就能遇到許多奇奇怪怪的問題。博文比較粗糙,需結合書本。博主邊查邊學,水平有限,有問題的地方評論區請多指教。書中的程式碼和資料,網上有很多請自行下載。 KNN演算法
機器學習實戰筆記2:使用K-近鄰演算法改進約會網站的配對效果
一 背景 在學習了上一節簡單的k-近鄰演算法實現後,這一篇文章講一下書中給出的一個例子,在約會網站上使用k-近鄰演算法: 1)收集資料:可以使用爬蟲進行資料的收集,也可以使用第三方提供的免費或收費的資料。一般來講,資料放在txt文字檔案中,按照一定的格式進行
機器學習實戰(第二篇)-k-近鄰演算法改進約會網站配對結果
前面幾篇中,我們學習了機器學習演算法中k-近鄰演算法,本章我們將使用該演算法進行改進約會網站配對結果的工作。首先我們先進入背景介紹: 我的朋友海倫一直使用線上約會網站尋找適合自己的約會物件。儘管約會網站會推薦不同的人選,但她沒有從中找到喜歡的人。經過一番總
《機器學習實戰》第2章閱讀筆記3 使用K近鄰演算法改進約會網站的配對效果—分步驟詳細講解1——資料準備:從文字檔案中解析資料(附詳細程式碼及註釋)
本篇使用的資料存放在文字檔案datingTestSet2.txt中,每個樣本資料佔據一行,總共有1000行。 樣本主要包含以下3中特徵: (1)每年獲得飛行常客里程數 (2)玩視訊遊戲所耗時間百分比 (3)每週消費的冰淇淋公升數 在使用分類器之前,需要將處理的檔案格式
機器學習實戰——KNN演算法改進約會網站配對效果
背景: 將約會網站的人分為三種類型:不喜歡的,魅力一般的,極具魅力的,分別用數字1,2,3表示,這些是樣本的標籤。樣本特徵為,每年飛行里程,玩視訊遊戲佔百分比,每週消費冰淇淋公升數。 &
【機器學習實戰之一】:C++實現K-近鄰演算法KNN
本文不對KNN演算法做過多的理論上的解釋,主要是針對問題,進行演算法的設計和程式碼的註解。 KNN演算法: 優點:精度高、對異常值不敏感、無資料輸入假定。 缺點:計算複雜度高、空間複雜度高。 適用資料範圍:數值型和標稱性。 工作原理:存在一個樣本資料集合,也稱作訓練樣本集,
機器學習—使用k-近鄰演算法改進約會網站的配對效果
沒寫完先發出去,後面會修改QAQ python中zeros函式的用法 用於建立矩陣 將文字記錄轉化為numpy的解析程式 def file2matrix(filename): fr=open(filename) arrayOLines
使用k-近鄰演算法改進約會網站的配對效果--學習筆記(python3版本)
本文取自《機器學習實戰》第二章,原始為python2實現,現將程式碼移植到python3,且原始程式碼非常整潔,所以這本書的程式碼很值得學習一下。 k-近鄰演算法概述 工作原理:存在一個樣本資料集合,也稱作訓練樣本集,並且樣本集中每個資料都存在標籤,即我們知道樣本集中
學習筆記:使用k-近鄰演算法改進約會網站的配對效果
# name="code" class="python"># -*- coding: UTF-8 -*- from numpy import * import operator import matplotlib.pyplot as plt def file2mat
機器學習實戰第二章----KNN
BE 指定 cto 文件轉換 .sh ati subplot OS umt tile的使用方法 tile(A,n)的功能是把A數組重復n次(可以在列方向,也可以在行方向) argsort()函數 argsort()函數返回的是數組中值從大到小的索引值 dict.get()
機器學習實戰-第二章代碼+註釋-KNN
rep sdn odi als cti 元素 集合 pre recv #-*- coding:utf-8 -*- #https://blog.csdn.net/fenfenmiao/article/details/52165472 from numpy import *
機器學習實戰第二章——學習KNN演算法,讀書筆記
K近鄰演算法(簡稱KNN)學習是一種常用的監督學習方法,給定測試樣本,基於某種距離度量找出訓練集中與其最靠近的k個訓練樣本,然後基於這k個“鄰居”的資訊來進行預測。通常在分類任務中可以使用“投票法”,即
機器學習實戰 第二章KNN(1)python程式碼及註釋
#coding=utf8 #KNN.py from numpy import * import operator def createDataSet(): group=array([[1.0,1.1],[1.0,1.0],[0,0],[0,0.1]]) #我覺
機器學習實戰第二章記錄
第二章講的是K-鄰近演算法from numpy import*import operatordef createDataSet(): group = array([[1.0,1.1],[1.0,1.0],[0,0],[0,0.1]]) labels = ['A',
機器學習實戰筆記一:K-近鄰演算法在約會網站上的應用
K-近鄰演算法概述 簡單的說,K-近鄰演算法採用不同特徵值之間的距離方法進行分類 K-近鄰演算法 優點:精度高、對異常值不敏感、無資料輸入假定。 缺點:計算複雜度高、空間複雜度高。 適用範圍:數值型和標稱型。 k-近鄰演算法的一般流程 收集資料:可使用任何方法
機器學習實戰之使用k-鄰近演算法改進約會網站的配對效果
1 準備資料,從文字檔案中解析資料 用到的資料是機器學習實戰書中datingTextSet2.txt 程式碼如下: from numpy import * def file2matrix(filname): fr=open(filname) arrayOLines
Python3 機器學習實戰自我講解(二) K-近鄰法-海倫約會-手寫字型識別
第二章 k近鄰法 2.1 概念 2.1.1 k近鄰法簡介 k近鄰法(k-nearest neighbor, k-NN)是1967年由Cover T和Hart P提出的一種基本分類與迴歸方法。它的工作原理是:存在一個樣本資料集合,也稱作為訓練樣
機器學習實戰ByMatlab(四)二分K-means演算法
前面我們在是實現K-means演算法的時候,提到了它本身存在的缺陷: 1.可能收斂到區域性最小值 2.在大規模資料集上收斂較慢 對於上一篇博文最後說的,當陷入區域性最小值的時候,處理方法就是多執行幾次K-means演算法,然後選擇畸變函式J
機器學習實踐(七)—sklearn之K-近鄰演算法
一、K-近鄰演算法(KNN)原理 K Nearest Neighbor演算法又叫KNN演算法,這個演算法是機器學習裡面一個比較經典的演算法, 總體來說KNN演算法是相對比較容易理解的演算法 定義 如果一個樣本在特徵空間中的k個最相似(即特徵空間中最鄰近)的樣本中的
2、K-近鄰演算法之約會網站預測
k-近鄰演算法概述 定義:簡單地說,k近鄰演算法採用測量不同特徵值之間的距離進行分類 原理:存在一個樣本資料集合,也稱作訓練樣本集,並且樣本集中每個資料都存在標籤,即我們知道樣本集中每一資