
從重取樣到資料合成:如何處理機器學習中的不平衡分類問題?
轉自:http://www.sohu.com/a/129333346_465975
選自Analytics Vidhya
作者:Upasana Mukherjee
機器之心編譯
參與:馬亞雄、微胖、黃小天、吳攀
如果你研究過一點機器學習和資料科學,你肯定遇到過不平衡的類分佈(imbalanced class distribution)。這種情況是指:屬於某一類別的觀測樣本的數量顯著少於其它類別。
這個問題在異常檢測是至關重要的的場景中很明顯,例如電力盜竊、銀行的欺詐交易、罕見疾病識別等。在這種情況下,利用傳統機器學習演算法開發出的預測模型可能會存在偏差和不準確。
發生這種情況的原因是機器學習演算法通常被設計成通過減少誤差來提高準確率。所以它們並沒有考慮類別的分佈/比例或者是類別的平衡。
這篇指南描述了使用多種取樣技術來解決這種類別不平衡問題的各種方法。本文還比較了每種技術的優缺點。最後,本文作者還向我們展示了一種讓你可以建立一個平衡的類分佈的方法,讓你可以應用專門為此設計的整合學習技術(ensemble learning technique)。本文作者為來自 KPMG 的資料分析顧問 Upasana Mukherjee。
目錄
1. 不平衡資料集面臨的挑戰
2. 處理不平衡資料集的方法
3. 例證
4. 結論
1. 不平衡資料集面臨的挑戰
當今公用事業行業面臨的主要挑戰之一就是電力盜竊。電力盜竊是全球第三大盜竊形式。越來越多的公用事業公司傾向於使用高階的資料分析技術和機器學習演算法來識別代表盜竊的消耗模式。
然而,最大的障礙之一就是海量的資料及其分佈。欺詐性交易的數量要遠低於正常和健康的交易,也就是說,它只佔到了總觀測量的大約 1-2%。這裡的問題是提高識別罕見的少數類別的準確率,而不是實現更高的總體準確率。
當面臨不平衡的資料集的時候,機器學習演算法傾向於產生不太令人滿意的分類器。對於任何一個不平衡的資料集,如果要預測的事件屬於少數類別,並且事件比例小於 5%,那就通常將其稱為罕見事件(rare event)。
-
不平衡類別的例項
讓我們藉助一個例項來理解不平衡類別。
例子:在一個公用事業欺詐檢測資料集中,你有以下資料:
總觀測 = 1000
欺詐觀測 = 20
非欺詐觀測 = 980
罕見事件比例 = 2%
這個案例的資料分析中面臨的主要問題是:對於這些先天就是小概率的異常事件,如何通過獲取合適數量的樣本來得到一個平衡的資料集?
-
使用標準機器學習技術時面臨的挑戰
面臨不平衡資料集的時候,傳統的機器學習模型的評價方法不能精確地衡量模型的效能。
諸如決策樹和 Logistic 迴歸這些標準的分類演算法會偏向於數量多的類別。它們往往會僅預測佔資料大多數的類別。在總量中佔少數的類別的特徵就會被視為噪聲,並且通常會被忽略。因此,與多數類別相比,少數類別存在比較高的誤判率。
對分類演算法的表現的評估是用一個包含關於實際類別和預測類別資訊的混淆矩陣(Confusion Matrix)來衡量的。
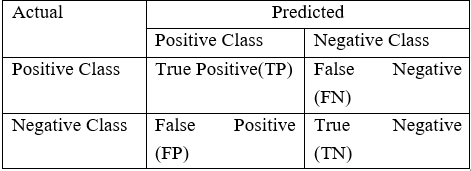
如上表所示,模型的準確率 = (TP+TN) / (TP+FN+FP+TP)
然而,在不平衡領域時,準確率並不是一個用來衡量模型效能的合適指標。例如:一個分類器,在包含 2% 的罕見事件時,如果它將所有屬於大部分類別的例項都正確分類,實現了 98% 的準確率;而把佔 2% 的少數觀測資料視為噪聲並消除了。
-
不平衡類別的例項
因此,總結一下,在嘗試利用不平衡資料集解決特定業務的挑戰時,由標準機器學習演算法生成的分類器可能無法給出準確的結果。除了欺詐性交易,存在不平衡資料集問題的常見業務問題還有:
-
識別客戶流失率的資料集,其中絕大多數顧客都會繼續使用該項服務。具體來說,電信公司中,客戶流失率低於 2%。
-
醫療診斷中識別罕見疾病的資料集
-
自然災害,例如地震
-
使用的資料集
這篇文章中,我們會展示多種在高度不平衡資料集上訓練一個性能良好的模型的技術。並且用下面的欺詐檢測資料集來精確地預測罕見事件:
總觀測 = 1000
欺詐觀測 = 20
非欺詐性觀測 = 980
事件比例 = 2%
欺詐類別標誌 = 0(非欺詐例項)
欺詐類別標誌 = 1(欺詐例項)
2. 處理不平衡資料集的方法
-
2.1 資料層面的方法:重取樣技術
處理不平衡資料集需要在往機器學習演算法輸入資料之前,制定諸如提升分類演算法或平衡訓練資料的類(資料預處理)的策略。後者因為應用範圍廣泛而更常使用。
平衡分類的主要目標不是增加少數類的的頻率就是降低多數類的頻率。這樣做是為了獲得大概相同數量的兩個類的例項。讓我們一起看看幾個重取樣(resampling)技術:
2.1.1 隨機欠取樣(Random Under-Sampling)
隨機欠取樣的目標是通過隨機地消除佔多數的類的樣本來平衡類分佈;直到多數類和少數類的例項實現平衡,目標才算達成。
總觀測= 1000
欺詐性觀察 = 20
非欺詐性觀察 = 980
事件發生率 = 2%
這種情況下我們不重複地從非欺詐例項中取 10% 的樣本,並將其與欺詐性例項相結合。
隨機欠取樣之後的非欺詐性觀察 = 980 x 10% = 98
結合欺詐性與非欺詐性觀察之後的全體觀察 = 20+98 = 118
欠取樣之後新資料集的事件發生率 = 20/118 = 17%
-
優點
-
它可以提升執行時間;並且當訓練資料集很大時,可以通過減少樣本數量來解決儲存問題。
-
缺點
-
它會丟棄對構建規則分類器很重要的有價值的潛在資訊。
-
被隨機欠取樣選取的樣本可能具有偏差。它不能準確代表大多數。從而在實際的測試資料集上得到不精確的結果。
2.1.2 隨機過取樣(Random Over-Sampling)
過取樣(Over-Sampling)通過隨機複製少數類來增加其中的例項數量,從而可增加樣本中少數類的代表性。
總觀測= 1000
欺詐性觀察 = 20
非欺詐性觀察 = 980
事件發生率 = 2%
這種情況下我們複製 20 個欺詐性觀察 20 次。
非欺詐性觀察 = 980
複製少數類觀察之後的欺詐性觀察 = 400
過取樣之後新資料集中的總體觀察 = 1380
欠取樣之後新資料集的事件發生率 = 400/1380 = 29%
-
優點
-
與欠取樣不同,這種方法不會帶來資訊損失。
-
表現優於欠取樣。
-
缺點
-
由於複製少數類事件,它加大了過擬合的可能性。
2.1.3 基於聚類的過取樣(Cluster-Based Over Sampling)
在這種情況下,K-均值聚類演算法獨立地被用於少數和多數類例項。這是為了識別資料集中的聚類。隨後,每一個聚類都被過取樣以至於相同類的所有聚類有著同樣的例項數量,且所有的類有著相同的大小。
總觀測= 1000
欺詐性觀察 = 20
非欺詐性觀察 = 980
事件發生率 = 2%
-
多數類聚類
1. 聚類 1:150 個觀察
2. 聚類 2:120 個觀察
3. 聚類 3:230 個觀察
4. 聚類 4:200 個觀察
5. 聚類 5:150 個觀察
6. 聚類 6:130 個觀察
-
少數類聚類
1. 聚類 1:8 個觀察
2. 聚類 2:12 個觀察
每個聚類過取樣之後,相同類的所有聚類包含相同數量的觀察。
-
多數類聚類
1. 聚類 1:170 個觀察
2. 聚類 2:170 個觀察
3. 聚類 3:170 個觀察
4. 聚類 4:170 個觀察
5. 聚類 5:170 個觀察
6. 聚類 6:170 個觀察
-
少數類聚類
1. 聚類 1:250 個觀察
2. 聚類 2:250 個觀察
基於聚類的過取樣之後的事件率 = 500/ (1020+500) = 33 %
-
優點
-
這種聚類技術有助於克服類之間不平衡的挑戰。表示正例的樣本數量不同於表示反例的樣本數量。
-
有助於克服由不同子聚類組成的類之間的不平衡的挑戰。每一個子聚類不包含相同數量的例項。
-
缺點
-
正如大多數過取樣技術,這一演算法的主要缺點是有可能過擬合訓練集。
2.1.4 資訊性過取樣:合成少數類過取樣技術(SMOTE)
這一技術可用來避免過擬合——當直接複製少數類例項並將其新增到主資料集時。從少數類中把一個數據子集作為一個例項取走,接著建立相似的新合成的例項。這些合成的例項接著被新增進原來的資料集。新資料集被用作樣本以訓練分類模型。
總觀測= 1000
欺詐性觀察 = 20
非欺詐性觀察 = 980
事件發生率 = 2%
從少數類中取走一個包含 15 個例項的樣本,並生成相似的合成例項 20 次。
生成合成性例項之後,建立下面的資料集
少數類(欺詐性觀察)= 300
多數類(非欺詐性觀察)= 980
事件發生率 = 300/1280 = 23.4 %
-
優點
-
通過隨機取樣生成的合成樣本而非例項的副本,可以緩解過擬合的問題。
-
不會損失有價值資訊。
-
缺點
-
當生成合成性例項時,SMOTE 並不會把來自其他類的相鄰例項考慮進來。這導致了類重疊的增加,並會引入額外的噪音。
-
SMOTE 對高維資料不是很有效。
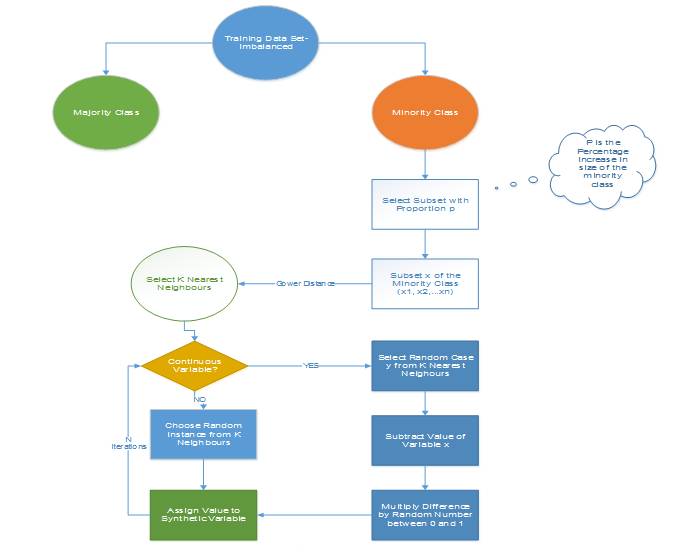
圖 1:合成少數類過取樣演算法,其中 N 是屬性的數量
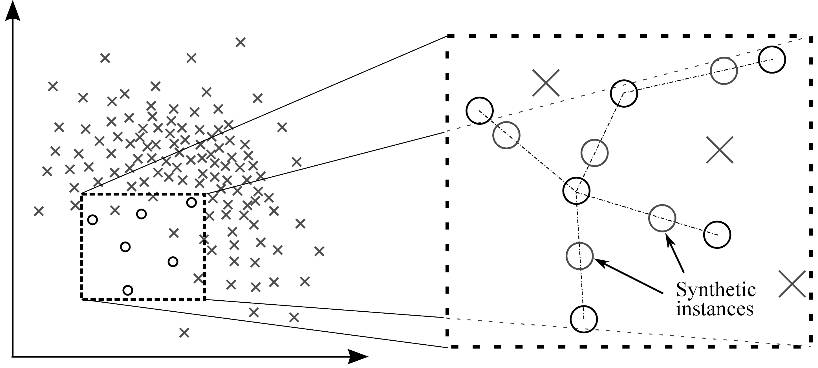
圖 2:藉助 SMOTE 的合成例項生成
2.15 改進的合成少數類過取樣技術(MSMOTE)
這是 SMOTE 的改進版本,SMOTE 沒有考慮資料集中少數類和潛在噪聲的基本分佈。所以為了提高 SMOTE 的效果,MSMOTE 應運而生。
該演算法將少數類別的樣本分為 3 個不同的組:安全樣本、邊界樣本和潛在噪聲樣本。分類通過計算少數類的樣本和訓練資料的樣本之間的距離來完成。安全樣本是可以提高分類器效能的那些資料點。而另一方面,噪聲是可以降低分類器的效能的資料點。兩者之間的那些資料點被分類為邊界樣本。
雖然 MSOMTE 的基本流程與 SMOTE 的基本流程相同,在 MSMOTE 中,選擇近鄰的策略不同於 SMOTE。該演算法是從安全樣本出發隨機選擇 k-最近鄰的資料點,並從邊界樣本出發選擇最近鄰,並且不對潛在噪聲樣本進行任何操作。
-
2.2 演算法整合技術(Algorithmic Ensemble Techniques)
上述部分涉及通過重取樣原始資料提供平衡類來處理不平衡資料,在本節中,我們將研究一種替代方法:修改現有的分類演算法,使其適用於不平衡資料集。
整合方法的主要目的是提高單個分類器的效能。該方法從原始資料中構建幾個兩級分類器,然後整合它們的預測。
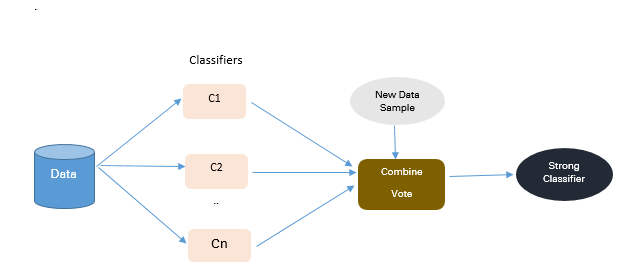
圖 3:基於整合的方法
2.2.1 基於 Bagging 的方法
Bagging 是 Bootstrap Aggregating 的縮寫。傳統的 Bagging 演算法包括生成「n」個不同替換的引導訓練樣本,並分別訓練每個自舉演算法上的演算法,然後再聚合預測。
Bagging 常被用於減少過擬合,以提高學習效果生成準確預測。與 boosting 不同,bagging 方法允許在自舉樣本中進行替換。

圖 4:Bagging 方法
總觀測= 1000
欺詐觀察= 20
非欺詐觀察= 980
事件率= 2%
從具有替換的群體中選擇 10 個自舉樣品。每個樣本包含 200 個觀察值。每個樣本都不同於原始資料集,但類似於分佈和變化上與該資料集類似。機器學習演算法(如 logistic 迴歸、神經網路與決策樹)擬合包含 200 個觀察的自舉樣本,且分類器 c1,c2 ... c10 被聚合以產生複合分類器。這種整合方法能產生更強的複合分類器,因為它組合了各個分類器的結果。
-
優點
-
提高了機器學習演算法的穩定性與準確性
-
減少方差
-
減少了 bagged 分類器的錯誤分類
-
在嘈雜的資料環境中,bagging 的效能優於 boosting
-
缺點
-
bagging 只會在基本分類器效果很好時才有效。錯誤的分類可能會進一步降低表現。
2.2.2. 基於 Boosting 的方法
Boosting 是一種整合技術,它可以將弱學習器結合起來創造出一個能夠進行準確預測的強大學習器。Boosting 開始於在訓練資料上準備的基本分類器/弱分類器。
基本學習器/分類器是弱學習器,即預測準確度僅略好於平均水平。弱是指當資料的存在小變化時,會引起分類模型出現大的變化。
在下一次迭代中,新分類器將重點放在那些在上一輪中被錯誤分類的案例上。
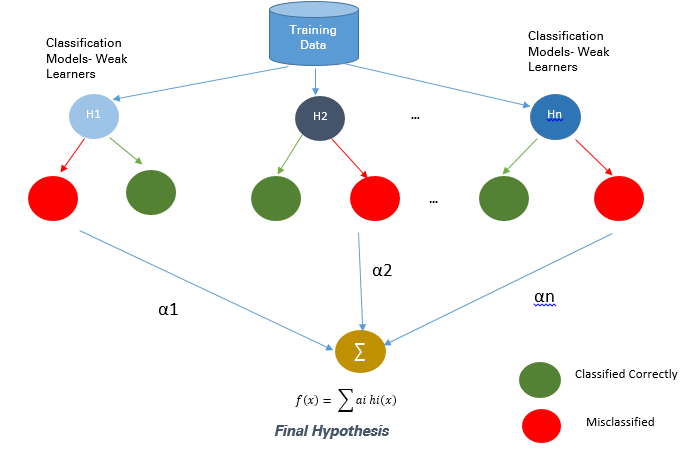
圖 5:Boosting 方法
2.2.2.1 自適應 boosting——Ada Boost
Ada Boost 是最早的 boosting 技術,其能通過許多弱的和不準確的規則的結合來創造高準確度的預測。其中每個訓練器都是被序列地訓練的,其目標在每一輪正確分類上一輪沒能正確分類的例項。
對於一個學習過的分類器,如果要做出強大的預測,其應該具備以下三個條件:
-
規則簡單
-
分類器在足夠數量的訓練例項上進行了訓練
-
分類器在訓練例項上的訓練誤差足夠低
每一個弱假設都有略優於隨機猜測的準確度,即誤差項 € (t) 應該略大約 ½-β,其中 β>0。這是這種 boosting 演算法的基礎假設,其可以產生一個僅有一個很小的誤差的最終假設。
在每一輪之後,它會更加關注那些更難被分類的例項。這種關注的程度可以通過一個權重值(weight)來測量。起初,所有例項的權重都是相等的,經過每一次迭代之後,被錯誤分類的例項的權重會增大,而被正確分類的例項的權重則會減小。
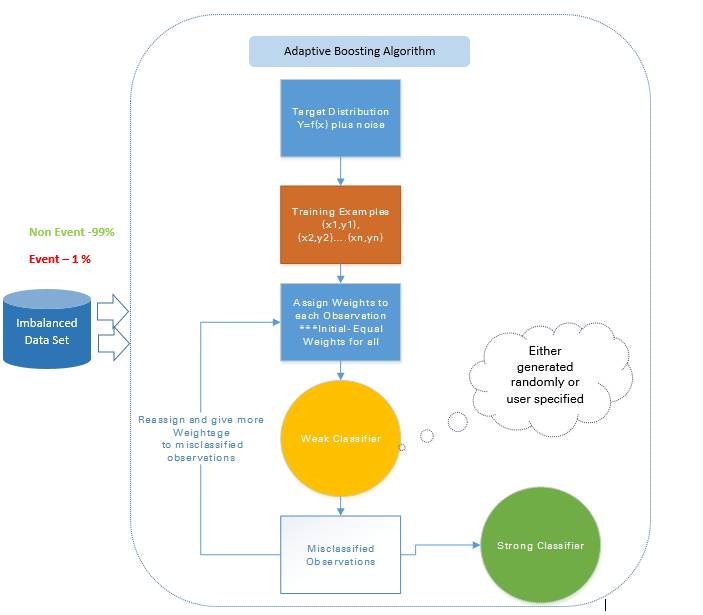
圖 6:自適應 boosting 的方法
比如如果有一個包含了 1000 次觀察的資料集,其中有 20 次被標記為了欺詐。剛開始,所有的觀察都被分配了相同的權重 W1,基礎分類器準確分類了其中 400 次觀察。
然後,那 600 次被錯誤分類的觀察的權重增大為 W2,而這 400 次被正確分類的例項的權重減小為 W3。
在每一次迭代中,這些更新過的加權觀察都會被送入弱的分類器以提升其表現。這個過程會一直持續,直到錯誤分類率顯著降低,從而得到一個強大的分類器。
-
優點
-
非常簡單就能實現
-
可以很好地泛化——適合任何型別的分類問題且不易過擬合
-
缺點
-
對噪聲資料和異常值敏感
2.2.2.2 梯度樹 boosting
在梯度 Boosting(Gradient Boosting)中,許多模型都是按順序訓練的。其是一種數值優化演算法,其中每個模型都使用梯度下降(Gradient Descent)方法來最小化損失函式 y = ax+b+e。
在梯度 Boosting 中,決策樹(Decision Tree)被用作弱學習器。
儘管 Ada Boost 和梯度 Boosting 都是基於弱學習器/分類器工作的,而且都是在努力使它們變成強大的學習器,但這兩種方法之間存在一些顯著的差異。Ada Boost 需要在實際的訓練過程之前由使用者指定一組弱學習器或隨機生成弱學習器。其中每個學習器的權重根據其每步是否正確執行了分類而進行調整。而梯度 Boosting 則是在訓練資料集上構建第一個用來預測樣本的學習器,然後計算損失(即真實值和第一個學習器的輸出之間的差),然後再使用這個損失在第二個階段構建改進了的學習器。
在每一個步驟,該損失函式的殘差(residual)都是用梯度下降法計算出來的,而新的殘差會在後續的迭代中變成目標變數。
梯度 Boosting 可以通過 R 語言使用 SAS Miner 和 GBM 軟體包中的 Gradient Boosting Node 實現。

圖 7:梯度 Boosting 方法
比如,如果有一個包含了 1000 次觀察的訓練資料集,其中有 20 次被標記為了欺詐,並且還有一個初始的基礎分類器。目標變數為 Fraud,當交易是欺詐時,Fraud=1;當交易不是欺詐時,Fraud=0.
比如說,決策樹擬合的是準確分類僅 5 次觀察為欺詐觀察的情況。然後基於該步驟的實際輸出和預測輸出之間的差,計算出一個可微的損失函式。該損失函式的這個殘差是下一次迭代的目標變數 F1。
類似地,該演算法內部計算該損失函式,並在每個階段更新該目標,然後在初始分類器的基礎上提出一個改進過的分類器。
-
缺點
-
梯度增強過的樹比隨機森林更難擬合
-
梯度 Boosting 演算法通常有 3 個可以微調的引數:收縮(shrinkage)引數、樹的深度和樹的數量。要很好擬合,每個引數都需要合適的訓練。如果這些引數沒有得到很好的調節,那麼就可能會導致過擬合。
2.2.2.3 XGBoost
XGBoost(Extreme Gradient Boosting/極限梯度提升)是 Gradient Boosting 演算法的一種更先進和更有效的實現。
相對於其它 Boosting 技術的優點:
-
速度比普通的 Gradient Boosting 快 10 倍,因為其可以實現並行處理。它是高度靈活的,因為使用者可以自定義優化目標和評估標準,其具有內建的處理缺失值的機制。
-
和遇到了負損失就會停止分裂節點的 Gradient Boosting 不同,XGBoost 會分裂到指定的最大深度,然後會對其樹進行反向的剪枝(prune),移除僅有一個負損失的分裂。
XGBoost 可以使用 R 和 Python 中的 XGBoost 包實現。
3. 實際案例
-
3.1 資料描述
這個例子使用了電信公司的包含了 47241 條顧客記錄的資料集,每條記錄包含的資訊有 27 個關鍵預測變數

罕見事件資料集的資料結構如下,缺失值刪除、異常值處理以及降維

從這裡下載資料集:https://static.analyticsvidhya.com/wp-content/uploads/2017/03/17063705/SampleData_IMC.csv
-
3.2 方法描述
使用合成少數類過取樣技術(SMOTE)來平衡不平衡資料集——該技術是試圖通過建立合成例項來平衡資料集。下面以 R 程式碼為例,示範使用 Gradient Boosting 演算法來訓練平衡資料集。
R 程式碼
# 載入資料
rareevent_boost <- read.table("D:/Upasana/RareEvent/churn.txt",sep="|", header=TRUE)dmy<-dummyVars("~.",data=rareevent_boost)rareeventTrsf<-data.frame(predict(dmy,newdata= rareevent_boost))set.seed(10)sub <- sample(nrow(rareeventTrsf), floor(nrow(rareeventTrsf) * 0.9))sub1 <- sample(nrow(rareeventTrsf), floor(nrow(rareeventTrsf) * 0.1))training <- rareeventTrsf [sub, ]testing <- rareeventTrsf [-sub, ]training_sub<- rareeventTrsf [sub1, ]tables(training_sub)head(training_sub)
# 對於不平衡的資料集 #
install.packages("unbalanced")library(unbalanced)data(ubIonosphere)n<-ncol(rareevent_boost)output<- rareevent_boost $CHURN_FLAGoutput<-as.factor(output)input<- rareevent_boost [ ,-n]View(input)
# 使用 ubSMOTE 來平衡資料集 #
data<-ubBalance(X= input, Y=output, type="ubSMOTE", percOver=300, percUnder=150, verbose=TRUEView(data)
# 平衡的資料集 #
balancedData<-cbind(data$X,data$Y)View(balancedData)table(balancedData$CHURN_FLAG)
# 寫入平衡的資料集來訓練模型 #
write.table(balancedData,"D:/ Upasana/RareEvent /balancedData.txt", sep="t", row.names=FALSE)
# 建立 Boosting 樹模型 #
repalceNAsWithMean <- function(x) {replace(x, is.na(x), mean(x[!is.na(x)]))}training <- repalceNAsWithMean(training)testing <- repalceNAsWithMean(testing)
# 重取樣技術 #
View(train_set)fitcontrol<-trainControl(method="repeatedcv",number=10,repeats=1,verbose=FALSE)gbmfit<-train(CHURN_FLAG~.,data=balancedData,method="gbm",verbose=FALSE)
# 為測試資料評分 #
testing$score_Y=predict(gbmfit,newdata=testing,type="prob")[,2]testing$score_Y=ifelse(testing$score_Y>0.5,1,0)head(testing,n=10)write.table(testing,"D:/ Upasana/RareEvent /testing.txt", sep="t", row.names=FALSE)pred_GBM<-prediction(testing$score_Y,testing$CHURN_FLAG)
# 模型的表現 #
model_perf_GBM <- performance(pred_GBM, "tpr", "fpr")model_perf_GBM1 <- performance(pred_GBM, "tpr", "fpr")model_perf_GBMpred_GBM1<-as.data.frame(model_perf_GBM)auc.tmp_GBM <- performance(pred_GBM,"auc")AUC_GBM <- as.numeric([email protected])auc.tmp_GBM
-
結果
這個在平衡資料集上使用了 SMOTE 並訓練了一個 gradient boosting 演算法的平衡資料集的辦法能夠顯著改善預測模型的準確度。較之平常分析建模技術(比如 logistic 迴歸和決策樹),這個辦法將其 lift 提升了 20%,精確率也提升了 3 到 4 倍。
4. 結論
遇到不平衡資料集時,沒有改善預測模型準確性的一站式解決方案。你可能需要嘗試多個辦法來搞清楚最適合資料集的取樣技術。在絕大多數情況下,諸如 SMOTE 以及 MSMOTE 之類的合成技術會比傳統過取樣或欠取樣的辦法要好。
為了獲得更好的結果,你可以在使用諸如 Gradeint boosting 和 XGBoost 的同時也使用 SMOTE 和 MSMOTE 等合成取樣技術。
通常用於解決不平衡資料集問題的先進 bagging 技術之一是 SMOTE bagging。這個辦法採取了一種完全不同於傳統 bagging 技術的辦法來創造每個 Bag/Bootstrap。通過每次迭代時設定一個 SMOTE 重取樣率,它可以藉由 SMOTE 演算法生成正例。每次迭代時,負例集會被 bootstrap。
不平衡資料集的特點不同,最有效的技術也會有所不同。對比模型時要考慮相關評估引數。
在對比通過全面地結合上述技術而構建的多個預測模型時,ROC 曲線下的 Lift & Area 將會在決定最優模型上發揮作用。
參考文獻
1. Dmitry Pavlov, Alexey Gorodilov, Cliff Brunk「BagBoo: A Scalable Hybrid Bagging-theBoosting Model」.2010
2. Fithria Siti Hanifah , Hari Wijayanto , Anang Kurnia「SMOTE Bagging Algorithm for Imbalanced Data Set in Logistic Regression Analysis」. Applied Mathematical Sciences, Vol. 9, 2015
3. Lina Guzman, DIRECTV「Data sampling improvement by developing SMOTE technique in SAS」.Paper 3483-2015
4. Mikel Galar, Alberto Fern´andez, Edurne Barrenechea, Humberto Bustince and Francisco Herrera「A Review on Ensembles for the Class Imbalance Problem: Baggng-, Boosting-, and Hybrid-Based Approaches」.2011 IEEE
原文地址:https://www.analyticsvidhya.com/blog/2017/03/imbalanced-classification-problem相關推薦
機器學習中不平衡資料的處理方式
https://blog.csdn.net/pipisorry/article/details/78091626 不平衡資料的場景出現在網際網路應用的方方面面,如搜尋引擎的點選預測(點選的網頁往往佔據很小的比例),電子商務領域的商品推薦(推薦的商品被購買的比例很低),信用卡欺詐檢測,網路攻擊識別
從重取樣到資料合成:如何處理機器學習中的不平衡分類問題?
轉自:http://www.sohu.com/a/129333346_465975 選自Analytics Vidhya 作者:Upasana Mukherjee 機器之心編譯 參與:馬亞雄、微胖、黃小天、吳攀 如果你研究過一點機器學習和資料科學,你肯定遇到過不平衡的類分
[轉]如何處理機器學習中的不平衡類別
down 觀測 input 推薦 可能 type 兩個 好的 exchange 如何處理機器學習中的不平衡類別 原文地址:How to Handle Imbalanced Classes in Machine Learning 原文作者:elitedatascienc
機器學習 —— 類不平衡問題與SMOTE過取樣演算法
轉自:https://www.cnblogs.com/Determined22/p/5772538.html 在前段時間做本科畢業設計的時候,遇到了各個類別的樣本量分佈不均的問題——某些類別的樣本數量極多,而有些類別的樣本數量極少,也就是所謂的類不平衡(class-imbala
如何處理機器學習中的異常值
在機器學習中進行資料處理往往會遇到極端異常值,是否刪除極端異常值往往會影響到最終模型的準確性。找到異常值以後,判斷是否需要移除是根據我們的目標而定。 異常值的幾種情況 如果我們只是要找到人為錯誤導致的點,大可直接移除; 如果移除異常值並不會改變結果,僅僅會改變假設(as
資料探勘和機器學習中距離和相似度公式
距離:閔可夫斯基距離公式,也叫 Lp 範數: 當p=1時,變為曼哈頓距離公式,也即 L1範數: 當p=2時,變為歐式距離公式,也即 L2範數: 衡量空間中點的絕對距離,對絕對數值敏感。 相似性: 餘弦相似: 皮爾遜相關係數,即相關分析中的相關係數,對兩個個體的向
機器學習-類別不平衡問題
之前 size 訓練 最近鄰 機制 每次 問題 線性 大於 引言:我們假設有這種情況,訓練數據有反例998個,正例2個,模型是一個永遠將新樣本預測為反例的學習器,就能達到99.8%的精度,這樣顯然是不合理的。 類別不平衡:分類任務中不同類別的訓練樣例數差別很大。
機器學習中的多分類任務入門
摘要: 這篇文章主要是關於機器學習中多分類任務的一些基本知識。 1.我先丟擲一個問題,在LR(邏輯迴歸)中,如何進行多分類? 一般下,我們所認識的lr模型是一個二分類的模型,但是,能否用lr進行多分類任務呢?答案當然是可以的。 不過,我們需要注意的是,我們有許多種思路利
學機器學習,不會資料處理怎麼行?—— 二、Pandas詳解
在上篇文章學機器學習,不會資料處理怎麼行?—— 一、NumPy詳解中,介紹了NumPy的一些基本內容,以及使用方法,在這篇文章中,將接著介紹另一模組——Pandas。(本文所用程式碼在這裡) Pandas資料結構介紹 大家應該都聽過表結構,但是,如果讓你自己來實現這麼一個結構,並且能對其進行資料處理,能實
機器學習筆記 第1課:機器學習中的資料
資料在機器學習中起著重要的作用。 在談論資料時,理解和使用正確的術語非常重要。 你如何看待資料?想想電子表格吧,有列、行和單元格。 從統計視角而言,機器學習的任務是在假設函式( f )的上下文中構建資料。這些假設函式由機器學習演算法通過學習建立。給定一些輸入變數( Input ),該函式回答
機器學習中資料的歸一化處理
資料的標準化(normalization)是將資料按比例縮放,使之落入一個小的特定區間。在某些比較和評價的指標處理中經常會用到,去除資料的單位限制,將其轉化為無量綱的純數值,便於不同單位或量級的指標能夠進行比較和加權。 其中最典型的就是資料的歸一化處理,即將資料統一對映到[0,1]區間上
機器學習中的資料預處理
資料的預處理總共可以大致分為6步。 匯入需要的庫 這兩個是我們每次都需要匯入的庫 Numpy包含數學計算函式 Pandas用於匯入和管理資料集 匯入資料集 資料集通常是.csv格式。csv檔案以文字形式儲存表格資料。檔案的每一行是一條資料記錄。我們使用pandas的r
未明學院活動:機器學習熱門專案開始報名,一次收穫資料探勘&機器學習技能、行業專案經歷!
隨著大資料時代的到來,金融、通訊、網際網路等越來越多的行業需要資料科學方面的人才。在數聯尋英2016年釋出的《大資料人才報告》中表明,現階段我國大資料人才僅有 46 萬,在未來 3-5 年內大資料人才缺口將高達 150 萬。 缺口的逐漸增大,大資料人才的薪資也跟著水漲船高。據某權威招聘
《機器學習實戰》第2章閱讀筆記3 使用K近鄰演算法改進約會網站的配對效果—分步驟詳細講解1——資料準備:從文字檔案中解析資料(附詳細程式碼及註釋)
本篇使用的資料存放在文字檔案datingTestSet2.txt中,每個樣本資料佔據一行,總共有1000行。 樣本主要包含以下3中特徵: (1)每年獲得飛行常客里程數 (2)玩視訊遊戲所耗時間百分比 (3)每週消費的冰淇淋公升數 在使用分類器之前,需要將處理的檔案格式
機器學習中的資料清洗與特徵處理綜述
https://tech.meituan.com/machinelearning_data_feature_process.html 機器學習中的資料清洗與特徵處理綜述 caohao ·2015-02-10 11:30 背景 隨著美團交易規模的逐步增大,積
Python資料探勘與機器學習_通訊信用風險評估實戰(2)——資料預處理
系列目錄: 資料說明 通過對讀取資料的實踐,下面是資料集檔案對應讀取後的DataFrame說明。 資料檔案 DataFrame DataTech_Credit_Train_Communication1.txt train
【特徵工程】2 機器學習中的資料清洗與特徵處理綜述
背景 隨著美團交易規模的逐步增大,積累下來的業務資料和交易資料越來越多,這些資料是美團做為一個團購平臺最寶貴的財富。通過對這些資料的分析和挖掘,不僅能給美團業務發展方向提供決策支援,也為業務的迭代指明瞭方向。目前在美團的團購系統中大量地應用到了機器學習和資料探勘技術,例
【方法】機器學習中的資料清洗與特徵處理
來源:http://tech.meituan.com/machinelearning-data-feature-process.html 背景 隨著美團交易規模的逐步增大,積累下來的業務資料和交易資料越來越多,這些資料是美團做為一個團購平臺最寶貴的財富。通過對這些資料的
機器學習中常用的資料集處理方法
1.離散值的處理: 因為離散值的差值是沒有實際意義的。比如如果用0,1,2代表紅黃藍,1-0的差值代表黃-紅,是沒有意義的。因此,我們往往會把擁有d個取值的離散值變為d個取值為0,1的離散值或者將其對映為多維向量。 2.屬性歸一化: 歸一化的目標是把各位屬