
Hadoop-2.6.0+Zookeeper-3.4.6+Spark-1.5.0+Hbase-1.1.2+Hive-1.2.0叢集搭建
前言
本部落格目的在於跟大家分享大資料平臺搭建過程,是筆者半年的結晶。在大資料搭建過程中,希望能給大家提過一些幫助,這也是本部落格的價值所在。
部落格內容分為將五個部分,具體如下:
第一部分 叢集平臺搭建
第二部分 SSH登入和JDK安裝
第三部分 Hadoop-2.6.0+zookeeper-3.4.6叢集搭建
第四部分 Spark叢集搭建
第五部分 Hive叢集搭建
第六部分 Hbase 叢集搭建
以下是本叢集所需要的軟體,大家可按需要進行下載:
Ubuntu14.04
VMware Workstation 12 Pro for Linux
Hadoop-2.6.0
jdk-7u80-linux-x64.gz
Zookeeper-3.4.6
Spark-1.5.0
Hbase-1.1.2
Hive-1.2.0
第一部分 Ubuntu物理機和虛擬機器搭建
叢集框架,採用一臺物理機和兩臺虛擬機器。在PC機上用easyBCD方式安裝Win和Ubuntu雙系統。
一.安裝easyBCD
1.下載
網址:http://172.28.0.26/cache/4/02/crsky.com/f5eedf182f9ae67bdd575d0feaf80406/EasyBCD-v2.2.zip
2.設定引導
安裝好easyBCD,開啟並點選新增新條目–>安裝–>NeoGrub–>配置,如圖所示:
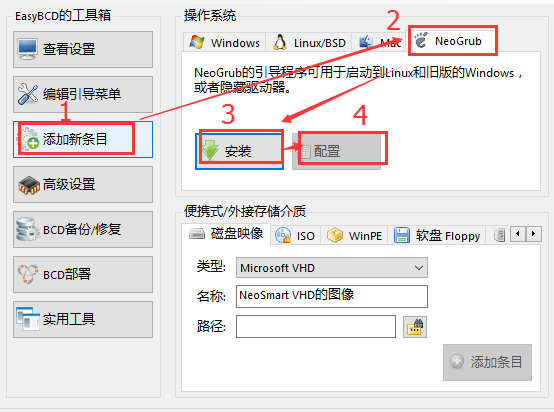
點選配置後,會跳出menu.lst檔案,刪除檔案裡面的所有內容,並複製以下內容到檔案內:
title Install Ubuntu
root (hd0,1)
kernel (hd0,1)/vmlinuz.efi boot=casper iso-scan/filename=/ubuntu-14.04-desktop-amd64.iso ro quiet splash locale=zh_CN.UTF-8
initrd (hd0,1)/initrd.lz注:如果Win作業系統有系統保留分割槽,則root處為1,即root(hd0,1);如果沒有則為0,即root(hd0,0)。
二.安裝Ubuntu
將buntu-14.04-desktop-amd64.iso檔案拷貝到C盤。用解壓軟體開啟,在casper檔案下有兩個檔案:initrd.lz、vmlinuz.efi,將它們複製到C盤。
接下來重啟PC,在引導介面選擇NeoGrub,進入安裝介面後,ctril+alt+t開啟終端命令,輸入以下命令需要使用的命令取消光碟驅動器掛載:
sudo umount -l /isodevice 三.Ubuntu相關配置
1.開啟軟體中心更改軟體更新源,一般選擇國內的網易。
2.列舉本地更新
sudo apt-get update3.安裝可用更新
sudo apt-get upgrade4.修改root使用者登入
sudo gedit /usr/share/lightdm/lightdm.conf.d/50-ubuntu.conf新增
[SeatDefaults]
greeter-session=unity-greeter
user-session=ubuntu
greeter-show-manual-login=true
allow-guest=false 5.設定 root使用者密碼,,並輸入root使用者的密碼
sudo passwd root 6.解除安裝防火牆
ufw disable //關閉
sudo apt-get remove ufw //解除安裝
sudo ufw status //檢視7.安裝ssh
安裝ssh-server
sudo apt-get install openssh-server安裝ssh-client
sudo apt-get install openssh-client驗證:
ps -e | grep ssh
450 ??00:00:00 sshd //如果出現這個,則安裝成功
重啟ssh:
/etc/init.d/ssh restart四.安裝Ubuntu虛擬機器
5A02H-AU243-TZJ49-GTC7K-3C61N2.安裝VMware
使用以下命令安裝VMware,”/home/huai/桌面/“為我在Ubuntu下檔案路徑名,大家可跟據自己的做更改。
sudo chmod +x /home/huai/桌面/VMware-Workstation-Full-12.0.0-2985596.x86_64.bundle
sudo /home/huai/桌面/VMware-Workstation-Full-12.0.0-2985596.x86_64.bundle3.安裝虛擬機器
注:虛擬機器使用者名稱要與物理機的使用者名稱保持一致,如筆者的三臺叢集的使用者名稱都是“huai”。
用VMware安裝虛擬機器,採用典型方式安裝,操作過程很簡單,就不在這敘述了,大家可另行百度。對於剛安裝好Ubuntu虛擬機器,是可以聯網的。按照上面Ubuntu物理機的相關配置對虛擬機器Ubuntu進行同樣操作。
配置好虛擬機器,關閉虛擬機器和VMware。複製安裝的虛擬機器檔案,構成兩臺虛擬機器。
4.修改主機名
因為筆者搭建此叢集是為了學習spark,故將三臺叢集主機名命為spark01、spark02和spark03。其中,park01為物理機,充當主節點。spark02和spark03為兩臺虛擬機器的主機名。
修改物理機主機名,使用以下命令將主機名改為spark01:
sudo gedit /etc/hostname修改虛擬機器主機名:同上,分別修改為spark02和spark03。
五.修改IP
叢集IP分別設為
192.168.8.101, 192.168.8.102, 192.168.8.1031.設定虛擬機器IP模式
虛擬機器網絡卡設定為host-only模式(具體操作,請百度)
2.設定spark02的IP
通過介面設定IP
系統設定-->網路-->選項 -->IPv4設定--> method選擇為manual--> 點選add按鈕--新增
IP:192.168.8.102 子網掩碼:255.255.255.0 閘道器:192.168.1.1--> apply3.設定spark03的IP
通過同樣的方式把spark03的IP設定為:192.168.8.103
4.設定物理機spark01的IP
給物理機設定靜態IP有點麻煩,因為在學校用的是內網,根據網上很多方法設定後,都無法再上網了。以下這種方式是網上比較常見的修改方式,但是不好使,只作參考,修改方式如下:
1)一種令人不愉快的方式
開啟:
sudo gedit /etc/network/interfaces
新增:
auto eth0
iface eth0 inet static
address 192.168.8.101
netmask 255.255.255.0
gateway 192.168.8.1 設定DNS域名解析:
開啟:
sudo gedit /etc/resolv.conf
新增:
search nwu.edu.cn
nameserver 202.117.96.5
nameserver 202.117.96.10
nameserver 127.0.1.1
開啟:
sudo gedit /etc/resolvconf/resolv.conf.d/tail
新增:
search nwu.edu.cn
nameserver 202.117.96.5
nameserver 202.117.96.10
nameserver 127.0.1.1
重啟networking命令:
sudo /etc/init.d/networking restart
sudo /etc/init.d/resolvconf restart
筆者自己找到了兩種方式設定一個固定的IP,簡單且容易實現,關鍵在百度上都找不到。一種是採用橋接,第二種是繫結
2)採用橋接
1.點選桌面右上角網路圖示欄中的"編輯連線",網路連線中選中"橋接",點選"新增";
2.對跳轉出來選擇連線型別視窗,選擇"虛擬--橋接",點選"新建",
3.在橋接--橋接連線(c)處,點選"新增",選擇"乙太網",點選新建,在裝置MAC地址(D)處.選擇"eth0",並"儲存"
4.點選IPv4設定,方法處選擇為"手動",>點選"新增"設定IP為:192.168.8.101 子網掩碼:255.255.255.0 閘道器:192.168.1.1,"儲存"3)採用繫結
採用繫結的方式與橋接方式操作一樣,就是在操作2中,選擇“虛擬--繫結”,其他操作一樣。六.修改主機名和IP的對映關係
整個叢集的主機名和IP的對映關係的內容設定是一樣的,分別在三臺機子上操作以下命令:
sudo gedit /etc/hosts
新增:
192.168.8.101 spark01
192.168.8.102 spark02
192.168.8.103 spark03 七.重啟
關閉兩臺虛擬機器,並重啟Ubuntu物理機 第二部分 SSH登入和JDK安裝
一.SSH登入配置
本叢集的使用者名稱為”huai”,叢集儘量用統一的使用者名稱,用不同的ssh登入時,還要進行一些其他操作,很麻煩。
1.在物理機spark01上,使用以下命令,四個回車,並cd到相關目錄,操作如下:
huai@spark01:~$ ssh-keygen -t rsa
huai@spark01:~$ cd /home/huai/.ssh
huai@spark01:~/.ssh$ ls
id_rsa id_rsa.pub生成兩個檔案:id_rsa(私鑰)、id_rsa.pub(公鑰)
2.對兩臺虛擬機器進行同樣操作(如上)
3.將虛擬機器的id_rsa.pub(公鑰)傳到spark01,”huai”是我叢集的使用者名稱,”huai”應改為你自己設定的使用者名稱。分別在spark02和spark03進行以下操作:
scp id_rsa.pub huai@spark01:/home/huai/.ssh/id_rsa.pub.spark02
scp id_rsa.pub huai@spark01:/home/huai/.ssh/id_rsa.pub.spark034.在物理機上,按以下操作:
huai@spark01:~$ cd /home/huai/.ssh
huai@spark01:~/.ssh$ ls
id_rsa.pub id_rsa.pub.spark03
id_rsa id_rsa.pub.spark02 將公鑰匯入到綜合authorized_keys檔案中,在目錄[email protected]:~/.ssh$下使用匯入命令:
cat id_rsa.pub >> authorized_keys
cat id_rsa.pub.spark02 >> authorized_keys
cat id_rsa.pub.spark03 >> authorized_keys5.將spark01上的authorized_keys複製到spark02和spark03的/home/huai/.ssh/目錄下
scp authorized_keys huai@spark02:/home/huai/.ssh/authorized_keys
scp authorized_keys huai@spark03:/home/huai/.ssh/authorized_keys 6.ssh常見錯誤修改
因為筆者的已經配置好,具體錯誤就沒法再重現了。不過只要按以下操作之後,保證不會再有錯誤。
1):
sudo gedit /etc/ssh/sshd_config開啟檔案後,註釋”PermitRootLogin without-password”,使用”#”註釋
並在其下面新增: PermitRootLogin yes
2):
開啟:
sudo gedit /etc/ssh/ssh_config
新增:
StrictHostKeyChecking no
UserKnownHostsFile /dev/null3):
如果有Agent admitted failure to sign using the key錯誤丟擲,執行以下命令即可:
ssh-add4):
如果ssh登入時,在known_hosts報出警告,後面顯示一個數字,使用以下命令將其刪除,比如顯示數字”8”.
sed -i 8d /home/huai/.ssh/known_hosts7.分別在每臺上進行以下ssh登入,使用”exit”退出
ssh spark01
ssh spark02
ssh spark03二.安裝JDK
1.下載jdk,6和8不做考慮,8不支援,6版本太低,下載地址如下:
2.安裝
建立java資料夾:
sudo mkdir /usr/java解壓
sudo tar -zxvf /home/huai/桌面/jdk-7u80-linux-x64.gz -C /usr/java/修改檔案許可權
sudo chmod -R 777 /usr/java/ 3.修改環境變數
因為筆者叢集已經搭建好了,為了讓大家不要經常修改環境變數,筆者在此處把所有安裝包的環境變數都列出來,供大家參考。
操作:
sudo gedit /etc/profile
在檔案最後新增:
export JAVA_HOME=/usr/java/jdk1.7.0_80
export JRE_HOME=/usr/java/jdk1.7.0_80/jre
export SCALA_HOME=/spark/scala-2.11.6
export SPARK_HOME=/spark/spark-1.5.0
export HADOOP_HOME=/spark/hadoop-2.6.0
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib:$HADOOP_HOME/lib/native"
export HIVE_HOME=/spark/hive-1.2.0
export IDEA_HOME=/usr/idea/idea-IC-141.178.9
export HBASE_HOME=/spark/hbase-1.1.2
export ZOOKEEPER_HOME=/spark/zookeeper-3.4.6
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$SCALA_HOME/bin:$SPARK_HOME/bin:$IDEA_HOME/bin:$HIVE_HOME/bin:$HBASE_HOME/bin:$ZOOKEEPER_HOME/bin重新整理
source /etc/profile4.驗證
使用命令java -version,如果出現java version “1.7.0_80”,則安裝成功
5.設定jdk預設
如果Ubuntu上已經安裝過openjdk納悶需要設定預設jdk。若以上驗證成功,可以跳過設定預設jdk。依次操作以下命令:
sudo update-alternatives --install /usr/bin/java java /usr/java/jdk1.7.0_80/bin/java 300
sudo update-alternatives --install /usr/bin/javac javac /usr/java/jdk1.7.0_80/bin/javac 300
sudo update-alternatives --install /usr/bin/jar jar /usr/java/jdk1.7.0_80/bin/jar 300
sudo update-alternatives --install /usr/bin/javah javah /usr/java/jdk1.7.0_80/bin/javah 300
sudo update-alternatives --install /usr/bin/javap javap /usr/java/jdk1.7.0_80/bin/javap 300
sudo update-alternatives --config java 第三部分 Hadoop-2.6.0+zookeeper-3.4.6叢集搭建
一.叢集規劃
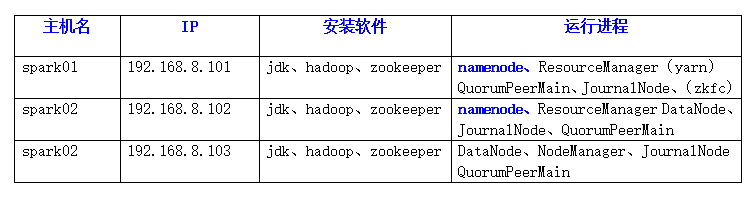
文字描述:本叢集僅有三臺機子:spark01、spark02和spark03。三臺都安裝hadoop-2.6.0,zookeeper-3.4.6。spark01和spark02共運行了兩個namenode,兩個datanode執行spark02和spark03上。
二.zooekeeper配置
1.建立spark資料夾
sudo mkdir /spark
修改許可權:
sudo chmod -R 777 /spark2.解壓
sudo tar -zxvf /home/huai/桌面/zookeeper-3.4.6.tar.gz -C /spark/3.修改zoo.cfg檔案
cd /spark/zookeeper-3.4.6/conf/
mv zoo_sample.cfg zoo.cfg
4.配置zoo.cfg
gedit zoo.cfg
修改:
dataDir=/spark/zookeeper-3.4.6/tmp
新增:
dataLogDir=/spark/zookeeper-3.4.6/logs
在最後新增:
server.1=spark01:2888:3888
server.2=spark02:2888:3888
server.3=spark03:2888:3888
儲存退出5.建立資料夾
mkdir /spark/zookeeper-3.4.6/tmp
mkdir /spark/zookeeper-3.4.6/logs6.設定myid
在5)中建立的tmp資料夾下建立一個空檔案,並在其中寫入”1“。
建立檔案:
touch myid
寫入"1":
gedit myid7.修改環境變數
雖然前面已經把所有的環境變數都設定好了,但這個步驟是環境配置必須的操作,所以在此處重複一遍
開啟:
sudo gedit /etc/profile
新增:
export ZOOKEEPER_HOME=/spark/zookeeper-3.4.6
export PATH=:$ZOOKEEPER_HOME/bin:$ZOOKEEPER_HOME/conf
重新整理:
source /etc/profile8.將配置好的zookeeper拷貝到其他節點
scp -r /spark/zookeeper-3.4.6/ huai@spark02:/spark/
scp -r /spark/zookeeper-3.4.6/ huai@spark03:/spark/9.修改虛擬機器的myid
執行:
cd /spark/zookeeper-3.4.6/tmp
開啟:
gedit myid
其中:
在spark02 中寫入"2"
在spark03 中寫入"3"10.修改虛擬機器的環境變數
按7中的操作分別修改虛擬機器spark02和spark03的環境變數。
sudo tar -zxvf /home/huai/桌面/hadoop-2.6.0.tar.gz -C /spark
修改許可權:
sudo chmod -R 777 /spark3.配置hadoop環境檔案
注:在操作hadoop-env.sh,註釋以下內容
#export HADOOP_OPTS="$HADOOP_OPTS -
Djava.net.preferIPv4Stack=true"cd到配置檔案目錄下:
cd /spark/hadoop-2.6.0/etc/hadoop/
依次操作:
gedit hadoop-env.sh
gedit yarn-env.sh
gedit mapred-env.sh
依次新增:
export JAVA_HOME=/usr/java/jdk1.7.0_80
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib:$HADOOP_HOME/lib/native"
依次儲存退出按以下操作依次修改hadoop其它配置檔案,可以直接複製到配置檔案。相關檔案屬性以及細節,可以查閱其他資料。
4.gedit core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://ns1</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/spark/hadoop-2.6.0/tmp</value>
</property>
<property>
<name>ha.zookeeper.quorum</name> <value>spark01:2181,spark02:2181,spark03:2181</value>
</property>
</configuration>5.gedit hdfs-site.xml
<configuration>
<property>
<name>dfs.nameservices</name>
<value>ns1</value>
</property>
<property>
<name>dfs.ha.namenodes.ns1</name>
<value>nn1,nn2</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ns1.nn1</name>
<value>spark01:9000</value>
</property>
<property>
<name>dfs.namenode.http-address.ns1.nn1</name>
<value>spark01:50070</value>
</property>
<property>
<name>dfs.namenode.rpc-address.ns1.nn2</name>
<value>spark02:9000</value>
</property>
<property>
<name>dfs.namenode.http-address.ns1.nn2</name>
<value>spark02:50070</value>
</property>
<property>
<name>dfs.namenode.shared.edits.dir</name> <value>qjournal://spark01:8485;spark02:8485;spark03:8485/ns1</value>
</property>
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/spark/hadoop-2.6.0/journal</value>
</property>
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.client.failover.proxy.provider.ns1</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
shell(/bin/true)
</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/home/huai/.ssh/id_rsa</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
</configuration>6.mv mapred-site.xml.template mapred-site.xml
gedit mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration> 7.gedit yarn-site.xml
<configuration>
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yrc</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>spark01</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>spark02</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>spark01:2181,spark02:2181,spark03:2181</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration> 8.gedit slaves
spark02
spark0310.複製到其他節點
scp -r /spark/hadoop-2.6.0 huai@spark02:/spark
scp -r /spark/hadoop-2.6.0 huai@spark03:/spark 11.修改環境變數,可略過
開啟:
sudo gedit /etc/profile
新增:
export HADOOP_HOME=/spark/hadoop-2.6.0
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
重新整理:
source /etc/profile 12.驗證
輸入以下命令,如果出現hadoop對應的版本,則hadoop配置成功。
hadoop version三.叢集啟動(嚴格按照下面的步驟)
1.啟動zookeeper叢集(分別在spark01、spark02、spark03上啟動zk)
cd /spark/zookeeper-3.4.6/bin/
./zkServer.sh start
檢視狀態:一個leader,兩個follower
zkServer.sh status2.啟動journalnode(分別在spark01、spark02、spark03上啟動journalnode)
在三臺機子上執行:
cd /spark/hadoop-2.6.0/sbin
hadoop-daemon.sh start journalnode
執行jps命令檢驗,spark01、spark02、spark03上多了JournalNode程序
3.格式化HDFS
在主節點spark01上執行命令
hdfs namenode -format格式化成功會生成tmp檔案,其路徑為core-site.xml中的hadoop.tmp.dir配置路徑
4.將tmp拷到其他節點
注意tmp的路徑:
scp -r tmp huai@spark02:/spark/hadoop-2.6.0/
scp -r tmp huai@spark03:/spark/hadoop-2.6.0/
5.格式化ZK
在spark01上執行:
hdfs zkfc -formatZK6.啟動HDFS
在spark01上執行:
start-dfs.sh
7.啟動YARN.resourcemanager
start-yarn.sh8.驗證
通過以下IP用瀏覽器訪問,一個處於active,一個處於standby,說明叢集啟動成功。
http://192.168.8.101:50070
NameNode 'spark01:9000' (active)
http://192.168.8.102:50070
NameNode 'spark02:9000' (standby)9.驗證HDFS HA
向hdfs上傳一個檔案:
hadoop fs -put /etc/profile /profile
hadoop fs -ls /kill掉active的NameNode
kill -9 <pid of NN>
訪問:http://192.168.8.101:50070 無法開啟
訪問:http://192.168.8.102:50070
NameNode 'spark02:9000' (active)執行:
hadoop fs -ls /
-rw-r--r-- 3 root supergroup 1926 2015-05-024 15:36 /profile手動啟動掛掉的那個NameNode,在spark01上執行
hadoop-daemon.sh start namenode
訪問:http://192.168.8.101:50070
顯示:NameNode 'spark01:9000' (standby)
刪除上傳檔案:
hadoop fs -rm -r /profile到這,hadoop叢集相當於已經成功搭建,剩下的就是要搭建基於hadoop的其他元件,如spark,hive,hbase。相信通過自學搭建hadoop叢集的人兒,一定受了不少折騰。作為不是技術大牛的人兒,唯有屢敗屢戰,才能祭奠內心那份對技術的熱血澎湃。
第四部分 Spark叢集搭建
因為spark 原始碼是使用Scala語言,所以需要安裝Scala環境。
一.安裝 Scala
1.下載
網址:http://www.scala-lang.org/download/
2.解壓
sudo tar -zxf sudo tar -zxvf /home/huai/桌面/scala-2.11.6.tgz -C /spark3.修改環境變數
開啟:
sudo gedit /etc/profile
新增:
export SCALA_HOME=/spark/scala-2.11.6
export PATH=PATH:$SCALA_HOME/bin
重新整理:
source /etc/profile4.顯示版本
huai@spark01:~$ scala -version
Scala code runner version 2.11.6 -- Copyright 2002-2013, LAMP/EPFL
- 測試
輸入”scala”命令,進入scala互動介面
huai@spark01:~$ scala
scala> 8*8
res0: Int = 646.將scala複製到其他節點
scp -r /spark/scala-2.11.6/ huai@spark02:/spark/
scp -r /spark/scala-2.11.6/ huai@spark03:/spark/7.重複 3修改其他節點的環境變數
2.解壓
tar -zxf /home/huai/桌面/spark-1.5.0-bin-hadoop2.6.tgz -C /spark3.檔名修改為:spark-1.5.0
mv /spark/spark-1.5.0-bin-hadoop2.6 spark-1.5.04.修改環境變數
開啟:
sudo gedit /etc/profile
新增:
export SPARK_HOME=/spark/spark-1.5.0
export PATH=PATH:$SPARK_HOME/bin
重新整理:
source /etc/profile 5.配置spark-env.sh
進入spark的conf目錄:
cd /spark/spark-1.5.0/conf/
mv spark-env.sh.template spark-env.sh
開啟:
sudo gedit spark-env.sh
新增:
export JAVA_HOME=/usr/java/jdk1.7.0_80
export SCALA_HOME=/spark/scala-2.11.6
export SPARK_MASTER_IP=192.168.8.101
export SPARK_WORKER_MEMORY=1g
export HADOOP_CONF_DIR=/spark/hadoop-2.6.0/etc/hadoop
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib:$HADOOP_HOME/lib/native"6.配置slaves
在spark的conf目錄下:
mv slaves.template slaves
開啟:
sudo gedit slaves
新增:
spark01
spark02
spark03 7.把spark複製到其他節點
scp -r spark-1.5.0 huai@spark02:/spark/
scp -r spark-1.5.0 huai@spark03:/spark/
8.修改虛擬階環境變數
sudo gedit /etc/profile
新增:
export SPARK_HOME=/spark/spark-1.5.0
export PATH=PATH:$SPARK_HOME/bin
export SCALA_HOME=/spark/scala-2.11.6
export PATH=PATH:$SCALA_HOME/bin
重新整理:
source /etc/profile三.啟動叢集
1.啟動zookeeper
在每臺執行:
zkServer.sh start2.啟動hadoop叢集,在hadoop的sbin目錄下執行:
start-all.sh3.啟動spark叢集
/spark/spark-1.5.0/bin$./start-all.sh5.Web管理介面
http://192.168.8.101:8080/Spark有好幾個模組,如SparkSQL,Graphx,MLlib。因為Mapreduce處理速率不如Spark快,Spark將成為Mapreduce的替代品。對於Spark,我主要學習了機器學習MLlib和SparkSQL。如果你對大資料感興趣,那麼建議好好研究一下Spark。
第五部分 Hive叢集搭建
一.概述
hive安裝可分為四部分:
1)安裝mysql
2)配置 Metastore
3)配置HiveClient
4)配置hiveserver搭建分佈:mysql,Metastore安裝配置在主節點spark01上, HiveClient客戶端安裝在spark02上。注:HiveClient客戶端也可以不配置。
三.安裝mysql
mysql只需在物理機spark01上安裝,Ubuntu軟體中心下載安裝mysql伺服器
1.配置mysql
執行:
/usr/bin/mysql_secure_installation
輸入密碼:
刪除匿名使用者:
Remove anonymous users? [Y/n] Y
允許使用者遠端連線:
Disallow root login remotely? [Y/n]n
移除test資料庫:
Remove test database and access to it? [Y/n] Y2.登陸mysql
mysql -u root -p3.建立hive資料庫,並對其授權,注’huai’為你設立的登入密碼
mysql>create database hive;
mysql>GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY 'huai' WITH GRANT OPTION;
mysql>FLUSH PRIVILEGES;
4.修改hive資料庫字元
一定要修改,不然hive建表時會報錯。
mysql>alter database hive character set latin15.修改允許遠端登入mysql
sudo gedit /etc/mysql/my.cnf
註釋:
#bind-address=127.0.0.1sudo tar -zxvf /home/huai/桌面apache-hive-1.2.0.tar.gz -C /spark/
檔名修改為hive-1.2.0
mv apache-hive-1.2.0 hive-1.2.03.修改配置檔名
在hive-1.2.0/conf下
mv hive-default.xml.template hive-site.xml
mv hive-log4j.properties.template hive-log4j.properties
mv hive-exec-log4j.properties.template hive-exec-log4j.properties
mv hive-env.sh.template hive-env.sh4.gedit hive-env.sh
export HADOOP_HOME=/spark/hadoop-2.6.0
export HIVE_CONF_DIR=/spark/hive-1.2.0/conf5.gedit hive-log4j.properties
新增
hive.log.dir=/spark/hive-1.2.0/logs6.新建logs檔案
mkdir /spark/hive-1.2.0/logs7.gedit hive-site.xml
刪除所有內容,新增如下內容.注意配置檔案中的’huai’為mysql登入密碼,記得修改
<configuration>
<property>
<name>hive.metastore.warehouse.dir</name>
<value>hdfs://ns1/hive/warehouse</value>
</property>
<property>
<name>hive.exec.scratchdir</name>
<value>hdfs://ns1/hive/scratchdir</value>
</property>
<property>
<name>hive.querylog.location</name>
<value>/spark/hive-1.2.0/logs</value>
</property>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://localhost:3306/hive?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>ja