
LibLinear使用總結(L1,L2正則)
在相關推薦專案的改版中,對liblinear/fm/xgboost等主流成熟演算法模型的訓練效果進行了嘗試和對比,並在一期改造中選擇了liblinear實際上線使用。本文主要從工程應用的角度對liblinear涉及的各模式進行初步介紹,並給出liblinear/fm/xgboost的實際評測結果供參考。 (參考自http://blog.csdn.net/ytbigdata/article/details/52909685)
1. Liblinear說明
考慮到訓練效率,本次選用的為多執行緒並行版liblinear,實際為liblinear-multicore-2.1-4,首先直接給出其train命令所支援的各模式說明,各模式選擇不僅與我們使用liblinear工具直接相關,也對我們理解liblinear很有幫助,下面即主要圍繞這些模式展開。
ParallelLIBLINEAR is only available for -s0, 1, 2, 3, 11 now
Usage:train [options] training_set_file[model_file]
options:
-s type : set typeof solver (default 1)
formulti-class classification (dual對偶的, primal 原始的)
0 -- L2-regularized logisticregression (primal) ---邏輯迴歸
1 -- L2-regularized L2-losssupport vector classification (dual) ---
2 -- L2-regularized L2-loss supportvector classification (primal)--與1對應
3-- L2-regularized L1-loss support vector classification (dual)
4-- support vector classification by Crammer and Singer
5-- L1-regularized L2-loss support vector classification
6-- L1-regularized logisticregression
7-- L2-regularized logistic regression (dual)
forregression
11-- L2-regularized L2-loss support vector regression (primal)
12-- L2-regularized L2-loss support vector regression (dual)
13-- L2-regularized L1-loss support vector regression (dual)
1.1 liblinear還是libsvm
既然是liblinear相關,不可免俗地會涉及到這個問題,當然其實這是個很大的命題,在此我們擷取重點簡單介紹。
首先,liblinear和libsvm都是國立臺灣大學林智仁(Chih-Jen Lin)老師團隊開發的,libsvm早在2000年就已經發布,liblinear則在2007年才釋出首個版本。
在原理和實現上存在差別,libsvm是一套完整的svm實現,既包含基礎的線性svm,也包含核函式方式的非線性svm;liblinear則是針對線性場景而專門實現和優化的工具包,同時支援線性svm和線性Logistic Regression模型。由於libsvm支援核函式方式實現非線性分類器,理論上,libsvm具有更強的分類能力,應該能夠處理更復雜的問題。
但是,libsvm的訓練速度是個很大的瓶頸,按一般經驗,在樣本量過萬後,libsvm就比較慢了,樣本量再大一個數量級,通常的機器就無法處理了;而liblinear設計初衷就是為了解決大資料量的問題,正因為只需要支援線性分類,liblinear可以採用與libsvm完全不一樣的優化演算法,在保持線性svm分類時類似效果的同時,大大降低了訓練計算複雜度和時間消耗。
同時,在大資料背景下,線性分類和非線性分類效果差別不大,尤其是在特徵維度很高而樣本有限的情況下,核函式方式有可能會錯誤地劃分類別空間,導致效果反而變差。林智仁老師也給出過很多實際例子證明,人工構造特徵+線性模型的方式可以達到甚至超過kernel SVM的表現,同時大大降低訓練的時間和消耗的資源。
關於實際時間對比,liblinear作者官方給出了以下資料:對於LIBSVM資料集中某例項"20242個樣本/47236個特徵",在保持交叉驗證的精度接近的情況下,liblinear僅耗時約3秒,遠遠小於libsvm的346秒。
% timelibsvm-2.85/svm-train -c 4 -t 0 -e 0.1 -m 800 -v 5rcv1_train.binary
CrossValidation Accuracy = 96.8136%
345.569s
% timeliblinear-1.21/train -c 4 -e 0.1 -v 5rcv1_train.binary
CrossValidation Accuracy = 97.0161%
2.944s
1.2 具體solver的選擇?線性svm還是logisticregression/L1正則化項還是L2正則化項
liblinear支援多種solver模式,以下直接列舉liblinear支援的幾種典型solver模式對應的結構風險函式(結構風險函式由損失函式和正則化項/罰項組合而成,實際即為求解結構風險函式最小值的最優化問題),以方便說明和理解。
L2-regularizedL1-loss Support VectorClassification

L2-regularizedL2-loss Support Vector Classification
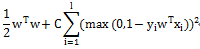
L1-regularizedL2-loss Support Vector Classification
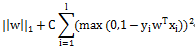
L2-regularized Logistic Regression
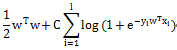
L1-regularized Logistic Regression
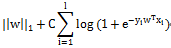
Liblinear中同時支援線性svm和logisticregression,兩者最大區別即在於損失函式(loss function)不同,損失函式是用來描述預測值f(X)與實際值Y之間差別的非負實值函式,記作L(Y, f(X)),即上述公式中的項。
另一個重要選擇是正則化項。正則化項是為了降低模型複雜度,提高泛化能力,避免過擬合而引入的項。當資料維度很高/樣本不多的情況下,模型引數很多,模型容易變得很複雜,表面上看雖然極好地通過了所有樣本點,但實際卻出現了很多過擬合,此時則通過引入L1/L2正則化項來解決。
一般情況下,L1即為1範數,為絕對值之和;L2即為2範數,就是通常意義上的模。L1會趨向於產生少量的特徵,而其他的特徵都是0,即實現所謂的稀疏,而L2會選擇更多的特徵,這些特徵都會接近於0。
對於solver的選擇,作者的建議是:一般情況下推薦使用線性svm,其訓練速度快且效果與lr接近;一般情況下推薦使用L2正則化項,L1精度相對低且訓練速度也會慢一些,除非想得到一個稀疏的模型(個人注:當特徵數量非常大,稀疏模型對於減少線上預測計算量比較有幫助)。
1.3 primal還是dual
primal和dual分別對應於原問題和對偶問題的求解,對結果是沒有影響的,但是對偶問題可能比較慢。作者有如下建議:對於L2正則-SVM,可以先嚐試用dual求解,如果非常慢,則換用primal求解。
網上另一個可參考的建議是:對於樣本量不大,但是維度特別高的場景,如文字分類,更適合對偶問題求解;相反,當樣本數非常多,而特徵維度不高時,如果採用求解對偶問題,則由於Kernel Matrix過大,求解並不方便。反倒是求解原問題更加容易。
1.4 訓練資料是否要歸一化
對於這點,作者是這樣建議的:在他們文件分類的應用中,歸一化不但能大大減少訓練時間,也能使得訓練效果更好,因此我們選擇對訓練資料進行歸一化。同時在實踐中,歸一化使得我們能直接對比各特徵的公式權重,直觀地看出哪些特徵比較重要。
2. liblinear及fm/xgboost實際效果對比記錄
本輪改造中,主要實際嘗試了liblinear各模式的效果,也同時對業界常用的fm/xgboost進行了對比測試,以下一併列出供參考。
注:由於liblinear尚為單機訓練,受記憶體限制,不能載入全量資料訓練,因此後續針對訓練資料量多少(1/120->1/4->1/2)也有專門實驗;
5, xgboost效果總結
xgboost的全稱是eXtreme Gradient Boosting,它是GradientBoosting Machine的一個c++實現,作者為華盛頓大學研究機器學習的大牛陳天奇。傳統GBDT以CART作為基分類器,xgboost還支援線性分類器,它能夠自動利用CPU的多執行緒進行並行,同時在演算法上加以改進提高了精度,在Kaggle等資料競賽平臺社群知名度很高。
在測試中,xgboost確實表現出了實力,僅用預設引數配置和1/120小資料量(約200萬樣本),就達到了0.8406的超出所有liblinear效果的AUC;受時間限制,當前並未直接採用xgboost,後續有同事進一步跟進。
相關推薦
LibLinear使用總結(L1,L2正則)
在相關推薦專案的改版中,對liblinear/fm/xgboost等主流成熟演算法模型的訓練效果進行了嘗試和對比,並在一期改造中選擇了liblinear實際上線使用。本文主要從工程應用的角度對liblinear涉及的各模式進行初步介紹,並給出liblinear/fm/xg
深度學習正則化-引數範數懲罰(L1,L2範數)
L0範數懲罰 機器學習中最常用的正則化措施是限制模型的能力,其中最著名的方法就是L1和L2範數懲罰。 假如我們需要擬合一批二次函式分佈的資料,但我們並不知道資料的分佈規律,我們可能會先使用一次函式去擬合,再
綜合案例分析(sort,cut,正則)
sbin ati bsp ima 如何 難點 一次 方法 當前 1、 找出ifconfig “網卡名” 命令結果中本機IPv4地址 分析: 解釋:要取出ip地址,首先我們可以先取出ip所在的行,即取行;可以結合head和tail,後面會有 更好的方法去取行,取列當然
NN模型設定--L1/L2正則化
正則化的理解 規則化函式Ω有多重選擇,不同的選擇效果也不同,不過一般是模型複雜度的單調遞增函式——模型越複雜,規則化值越大。 正則化含義中包含了權重的先驗知識,是一種對loss的懲罰項(regularization term that penalizes paramete
L1,L2正則
總體概述: L1 L 1 L_1正則: L1=α∥ω∥1
利用自定義的異常驗證郵箱合法性(不使用正則)
不用正則表示式,驗證郵箱合法性 a、本地驗證---驗證的是郵箱與密碼的格式 --郵箱: 1、要有@ . 2、@ . 前後不能為空 3、@要在 . 的前面 4、@前面的長度至少是10,包含數字,字母,且必須有大寫字母 b
機器學習損失函式、L1-L2正則化的前世今生
前言: 我們學習一個演算法總是要有個指標或者多個指標來衡量一下算的好不好,不同的機器學習問題就有了不同的努力目標,今天我們就來聊一聊迴歸意義下的損失函式、正則化的前世今生,從哪裡來,到哪裡去。 一.L1、L2下的Lasso Regression和Ridg
L1 L2正則化
L1和L2正則都是比較常見和常用的正則化項,都可以達到防止過擬合的效果。L1正則化的解具有稀疏性,可用於特徵選擇。L2正則化的解都比較小,抗擾動能力強。 L2正則化 對模型引數的L2正則項為 即權重向量中各個元素的平方和,通常取1/2。L2正則也經常被稱作“
批歸一化(Batch Normalization)、L1正則化和L2正則化
from: https://www.cnblogs.com/skyfsm/p/8453498.html https://www.cnblogs.com/skyfsm/p/8456968.html BN是由Google於2015年提出,這是一個深度神經網路訓練的技巧,它不僅可以加快了
泛化能力、訓練集、測試集、K折交叉驗證、假設空間、欠擬合與過擬合、正則化(L1正則化、L2正則化)、超引數
泛化能力(generalization): 機器學習模型。在先前未觀測到的輸入資料上表現良好的能力叫做泛化能力(generalization)。 訓練集(training set)與訓練錯誤(training error): 訓練機器學習模型使用的資料集稱為訓練集(tr
機器學習筆記(二)L1,L2正則化
2.正則化 2.1 什麼是正則化? (截自李航《統計學習方法》) 常用的正則項有L1,L2等,這裡只介紹這兩種。 2.2 L1正則項 L1正則,又稱lasso,其公式為: L1=α∑kj=1|θj| 特點:約束θj的大小,並且可以產
深入剖析迴歸(二)L1,L2正則項,梯度下降
一、迴歸問題的定義 迴歸是監督學習的一個重要問題,迴歸用於預測輸入變數和輸出變數之間的關係。迴歸模型是表示輸入變數到輸出變數之間對映的函式。迴歸問題的學習等價於函式擬合:使用一條函式曲線使其很好的擬合已知函式且很好的預測未知資料。 迴歸問題分為模型的學習和預測兩個
SVM支援向量機系列理論(七) 線性支援向量機與L2正則化 Platt模型
7.1 軟間隔SVM等價於最小化L2正則的合頁損失 上一篇 說到, ξi ξ i \xi_i 表示偏離邊界的度量,若樣本點
機器學習防止過擬合之L1範數(正則)與LASSO
機器學習過擬合問題 對於機器學習問題,我們最常遇到的一個問題便是過擬合。在對已知的資料集合進行學習的時候,我們選擇適應度最好的模型最為最終的結果。雖然我們選擇的模型能夠很好的解釋訓練資料集合,但卻不一定能夠很好的解釋測試資料或者其他資料,也就是說這個模型過於精
python學習第十四節(正則)
image all flags 正則 asdf alt afa images lag python2和python3都有兩種字符串類型strbytes re模塊find一類的函數都是精確查找。字符串是模糊匹配 findall(pattern,string,flags) r
用正則表達式完成xpath的功能(強大的正則表達式)
atime quest fin tle clas 12px int time xpath 1 url = ‘http://money.163.com/special/pinglun‘ 2 response = requests.get(url) 3 # regex = r
【機器學習】--線性回歸中L1正則和L2正則
last clas nbsp post pan red font 推廣 http 一、前述 L1正則,L2正則的出現原因是為了推廣模型的泛化能力。相當於一個懲罰系數。 二、原理 L1正則:Lasso Regression L2正則:Ridge Regression
L1正則 L2正則
color blank lan nbsp height ref com pan 圖片 也就是吳恩大大講的regularization ,俗稱懲罰項目。 詳細介紹戳鏈接!!! L1正則 L2正則
機器學習之路: python線性回歸 過擬合 L1與L2正則化
擬合 python sco bsp orm AS score 未知數 spa git:https://github.com/linyi0604/MachineLearning 正則化: 提高模型在未知數據上的泛化能力 避免參數過擬合正則化常用的方法: 在目
L1和L2正則化直觀理解
正則化是用於解決模型過擬合的問題。它可以看做是損失函式的懲罰項,即是對模型的引數進行一定的限制。 應用背景: 當模型過於複雜,樣本數不夠多時,模型會對訓練集造成過擬合,模型的泛化能力很差,在測試集上的精度遠低於訓練集。 這時常用正則化來解決過擬合的問題,常用的正則化有L1正則化和L2