
Torch7深度學習教程(五)
這一節先介紹一些基本操作,然後再對我們前面建立的網路進行訓練
- 神經網路的前向傳播和反向傳播
隨即生產一張照片,1通道,32x32畫素的。為了直觀像是,匯入image包,然後用itorch.image()方法顯示生成的圖片,就是隨即的一些點。
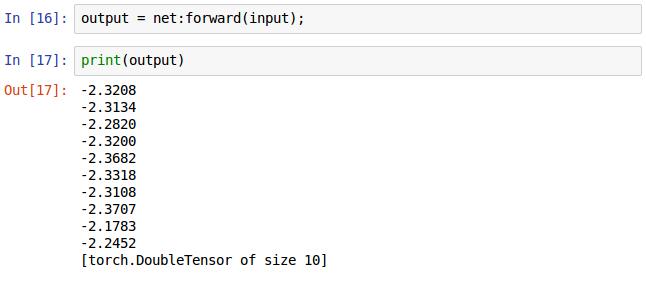
用之前建立好的神經網路net呼叫forward()方法輸入隨即生成的圖片得到輸出的結果,如打印出來的形式,net最後是10個輸出節點,這裡輸出了10個值。注意,這是前向傳播,網路裡面的權重是隨即分佈的,這是BP演算法之前需要做的運算。
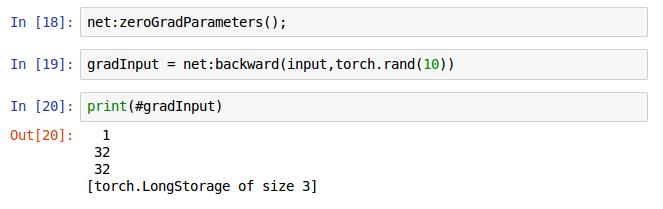
18行是將網路裡面的梯度快取設定為0,19行是網路net的反向傳播方法,第一個引數是輸入的圖片,這裡應與forward()方法裡面輸入的圖片一致,第二個引數在這裡的意思是訓練用的分類標籤,注意不是預測出來的標籤,是訓練樣本的真實的標籤,即需要擬合的標籤。最後返回的是需要輸入的梯度,即進行梯度下降演算法是需要的那個梯度(可能是,我回頭再確認下,這個不影響我們訓練)
前向傳播和反向傳播的基本過程就是上面,當然到這還不能我們的網路,還沒有定義損失函式,下面介紹損失函式的基本操作。
- criterion評價準則,這是用來定義損失函式的。當你想讓你的神經網路學習一些東西時,你就要給他一些反饋,告訴他怎麼做是對的。損失函式能夠形式化的衡量你的神經網路的好壞。例子如下:
還是在nn這個包裡面有很多的評測函式,在這裡我選擇了ClassNLLCriterion()這種方法,這是用來多分類的方法,用的是negative log-likelihood(負對數似然概率,抱歉非數學專業不知道怎麼翻譯這個,不過不影響時候,只需知道他是用來做多分來的評測函式就行)。
損失函式的實現也有正向和方向兩個操作,多說一點,不同的神經網路用BP演算法求解的思想是一樣的,但是定義的網路不同其具體的損失度量不同官方文件還強調該函式特別適合不平衡資料的分類!!!。就這個例子來說我們定義是適合對分類的損失函式,呼叫他的前向傳播方法並輸入的引數分別為預測的類和訓練樣本所屬的類。這裡執行後會有一個返回值,即他們的誤差(err),博主沒有進行賦值。
執行完損失函式的前向操作後,再進行反向操作,backward()方法裡面的引數同forward()函式裡的引數,返回值是損失函式的梯度。
呼叫神經網路net的backward()方法輸入訓練集和其對應的損失函式梯度。然後,使用神經網路net的updateParameters()更新權重,該方法的輸入值為學習率,即完成了訓練。注意,gradInput這個返回值可寫可不寫不影響我們的訓練。





這一樣本想著寫完訓練的過程,但是現在只是介紹了下訓練的基本操作,下週有考試,暫定幾天更新,下面估計還要有一張才能真正地把我們前面構建的網路訓練下,因為還有一個數據預處理的過程也會花一章分享。
相關推薦
Torch7深度學習教程(五)
這一節先介紹一些基本操作,然後再對我們前面建立的網路進行訓練 神經網路的前向傳播和反向傳播 隨即生產一張照片,1通道,32x32畫素的。為了直觀像是,匯入image包,然後用itorch.image()方法顯示生成的圖片,就是隨即的一些點
Torch7深度學習教程(七)
這一章主要分享預測的基本操作,並且先將前面分享的內容總結下,完整地實現CNN影象分類的例項 require 'paths'; require 'nn'; ---Load TrainSet paths.filep("/home/ubuntu64/c
Torch7深度學習教程(二)
Torch裡非常重要的結構Tensor(張量),類似於Python用的Numpy 宣告Tensor的格式如12行,列印a可以得到一個5x3的矩陣,這裡的沒有賦初值,但是Torch也會隨即賦值的,具體的就跟c++裡面的生命了變數雖沒有初始化,但是還是會
深度學習方法(五):卷積神經網路CNN經典模型整理Lenet,Alexnet,Googlenet,VGG,Deep Residual Learning
歡迎轉載,轉載請註明:本文出自Bin的專欄blog.csdn.net/xbinworld。 技術交流QQ群:433250724,歡迎對演算法、技術感興趣的同學加入。 關於卷積神經網路CNN,網路和文獻中有非常多的資料,我在工作/研究中也用了好一段時間各種常見的model了,就想著
pygame學習教程(五)用exec優化上一個例子
前一篇 在C,C++程式碼重複工作用巨集表示。舉例。我用Msp430程式設計寫的巨集。 巨集可以理解為文字替換。它的好處在於可以靈活地替換變數,舉個例子。 #define SETOUT(IONAME,IONUMBER) \ P##IONAME##DIR|=BIT##IO
深度學習基礎(五)--聚類
總結一下今天的學習過程(注:程式碼都是根據教程抄的,哈哈) 1,溫習了統計學中的相關度與R值有關知識,以及計算公式,以及Python程式碼的實現,在簡單線性迴歸中,兩個是等價的 2,學習了k-means演算法,感覺這個應該是理解了,並對程式碼進行了單步除錯及邏輯的進一步理解
深度學習基礎(五)—— 資料預處理
1 PCA 主成分分析法,一般用於資料降維。WHY? 影象中相鄰的畫素高度相關,輸入資料是有一定冗餘的。具體來說,假如我們正在訓練的16x16灰度值影象,記為一個256維向量 x∈ℜ256,其中特徵值 xj對應每個畫素的亮度值。由於相鄰畫素間的相關
深度學習系列(五):一個簡單深度學習工具箱
本節主要介紹一個深度學習的matlab版工具箱, 該工具箱中的程式碼很簡單,感覺比較適合用來學習演算法。裡面有常見的網路結構,包括深度網路(NN),稀疏自編碼網路(SAE),CAE,深度信念網路(DBN)(基於玻爾茲曼RBM實現),卷積神經網路(CNN
TensorFlow:實戰Google深度學習框架(五)影象識別與卷積神經網路
第6章 影象識別與卷積神經網路 本章通過利用CNN實現影象識別的應用來說明如何使用TensorFlow實現卷積神經網路 6.1 影象識別問題簡介及經典資料集 1. Cifar Cifar-10:10種不同種類的60000張影象,畫素大小為3
深度學習筆記(五)第五章 深度學習基礎
深度學習是一種特殊的機器學習。要了解深度學習需要對機器學習有紮實的理解。本章是對整本書需要使用的最重要的通用原理的簡單課程。 什麼是學習演算法?比如:線性迴歸。大多數學習演算法需要預先設定好超級引數(hyperparameters)。我們要討論怎麼去設定它。
深度學習筆記(五)用Torch實現RNN來製作一個神經網路計時器
本節程式碼地址 現在終於到了激動人心的時刻了。我最初選用Torch的目的就是為了學習RNN。RNN全稱Recurrent Neural Network(遞迴神經網路),是通過在網路中增加回路而使其具有記憶功能。對自然語言處理,影象識別等方面都有深遠影響。 這次我們要用R
Jasperreports+jaspersoft studio學習教程(五)- JavaBean作為資料來源填充資料
在實際專案中,一般使用java物件作為資料來源的方式更多,這種方式會更加靈活多變。對於mvc結構更為契合。上面介紹了用JDBC資料來源時,用到了Fields物件。本篇主要是使用Fileds物件來匹配JavaBean物件。 5.1 在專案中新建user物件(新增get,
hive學習教程(五):hive和Hbase整合
一、Hive整合HBase原理 Hive與HBase整合的實現是利用兩者本身對外的API介面互相進行通訊,相互通訊主要是依靠hive-hbase-handler-0.9.0.jar工具類,如下圖 Hive與HBase通訊示意圖 二、具體步驟
基於PyTorch的深度學習入門教程(五)——訓練神經網路分類器
前言本文參考PyTorch官網的教程,分為五個基本模組來介紹PyTorch。為了避免文章過長,這五個模組分別在五篇博文中介紹。本文是關於Part4的內容。Part4:訓練一個神經網路分類器前面已經介紹了
機器學習實戰教程(五):樸素貝葉斯實戰篇之新浪新聞分類
原文連結: Jack-Cui,https://cuijiahua.com/blog/2017/11/ml_5_bayes_2.html 一、前言 上篇文章機器學習實戰教程(四):樸素貝葉斯基礎篇之言論過濾器講解了樸素貝葉斯的基礎知識。本篇文章將在此基礎上進行擴充套件,你將看到以下內容: 拉普拉
(windows10版)Tensorflow 實戰Google深度學習框架學習筆記(五)正則化
# 1. 生成模擬資料集import tensorflow as tfimport matplotlib.pyplot as pltimport numpy as npdata = []label = []np.random.seed(0) #每次生成相同的隨機數# 以原點為
TensorFlow官方教程學習筆記(五)——前饋神經網路
本文主要是在TensorFlow上搭建一個前饋神經網路(feed-forward neural network)來對TensorFlow的運作方式進行簡單介紹。 程式碼在\examples\tutorials\mnist\中,主要使用兩個檔案:mnist.py和fully
Tensorflow 實戰Google深度學習框架——學習筆記(五)TensorFlow持久化
TensorFlow模型持久化 模型持久化的目的:為了讓訓練完的模型可以在下次使用 TensorFlow提供了一個非常簡單的API來儲存和還原一個神經網路,這個API類就是tf.train.Saver類。以下是儲存TensorFlow計算圖的方法。 變數
從零開始學習html(五)與瀏覽者交互,表單標簽——下
定位 開始 系統 isp ctr 程序 顯示 text 輸入 六、使用下拉列表框進行多選 1 <!DOCTYPE HTML> 2 <html> 3 <head> 4 <meta http-equiv="Content-T
數據結構學習筆記(五) 樹的創建和遍歷
一個 後序遍歷 for -1 堆棧 nor ext cnblogs 復制 創建(先序創建和根據先序和中序進行創建)和遍歷(先序遍歷、中序遍歷、後序遍歷、非遞歸堆棧遍歷、層次遍歷): package tree; public class XianCreateTree