
【機器學習】--神經網路(NN)
簡單介紹:
神經網路主要是預設人類腦結構進行的一種程式碼程式結構的表現,同時是RNN,CNN,DNN的基礎。結構上大體上分為三個部分(輸入,含隱,輸出),各層都有個的講究,其中,輸入層主要是特徵處理後的入口,含隱層用來訓練相應函式,節點越多,訓練出的函式就越複雜,輸出層輸出相應的預測結果,比較常見的就是多分類了。演算法特點:
1、神經網路屬於有監督學習的一種; 2、計算複雜度比較高,因為增加了相應的啟用函式,所以等於複合函式巢狀複合函式; 3、含隱層的神經元越多,計算函式便越複雜,但帶來的好處是,不用過度考慮特徵方程,較其它機器學習入門演算法而言,省卻了特徵適配; 4、BP後向傳播其實就是誤差函式反推引數求導過程,不知道為什麼網路上的很多部落格都沒有人點出來,可能是使用BP後向傳播演算法,讓別人聽起來更厲害一些吧; 5、需要考慮過擬合問題; 6、數學不好別看了,看前五條就行了。學習神經網路的基本流程:
基礎知識:
神經網路
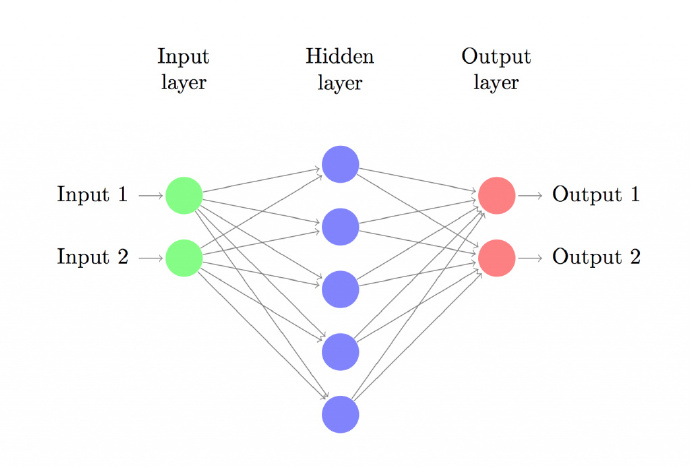
上圖建立具有一個輸入層、一個隱藏層、一個輸出層的三層神經網路。輸入層的結點數由資料維度決定,這裡是2維。類似地,輸出層的結點數由類別數決定,也是2。(因為我們只有兩類輸出,實際中我們會避免只使用一個輸出結點預測0和1,而是使用兩個輸出結點以使網路以後能很容易地擴充套件到更多類別)。每一個神經元都可以理解成一個函式,這個函式,也可以叫做啟用函式,例如,輸入神經元理解為Fin(x),含隱神經元理解為Fhn(x),輸出神經元理解為Fou(x),每一層之間都是具有一個權重引數w(或者叫θ),每一層的輸出乘上權重引數,都是下一層的輸入,例如,Fin( input1 ) * w1 就是含隱層的輸入,Fhn( Fin( input1 ) * w1 ) *w2 就是輸出層的輸入,Fou( Fhn( Fin(input1 ) * w1 ) * w2 )計算出最後的輸出值。
常見的啟用函式:
誤差函式:
參考我寫的機器學習--邏輯迴歸這篇文章吧,裡面有提到,這裡我們使用的是對數似然損失。這裡特別說明一下,需要注意,交叉熵和對數似然很像,需要注意區別。本次神經網路的三層形式:
輸入層:特徵,用x表示 輸入層和含隱層之間的權重:使用w1表示 含隱層:tanh() 含隱層和輸出層之間的權重:使用w2表示 輸出層:softmax() 輸出結果:Y表示(帶上角標的那個我打不出來。。。)softmax的函式如下:
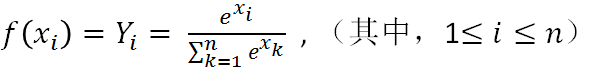
其中,Yi表示第i類的輸出,xi表示第i類的輸入,底部的是所有輸入的求和。
softmax的求導:
需要先行注意的是,底部xk的累加和是包含n個未知引數的,但在求導過程中,除了對其求到的那個未知引數外,其它引數,都視為常數項; f(xi)對xi求導: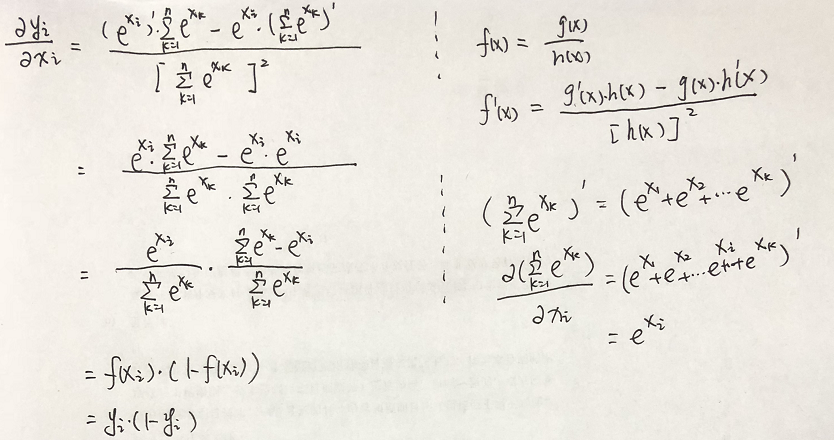
f(xi)對xa求導:
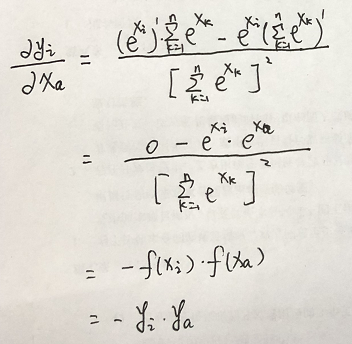
推導:
正向傳播(也就是預測過程,即開始輸入到最後輸出的過程,求y):
y = softmax ( tanh ( x * w1 ) * w2 )後向傳播(求w2,w1):
後向傳播就是倒著推,先推輸出層到含隱層之間的權重w2,那麼假設我們的真實值用大Y表示,我們的預測值用小y表示,那麼他們之間的誤差是Loss = ( Y - y) ,但由於我們softmax函式是指數形式,且本身是概率性問題,我們使用最大似然損失函式(也叫對數似然損失函式),Loss = -ln ( y ) ,(注,在書上見到的log其實就是ln,表示以e為底,表示的含義是,y是當前樣本下預測模型得到的概率) 那麼損失函式Loss =- ln ( y ) ,也就是說,要在損失最小的情況下求引數w2, 求引數求引數還要損失最小,梯度下降就可以了,已知梯度下降公式: w = w - α(∂Loss /∂w); 那麼令 結果 a = tanh(x*w1)* w2 求取過程如下: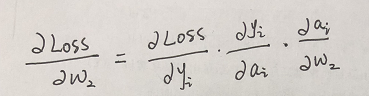
各項如下:
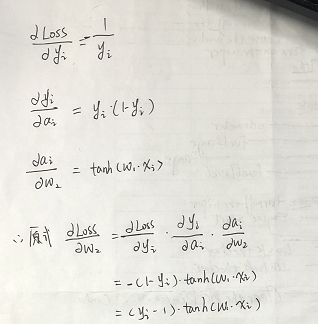 所以:w2 = w2 - α * [ ( yi - 1) * tanh( xi * w1 ) ]
同理,對b2進行求導:
所以:w2 = w2 - α * [ ( yi - 1) * tanh( xi * w1 ) ]
同理,對b2進行求導:
 同理,進行對誤差函式中的w1求導:
同理,進行對誤差函式中的w1求導:
 所以:w1 = w1 - α * [ ( yi - 1 ) * [ 1 - (tanh( w1 * xi ))^2 ] * w2 * xi ]
同理,對b1求導:
所以:w1 = w1 - α * [ ( yi - 1 ) * [ 1 - (tanh( w1 * xi ))^2 ] * w2 * xi ]
同理,對b1求導:
 這樣,後向傳播也推導完了。
這樣,後向傳播也推導完了。
開始部署程式,程式分為以下幾步:
1、獲取資料進行處理 2、softmax公式構建 2.5、引數初始化(主要是權重) 3、前向傳播(就是預測函式)構建 4、後向傳播構建 5、誤差函式構建 5.5、組合函式進行訓練 6、訓練結果評估 7、畫圖 本程式使用以下庫,並使用以下全域性變數:import numpy as np
from sklearn.datasets import make_moons
import matplotlib.pyplot as plt
#學習速率
learning_rate = 0.01
#正則化引數
reg_lambda = 0.01
#特徵資料
data_x = []
#data_y對應結果,mat_data_y結果的表示矩陣形式
data_y = []
mat_data_y = []
#權重引數
weights1 = []
weights2 = []
b1 = []
b2 = []
#誤差
loss = []
第一步,資料獲取:
def get_data():
global data_x,data_y
np.random.seed(0)
data_x, data_y = make_moons(200, noise=0.20)
max_y = max(data_y)
m = len(data_x)
第二步,數學公式構建(我們只需要構建最後的分類函式softmax):
#定義softmax函式
def softmax(x):
return np.exp(x)/(np.sum( np.exp(x) ,axis=1,keepdims=True))
第二點五步,引數初始化(主要是權重):
#input_layout_num是輸入層層數,hide_layout_num是含隱層層數,output_layout_num是輸出層層數
def set_params(hide_layout_num = 3 ):
global weights1, weights2 ,b1 ,b2
input_layout_num = len(data_x[0])
output_layout_num = len(mat_data_y[0])
# weights1 = np.ones((input_layout_num, hide_layout_num))
# weights2 = np.ones((hide_layout_num, output_layout_num))
weights1 = np.random.randn(input_layout_num, hide_layout_num)/ np.sqrt(input_layout_num)
weights2 = np.random.randn(hide_layout_num, output_layout_num)/np.sqrt(hide_layout_num)
# print(weights1)
# weights1 = np.ones((input_layout_num, hide_layout_num))
b1 = np.zeros((1,hide_layout_num))
b2 = np.zeros((1,output_layout_num))
#前向傳播計算
def forward_propagation():
input_hide_calc_pe = np.dot(data_x ,weights1) + b1 #input_hide_calc_pe為輸入層和含隱層之間的引數方程計算值
hide_activation_val = np.tanh(input_hide_calc_pe)#hide_activation_val是含隱層啟用函式值
hide_output_calc_pe = np.dot(hide_activation_val, weights2) + b2#hide_output_calc_pe是含隱層和輸出層之間的引數方程計算值
output_proba = softmax(hide_output_calc_pe)#out_proba是最後選擇softmax函式計算出的概率,也就是預測值
return hide_activation_val,output_proba
#預測函式
def predict(x):
input_hide_calc_pe = np.dot(x ,weights1) + b1 #input_hide_calc_pe為輸入層和含隱層之間的引數方程計算值
hide_activation_val = np.tanh(input_hide_calc_pe)#hide_activation_val是含隱層啟用函式值
hide_output_calc_pe = np.dot(hide_activation_val, weights2) + b2#hide_output_calc_pe是含隱層和輸出層之間的引數方程計算值
output_proba = softmax(hide_output_calc_pe)#out_proba是最後選擇softmax函式計算出的概率,也就是預測值
result = np.max(output_proba,axis=1)
kind = np.argmax(output_proba,axis=1)
print(output_proba)
print("預測結果為第:" + str( kind) + "類\n"
+"預測係數為:" + str(result) )
return kind#返回每一組中最大數值對應位置的索引
#後向傳播計算,output_proba輸出層計算出的概率
def back_propagation( hide_activation_val, output_proba):
global weights2,weights1,b1,b2
feature_x_len,feature_x0_len = np.shape(data_x)
delta_w2_1 = output_proba
#(yi - 1 )
for i in range(feature_x_len):
delta_w2_1[i][data_y[i]] = delta_w2_1[i][data_y[i]] - 1
# (yi - 1 ) * tanh(w1 * xi)
delta_w2 = np.dot(hide_activation_val.T, delta_w2_1)
#b2 = yi - 1
delta_b2 = np.sum(delta_w2_1,axis=0,keepdims=True)
#[ ( yi - 1 ) * [ 1 - (tanh( w1 * xi ))^2 ] * w2 * xi ]
#1 - (tanh( w1 * xi ))^2
delta_w1_2 = (1 - hide_activation_val**2)
delta_w1_1 = np.dot(delta_w2_1 ,weights2.T)
delta_w1_3 = delta_w1_1 * delta_w1_2
delta_w1 = np.dot(data_x.T,delta_w1_3)
delta_b1 = np.sum(delta_w1_3,axis=0,keepdims=True)
delta_w2 = delta_w2 + reg_lambda * weights2
delta_w1 = delta_w1 + reg_lambda * weights1
weights1 = weights1 - learning_rate * delta_w1
b1 = b1 - learning_rate * delta_b1
weights2 = weights2 - learning_rate * delta_w2
b2 = b2 - learning_rate * delta_b2
第五步,誤差函式構建:
#誤差函式
def loss_func():
global loss
#Loss = - ln p(y|x) = - ln yi
loss_sum = 0.0
hide_activation_val, output_proba = forward_propagation()
for i in range(len(data_x)):
loss_sum = loss_sum + -1 * np.log( output_proba[i][data_y[i]] )
loss.append(1/len(data_x) * loss_sum)
第五點五步,訓練:
def train(iter_num = 1,hide_layout_num = 3):
set_params(hide_layout_num)
for i in range(iter_num):
hide_activation_val,output_proba = forward_propagation()
back_propagation(hide_activation_val,output_proba)
loss_func()
第六步,訓練結果評估:
#評估訓練結果
def train_result_evaluate():
hide_activation_val, output_proba = forward_propagation()
output_result = np.argmax(output_proba,axis=1) #返回每一組中最大數值對應位置的索引
x_num = len(output_result)
real_num = 0.0
for i in range(x_num):
if output_result[i] == data_y[i]:
real_num += 1.0
score = real_num / x_num
print("本次樣本數共:" + str(x_num) + "個\n"
+"訓練後預測正確數量:"+ str(real_num) + "個\n"
+"正確率為:" + str(score * 100 ) + r'%' )
#畫決策邊界
def show_decision_pic():
# Set min and max values and give it some padding
x_max = max(data_x[:,0]) + 0.5
x_min = min(data_x[:,0]) - 0.5
y_max = max(data_x[:,1]) + 0.5
y_min = min(data_x[:,1]) - 0.5
range_space = 0.01
# Generate a grid of points with distance h between them
feature_x1 = np.arange(x_min, x_max, range_space) #其橫向特徵最大最小生成的範圍值
feature_x2 = np.arange(y_min, y_max, range_space) #其縱向特徵最大最小生成的範圍值
x1, x2 = np.meshgrid(feature_x1, feature_x2) #將特徵變化成行列相等的矩陣
# Predict the function value for the whole gid
feature = np.c_[x1.ravel(), x2.ravel()] #拼接成二維矩陣
print(np.shape(feature))
Z = predict(feature)
print(Z)
Z = Z.reshape(x1.shape)
# Plot the contour and training examples
plt.contour(feature_x1, feature_x2, Z)
plt.scatter(data_x[:, 0], data_x[:, 1], c=data_y, cmap=plt.cm.Spectral)
plt.show()
def show_loss_pic():
plt.figure(2)
plt.plot(loss)
plt.show()
執行程式:
if __name__ == "__main__":
get_data()
train(iter_num=20000,hide_layout_num=3)
print("初始loss:" + str(loss[0]))
print("最終loss:" + str(loss[-1]))
train_result_evaluate()
show_decision_pic()
show_loss_pic()
#這裡進行一個單點預測
predict(data_x[-5])
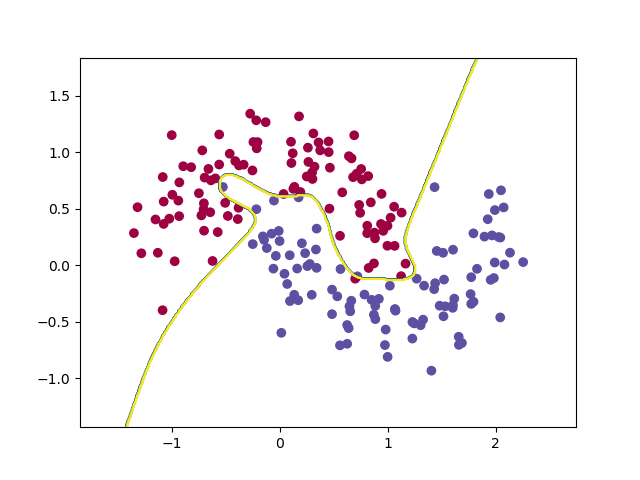
看一下結果:
決策邊界如下: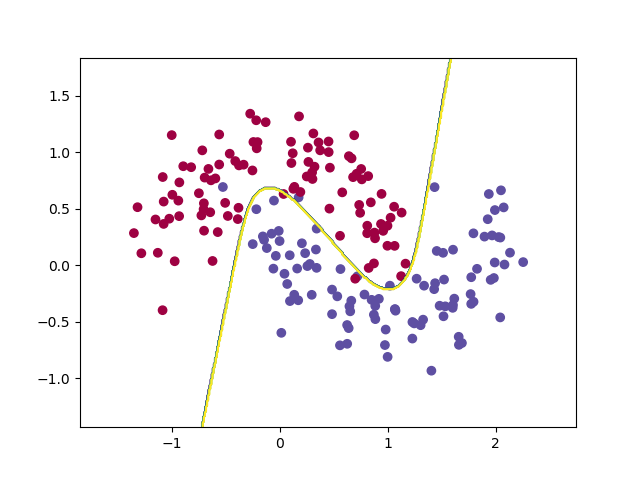
誤差損失逐漸收斂:
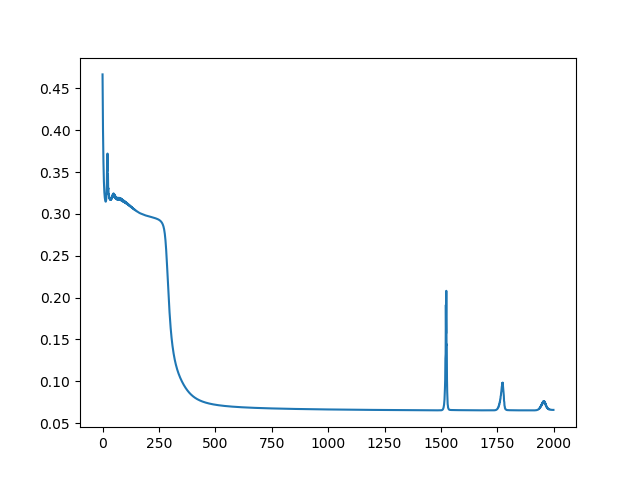
誤差值:
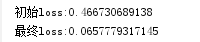
評估結果:

最後的單點預測(因為兩類分別是用0和1表示的,所以第一類是第[0]類,第二類是第[1]類):

關於關於程式中權重初始化的說明(對應在set_param函式): 關於程式中,權重為什麼是這樣設定,還不是像基礎的機器學習方法,設定全0或全1矩陣,原因就是因為,如果設定相同矩陣,那麼所有神經元計算出來的結果是一樣的,反向傳播時,計算的梯度就一樣了,引數就會一樣,具體說明,請參考引用【4】. 寫在最後,可以看出來,神經網路的計算比之前基礎機器學習稍稍複雜一些,但套路還是一樣的,就是多了一點,但好處也可以從圖中看出來,尤其是和之前的邏輯迴歸比較後更容易得出鮮明結論,神經網路省去了找尋複雜特徵方程的選擇,神經元的多少就會決定自己處理的特徵的複雜度。 比如使用30層含隱層,迭代2w次,看下效果
 但這樣的情況,就過擬合了,並不平滑,這樣做出來的權重和函式,就不是預測了,無法體現我們做出來的東西的是具有通用適配性的。
但這樣的情況,就過擬合了,並不平滑,這樣做出來的權重和函式,就不是預測了,無法體現我們做出來的東西的是具有通用適配性的。
相關推薦
【機器學習】--神經網路(NN)
簡單介紹: 神經網路主要是預設人類腦結構進行的一種程式碼程式結構的表現,同時是RNN,CNN,DNN的基礎。結構上大體上分為三個部分(輸入,含隱,輸出),各層都有個的講究,其中,輸入層主要是特徵處理後的入口,含隱層用來訓練相應函式,節點越多,訓練出的函式就越複雜,
【機器學習】神經網路DNN的正則化
和普通的機器學習演算法一樣,DNN也會遇到過擬合的問題,需要考慮泛化,之前在【Keras】MLP多層感知機中提到了過擬合、欠擬合等處理方法的問題,正則化是常用的手段之一,這裡我們就對DNN的正則化方法做一個總結。 1. DNN的L1&L2正則化 想到正則化,我們首先想到的就是L1正則化和L2正則化
【機器學習】神經網路(一)——多類分類問題
一、問題引入 早在監督學習中我們已經使用Logistic迴歸很好地解決二類分類問題。但現實生活中,更多的是多類分類問題(比如識別10個手寫數字)。本文引入神經網路模型解決多類分類問題。 二、神經網路模型介紹 神經網路模型是一個非常強大的模型,起源於嘗試讓機
【機器學習】神經網路及BP推導
1 前向傳播 這裡的推導都用矩陣和向量的形式,計算單個變數寫起來太麻煩。矩陣、向量求導可參見上面參考的部落格,個人覺得解釋得很直接很好。 前向傳播每一層的計算如下: z(l+1)=W(l,l+1)a(l)+b(l,l+1)(1.1) a(l+
【深度學習】神經網路的優化方法
前言 \quad\quad 我們都知道,神經網路的學習目的是找到使損失函式的值儘可能小的引數,這是一個尋找最優引數的
【深度學習】神經網路的學習過程
神經網路的學習 \quad\quad 線上性可分的與非門、或門的感知機模型中,我們可以根據真值表人工設定引數來實現,
【深度學習】神經網路
原址:http://tieba.baidu.com/p/3013551686?pid=49703036815&see_lz=1# 我們先從迴歸(Regression)問題說起,要讓機器學會觀察並總結規律的言論。具體地說,要讓機器觀察什麼是圓的,什麼是方的,區分各種顏
【GitChat】從機器學習到神經網路
訂閱地址:從機器學習到神經網路 人工智慧已經是各大媒體經常聚焦的話題,人工智慧、機器學習、深度學習與神經網路之間究竟是怎樣的關係? 神經網路是深度學習的重要基礎,作為實現人工智慧的技術之一,曾經在歷史的長河中沉睡了數十年,為何又能夠重新甦醒、熠熠生輝。本文將詳細介紹神經網路的前生今世
【機器學習】動手寫一個全連線神經網路(三):分類
我們來用python寫一個沒有正則化的分類神經網路。 傳統的分類方法有聚類,LR邏輯迴歸,傳統SVM,LSSVM等。其中LR和svm都是二分類器,可以將多個LR或者svm組合起來,做成多分類器。 多分類神經網路使用softmax+cross entropy組
【機器學習】搭建神經網路筆記
一、簡單寫一個迴歸方程 import tensorflow as tf import numpy as np #creat data x_data = np.random.rand(100).astype(np.float32)#在x中生成隨機數,隨機數以np的float32型別展示 y_
【機器學習】人工神經網路(ANN)淺講
神經網路是一門重要的機器學習技術。它是目前最為火熱的研究方向--深度學習的基礎。學習神經網路不僅可以讓你掌握一門強大的機器學習方法,同時也可以更好地幫助你理解深度學習技術。 本文以一種簡單的,循序的方式講解神經網路。適合對神經網路瞭解不多的同學。本文對閱讀沒有一定的前提
【2014.10】神經網路中的深度學習綜述
本綜述的主要內容包括: 神經網路中的深度學習簡介 神經網路中面向事件的啟用擴充套件表示法 信貸分配路徑(CAPs)的深度及其相關問題 深度學習的研究主題 有監督神經網路/來自無監督神經網路的幫助 FNN與RNN中用於強化學習RL
【機器學習】生成式對抗網路模型綜述
生成式對抗網路模型綜述 摘要 生成式對抗網路模型(GAN)是基於深度學習的一種強大的生成模型,可以應用於計算機視覺、自然語言處理、半監督學習等重要領域。生成式對抗網路最最直接的應用是資料的生成,而資料質量的好壞則是評判GAN成功與否的關鍵。本文介紹了GAN最初被提出時的基本思想,闡述了其一步
【CV知識學習】神經網路梯度與歸一化問題總結+highway network、ResNet的思考
目錄 一、梯度消失/梯度爆炸的問題 二、選擇其他啟用函式 三、層歸一化 四、權值初始化 五、調整網路的結構 一、梯度消失/梯度爆炸的問題 首先來說說梯度消失問題產生的原因吧,雖然是已經被各大牛說爛的東西。不如先看一個簡單的網路
【機器學習】k-近鄰演算法(k-nearest neighbor, k-NN)
前言 kk近鄰學習是一種常用的監督學習方法。 kk近鄰法的輸入為例項的特徵向量,對應於特徵空間的點;輸出為例項的類別,可以取多類。 kk近鄰法的工作機制很簡單:給定測試樣本,基於某種距離度量(關於
【機器學習】隨機森林 Random Forest 得到模型後,評估參數重要性
img eas 一個 increase 裏的 sum 示例 增加 機器 在得出random forest 模型後,評估參數重要性 importance() 示例如下 特征重要性評價標準 %IncMSE 是 increase in MSE。就是對每一個變量 比如 X1
【機器學習】主成分分析PCA(Principal components analysis)
大小 限制 總結 情況 pca 空間 會有 ges nal 1. 問題 真實的訓練數據總是存在各種各樣的問題: 1、 比如拿到一個汽車的樣本,裏面既有以“千米/每小時”度量的最大速度特征,也有“英裏/小時”的最大速度特征,
【機器學習】1 監督學習應用與梯度下降
例如 tla ges 機器 fprintf lns 找到 輸入 style 監督學習 簡單來說監督學習模型如圖所示 其中 x是輸入變量 又叫特征向量 y是輸出變量 又叫目標向量 通常的我們用(x,y)表示一個樣本 而第i個樣本 用(x(i),y(i))表示 h是輸出函
【機器學習】EM的算法
log mea www 優化 問題 get href ive 路線 EM的算法流程: 初始化分布參數θ; 重復以下步驟直到收斂: E步驟:根據參數初始值或上一次叠代的模型參數來計算出隱性變量的後驗概率,其實就是隱性變量的期望。作為隱藏變量的
【機器學習】DBSCAN Algorithms基於密度的聚類算法
多次 使用 缺點 有效 結束 基於 需要 att 共享 一、算法思想: DBSCAN(Density-Based Spatial Clustering of Applications with Noise)是一個比較有代表性的基於密度的聚