
[線性相關] 皮爾森相關係數的計算及假設檢驗
皮爾森相關係數,又稱積差相關係數、積矩相關係數,可以看做將兩組資料首先做Z分數處理之後, 然後兩組資料的乘積和除以樣本數Z分數一般代表正態分佈中, 資料偏離中心點的距離.等於變數減掉平均數再除以標準差。按照大學的線性數學水平來理解, 它比較複雜一點,可以看做是兩組資料的向量夾角的餘弦。
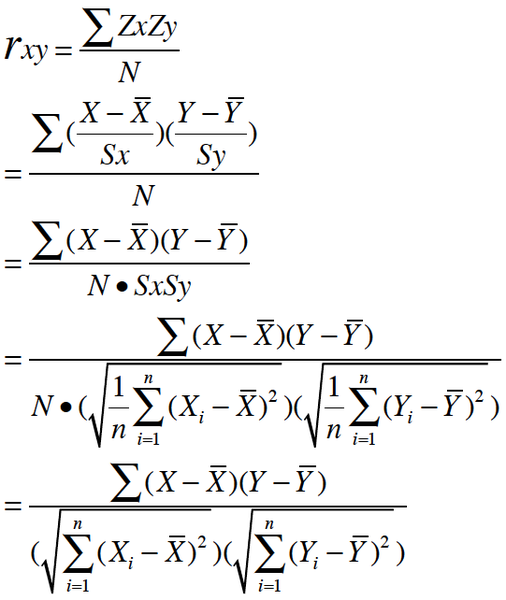
從以上解釋,也可以理解皮爾遜相關的約束條件:
1、兩個變數間有線性關係
2、變數是連續變數
3、兩個變數的總體均符合正態分佈:取大樣本進行正態分佈非引數檢驗
4、兩變數獨立
在實踐統計中,一般只輸出兩個係數,一個是相關係數,也就是計算出來的相關係數大小,在-1到1之間;另一個是獨立樣本檢驗係數,用來檢驗樣本一致性。
現舉例說明計算相關係數的一般步驟:
例9.1 測定15名健康成人血液的一般凝血酶濃度(單位/毫升)及血液的凝固時間(秒),測定結果記錄於表9.1第(2)、(3)欄,問血凝時間與凝血酶濃度間有無相關?
1.繪圖,將表9.1第(2)、(3)欄各對資料繪成散點圖。
2.求出∑X、∑Y、∑X2、∑Y2、∑XY,見表9.1下方。
3,代入公式,求出r值。
表9.1 相關係數計算表
|
受試者號 |
凝血酶濃度(單位/毫升)X |
凝血時間(秒)Y |
|
1 |
1.1 |
14 |
|
2 |
1.2 |
13 |
|
3 |
1.0 |
15 |
|
4 |
0.9 |
15 |
|
5 |
1.2 |
13 |
|
6 |
1.1 |
14 |
|
7 |
0.9 |
16 |
|
8 |
0.9 |
15 |
|
9 |
1.0 |
14 |
|
10 |
0.9 |
16 |
|
11 |
1.1 |
15 |
|
12 |
0.9 |
16 |
|
13 |
1.1 |
14 |
|
14 |
1.0 |
15 |
|
15 |
0.8 |
17 |
|
合計 |
15.1 |
222 |
∑X=15.1 ∑Y=222
∑XY=221.7
∑X2=15.41∑Y2=3304
本例的相關係數r=-0.9070,負值表示血凝時間隨凝血酶濃度的增高而縮短;絕對值∣-0.9070∣表示這一關係的密切程度。至於此相關係數是否顯著,則要經過下面的分析。
(二)相關係數的假設檢驗
雖然樣本相關係數r可作為總體相關係數ρ的估計值,但從相關係數ρ=0的總體中抽出的樣本,計算其相關係數r,因為有抽樣誤差,故不一定是0,要判斷不等於0的r值是來自ρ=0的總體還是來自ρ≠0的總體,必須進行顯著性檢驗。檢驗假設是ρ=0,r與0的差別是否顯著要按該樣本來自ρ=0的總體概率而定。如果從相關係數ρ=0的總體中取得某r值的概率P>0.05,我們就接受假設,認為此r值的很可能是從此總體中取得的。因此判斷兩變數間無顯著關係;如果取得r值的概率P≤0.05或P≤0.01,我們就在α=0.05或α=0.01水準上拒絕檢驗假設,認為該r值不是來自ρ=0的總體,而是來自ρ≠0的另一個總體,因此就判斷兩變數間有顯著關係。
由於來自ρ-0的總體的所有樣本相關係數呈對稱分佈,故r的顯著性可用t檢驗來進行。本例r=-0.9070,進行t檢驗的步驟為:
1.建立檢驗假設,H0:ρ=0,H1:ρ≠0,α=0.01
2.計算相關係數的r的t值:

3.查t值表作結論
ν=n-2=15-2=13
根據專業知識知道凝血酶濃度與凝血時間之間不會呈正相關,故宜用單側界限,查t值表得
t0.01,13=2.650
今∣tr∣>t0.01,13,P<0.01,在α=0.01水準上拒絕H0,接受H1,故可認為凝血時間的長短與血液中酶濃度有負相關。
為簡化tr檢驗的計算過程,數理統計工作者根據t分配表,已把不同自由度時r的臨界值求出,並列成相關係數界值表(見附表11)。故求相關係數後,只需查表就可知道該r值是否顯著,而不必再計算tr值。
r的顯著性界限為
|r|<r0.05, P>0.05 相關不顯著
r0.05≤|r|<r0.01,0.05≥P>0.01 在α=0.05水準上相關顯著
|r|≥r0.01,P≤0.01 在α=0.01水準上相關顯著
例9.1的ν =15-2=13,查附表11中P(1)的界值,得:
r0.05,13=0.441 r0.01,13=0.592
現r=-0.9070,∣r∣>r0.01,13,P<0.01,按α=0.01水準,拒絕HO,接受H1。認為ρ≠0,說明凝血時間的長短與血液中凝血酶濃度有負相關。結論與計算所得一致。
相關係數的顯著性與自由度的大小有關,如n=3,ν=1時,雖r=-0.9070,卻為不顯著;若ν=400時,即使r=0.1000,亦為顯著。因此不能只看r的值,不考慮ν就下結論。
相關推薦
[線性相關] 皮爾森相關係數的計算及假設檢驗
皮爾森相關係數,又稱積差相關係數、積矩相關係數,可以看做將兩組資料首先做Z分數處理之後, 然後兩組資料的乘積和除以樣本數Z分數一般代表正態分佈中, 資料偏離中心點的距離.等於變數減掉平均數再除以標準差。按照大學的線性數學水平來理解, 它比較複雜一點,可以看做是兩組資料的向量
[秩相關] Spearman秩相關係數計算及假設檢驗
首先說明秩相關係數還有其他型別,比如kendal秩相關係數。 使用Pearson線性相關係數有2個侷限: 必須假設資料是成對地從正態分佈中取得的。資料至少在邏輯範圍內是等距的。對於更一般的情況有其他的一些解決方案,Spearman秩相關係數就是其中一種。Spearman秩相
皮爾森相關係數演算法
皮爾森相關係數(Pearson correlation coefficient)也稱皮爾森積矩相關係數(Pearson product-moment correlation coefficient) ,是一種線性相關係數。皮爾森相關係數是用來反映兩個變數線性相關程度的統計量。相關係數用r表示,其中n為樣本
Spearman秩相關係數和Pearson皮爾森相關係數
1、Pearson皮爾森相關係數 皮爾森相關係數也叫皮爾森積差相關係數,用來反映兩個變數之間相似程度的統計量。或者說用來表示兩個向量的相似度。 皮爾森相關係數計算公式如下: 分子是協方差,分母兩個向量的標準差的乘積。顯然是要求兩個向量的標準差不為零
皮爾森相關係數Pearson correlation coefficient
今天老闆突然推薦瞭解下皮爾森相關係數,有些莫名其妙,看了下,就是之前在數理統計裡學到的相關係數,還是比較容易理解的,不過還是寫點記錄下學到的東西吧。 皮爾森相關係數(Pearson correlation coefficient)也稱皮爾森積矩相關係數(P
相關性檢驗--Spearman秩相關係數和皮爾森相關係數
本文給出兩種相關係數,係數越大說明越相關。你可能會參考另一篇部落格獨立性檢驗。 皮爾森相關係數 皮爾森相關係數(Pearson correlation coefficient)也叫皮爾森積差相關係數(Pearson product-moment correlation coefficient),是用來反應兩
推薦演算法之-皮爾遜相關係數計算兩個使用者喜好相似度
<?php /** * 餘玄相似度計算出3個使用者的相似度 * 通過7件產品分析使用者喜好相似度 * 相似度使用函式 sim(user1,user2) =cos∂ * * 設A、B為多維
皮爾遜相關係數的計算(python程式碼版)
作者簡介 南京大學,簡稱南大,[1] 是一所源遠流長的高等學府。追溯學脈古為源自孫吳永安元年的南京太學,歷經多次變遷,1949年“國立中央大學”易名“國立南京大學”,翌年徑稱“南京大學”,沿用至今。南京大學是教育部與江蘇省共建的全國重點大學,國家首批“211工程”、“9
統計學三大相關係數之皮爾森(pearson)相關係數
最早接觸pearson相關係數時,是和同學一起搞數學建模,當時也是需要一種方法評價兩組資料之間的相關性,於是找到了皮爾森(pearson)相關係數和斯皮爾曼(spearman)相關係數。其實,還有一種相關係數肯德爾(kendall)相關係數。在這三大相關係數中,sp
【Python學習筆記】使用Python計算皮爾遜相關系數
自己 pre 求和 相關 學習筆記 python學習 tip urn pow 源代碼不記得是哪裏獲取的了,侵刪。此處博客僅作為自己筆記學習。 def multipl(a,b): sumofab=0.0 for i in range(len(a)):
Pearson(皮爾遜)相關係數
統計相關係數簡介 由於使用的統計相關係數比較頻繁,所以這裡就利用幾篇文章簡單介紹一下這些係數。 相關係數:考察兩個事物(在資料裡我們稱之為變數)之間的相關程度。 如果有兩個變數:X、Y,最終計算出的相關係數的含義可以
皮爾遜相關係數和餘弦相似度
先看看二者定義,給定兩個n維向量A,B: A=(a1,a2,…,an)A = (a_1, a_2, \ldots ,a_n)A=(a1,a2,…,an) B=(b1,b2,…,bn)B = (b_1, b_2, \ldots ,b_n)B=(b1,b2
【126】TensorFlow 使用皮爾遜相關係數找出和標籤相關性最大的特徵值
在實際應用的時候,我們往往會收集多個維度的特徵值。然而這些特徵值未必都能派上用場。有些特徵值可能和標籤沒有什麼太大關係,而另外一些特徵值可能和標籤有很大的相關性。相關性不大的特徵值對於訓練模型沒有太大用處,還會影響效能。因此,最佳方式是找到相關性最大的幾個特
集體智慧程式設計-皮爾遜相關係數程式碼理解
剛開始看關於皮爾遜相關係數計算的程式碼,把我看得是暈頭轉向,不過在學習完概率論的課程後,發現結合公式再來看程式碼就會比較簡單了。 期望公式 E(x)=1n∑i=1nxi 方差公式 var(x)=
如何通俗易懂地理解皮爾遜相關係數?
要理解 Pearson 相關係數,首先要理解協方差(Covariance)。協方差表示兩個變數 X,Y 間相互關係的數字特徵,其計算公式為: COV(X,Y)=1n−1∑n1(Xi−X⎯⎯⎯)(Yi−Y⎯⎯⎯) 當 Y = X 時,即與方差相同。當變數 X,
資料探勘之曼哈頓距離、歐幾裡距離、明氏距離、皮爾遜相關係數、餘弦相似度Python實現程式碼
# -*- coding:utf8 -*- from math import sqrt users = {"Angelica": {"Blues Traveler": 3.5, "Broken Bells": 2.0, "Norah Jones": 4.5, "Phoeni
皮爾遜相關係數 定義+python程式碼實現 (與王印討論公式)
作者簡介 南京大學,簡稱南大,[1] 是一所源遠流長的高等學府。追溯學脈古為源自孫吳永安元年的南京太學,歷經多次變遷,1949年“國立中央大學”易名“國立南京大學”,翌年徑稱“南京大學”,沿用至今。南京大學是教育部與江蘇省共建的全國重點大學,國家首批“211工程”、“9
利用皮爾遜相關係數找出與目標最相關的特徵(Python實現)
#coding:utf-8 #檢測各特徵和輻照度之間的相關性以及各個特徵之間的相關性 from __future__ import division import tensorflow as tf import math import csv from sklearn imp
marchine learning 之 皮爾遜相關係數
/**皮爾遜相關係數 * ρ =(∑xy - ∑x∑y/n)/(∑x^2 - (∑x)^2/n)(∑y^2-(∑y)^2/n)^0.5 */ public class PersonCorrelati
①協方差、相關係數(皮爾遜相關係數),等同於:內積、餘弦值。
假設三維空間裡有很多點,每個點都是用三個維度來表示的。但你發現其實他們差不多都在同一個二維平面上。雖然不是完全在一個平面上,但距離那個平面的距離都很小,遠小於他們在這個平面上的互相距離。於是你想,如果把所有點都投影到這個二維平面,那你就可以用兩個維度來表示所有點,同時又不損失太多關於這些點的資訊。當你這麼做的