
AI - MLCC08 - 表示法 (Representation)
原文鏈接:https://developers.google.com/machine-learning/crash-course/representation/
1- 特征工程
機器學習的關註點是特征表示,也就是說,開發者通過添加和改善特征來調整模型。
將原始數據映射到特征
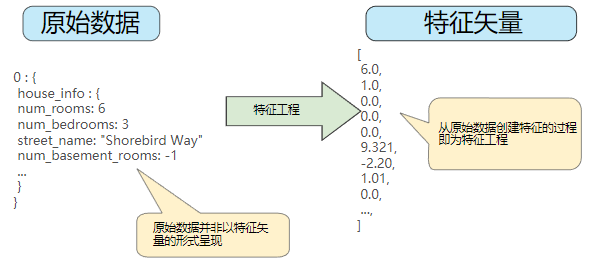
左側表示來自輸入數據源的原始數據,右側表示特征矢量,也就是組成數據集中樣本的浮點值集。
特征工程指的是將原始數據轉換為特征矢量,也就是說,是將原始數據映射到機器學習特征。
進行特征工程預計需要大量時間。
許多機器學習模型都必須將特征表示為實數向量,因為特征值必須與模型權重相乘。
映射數值
整數和浮點數據不需要特殊編碼,因為它們可以與數字權重相乘。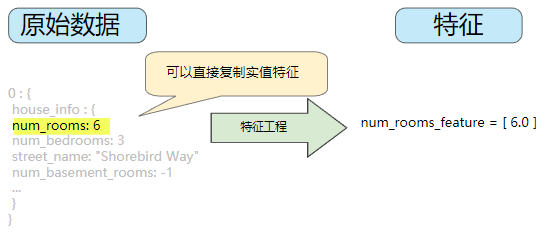
映射分類值
分類特征具有一組離散的可能值。
由於模型不能將字符串與學習到的權重相乘,因此使用特征工程將字符串轉換為數字值。
實現方法:
- 定義一個從特征值(可能值的詞匯表)到整數的映射。
- 將所有其他可能值詞匯分組為一個全部包羅的“其他”類別,稱為 OOV(詞匯表外)分桶。
但如果將這些索引數字直接納入到模型中,將會造成一些可能存在問題的限制:
- 模型沒有靈活地學習不同的權重,而是學習了適用於所有可能值的單一權重
- 特征值可能有多個值
如何去除以上限制?
可以為模型中的每個分類特征創建一個二元向量來表示這些值
- 對於適用於樣本的值,將相應向量元素設為 1。
- 將所有其他元素設為 0。
該向量的長度等於詞匯表中的元素數。
當只有一個值為 1 時,這種表示法稱為獨熱編碼;當有多個值為 1 時,這種表示法稱為多熱編碼。
該方法能夠有效地為每個特征值創建布爾變量。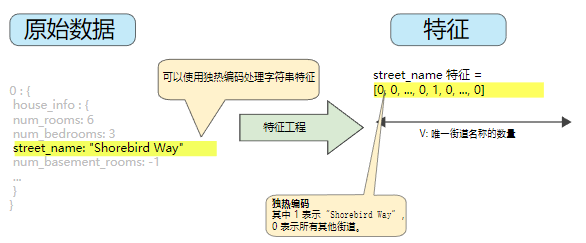
稀疏表示法 (sparse representation)
一種張量表示法,僅存儲非零元素。
可以避免占用大量的存儲空間並耗費很長的計算時間。
在稀疏表示法中,仍然為每個特征值學習獨立的模型權重。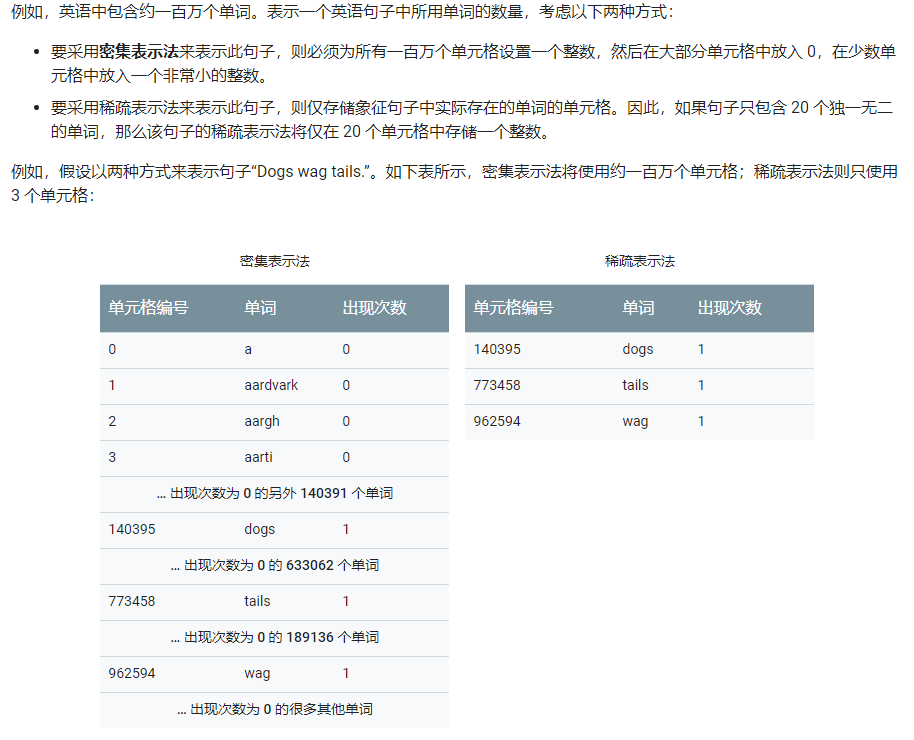
2- 良好特征的特點
什麽樣的值才算特征矢量中良好的特征?
避免很少使用的離散特征值
良好的特征值應該在數據集中出現大約 5 次以上,模型就可以學習該特征值與標簽是如何關聯的。
也就是說,大量離散值相同的樣本可讓模型有機會了解不同設置中的特征,從而判斷何時可以對標簽很好地做出預測。
相反,如果某個特征的值僅出現一次或者很少出現,則模型就無法根據該特征進行預測。
最好具有清晰明確的含義
每個特征對於項目中的任何人來說都應該具有清晰明確的含義。
在某些情況下,混亂的數據(而不是糟糕的工程選擇)會導致含義不清晰的值。
不要將“神奇”的值與實際數據混為一談
良好的浮點特征不包含超出範圍的異常斷點或“神奇”的值。
如果某個特征的值包含“神奇值”,為解決這個問題,需將該特征轉換為兩個特征:
- 一個特征只存儲特征的值,但不含神奇值
- 一個特征存儲布爾值,表示是否提供了該特征
考慮上遊不穩定性
特征的定義不應隨時間發生變化。
例如,城市名稱一般不會改變,但城市的電話號碼前綴這種表示在未來運行其他模型時可能輕易發生變化。
AI - MLCC08 - 表示法 (Representation)