
Python2.7 中文字元編碼 & Pycharm utf-8設定、Unicode與utf-8的區別
Python2.7 中文字元編碼 & Pycharm utf-8設定、Unicode與utf-8的區別
[email protected]
作者:Zhouwan
2017-6-6
一、關於編碼和亂碼,有以下幾個重要的概念需要搞清楚:

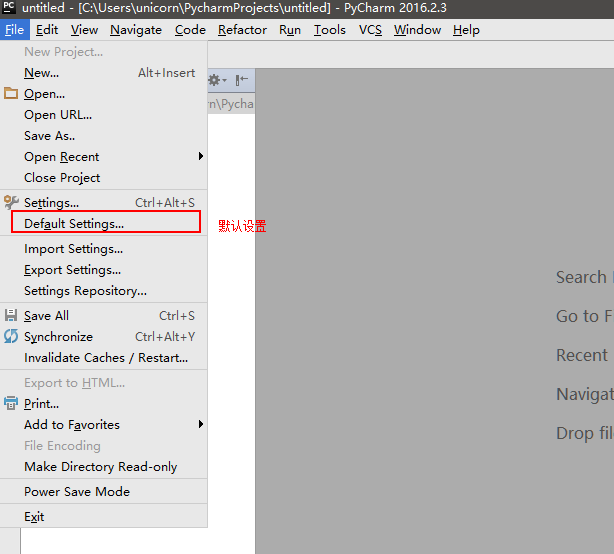
二、Pycharm 設定編碼, 可以按如下步驟設定:
-
Ctrl + Shift + A
-
搜尋
encoding -
把能設定成 utf-8 的地方都設定成 utf-8
想要一勞永逸,就將預設設定裡的encoding都設定為utf-8,如下:
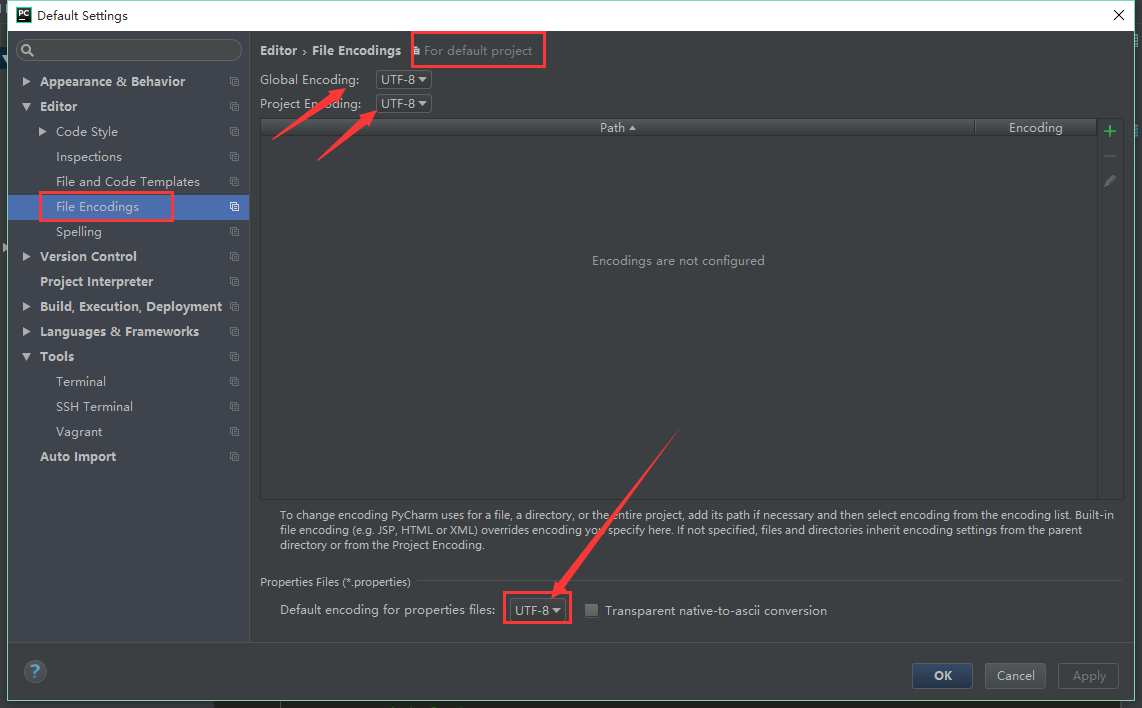
三、關於字符集和編碼的歷史淵源、Unicode和UTF-8的關係,請檢視參考資料第三個連結,講的很好。
參考資料:
相關推薦
Python2.7 中文字元編碼 & Pycharm utf-8設定、Unicode與utf-8的區別
Python2.7 中文字元編碼 & Pycharm utf-8設定、Unicode與utf-8的區別 [email protected] 作者:Zhouwan 2017-6-6 一、關於編碼和亂碼,有以下幾個重要的概念需要搞清楚: 二、Pycharm 設定編碼, 可以
關於字元編碼:ascii、unicode與utf-8
轉自:https://foofish.net/unicode_utf-8.html 阮一峰老師對普及計算機基礎技術功不可沒,但畢竟老師不是神,因此也避免不了對某些概念有一些錯誤的理解,《字元編碼筆記:ASCII,Unicode 和 UTF-8 》 是阮老師10年前寫的一篇關於字元編
字元編碼的發展(ASCII、Unicode、utf-8)
最近一直在看廖雪峰老師的python網上教程,python內容簡單易理解,就沒整理,但是字串編碼作為一直困擾自己的問題,看了幾遍文章,最終還是將其整理如下,本篇部落格總結自廖雪峰老師的網上教程:http://www.liaoxuefeng.com/ 首先我們要明確三者出現的時間依次是:ASCII,Un
字符編碼,ASCII、Unicode與UTF-8的理解
F5 標準化 一般來說 簡書 打開文件 說了 tps can 常用 首先我們先要明白的兩點是:1、計算機中的信息都是由二進制的0和1儲存的;2、我們再計算機屏幕上看到的各種字符都是計算機系統按照一定的規則將二進制數字轉換而來的。 一、基本概念。 1、字符集(charse
python2和python3字元編碼,utf-8,unicode
二進位制 -> 轉換 -> 字串 需要解碼 decode字串 -> 轉換 -> 二進位制 需要編碼 encodepython3 記憶體中使用的字串全部是unicode碼,但是網路傳輸的資料或者從磁碟讀取的資料是把unicode碼轉換過的資料,通常情況下可能是utf-8格式的資料,所以如
mac下mysql 5.7.19字元編碼設定為utf-8的方法
如果你查了一堆,都是說在/etc/資料夾下新增一個my.cnf檔案,然後把下面的命令寫進去就可以了 [client] default-character-set=utf8 [mysql] default-character-set=utf8 [mysqld] coll
中文字元編碼:GB2312、GBK、ANSI、Unicode、UTF-8
字元編碼 windows notepad、windows notepad++和sublime text的字元編碼顯示區別: windows notepad notepad++ su
【轉載】字元編碼中ASCII、Unicode和UTF-8的區別
1. ASCII碼 我們知道,在計算機內部,所有的資訊最終都表示為一個二進位制的字串。每一個二進位制位(bit)有0和1兩種狀態,因此八個二進位制位就可以組合出256種狀態,這被稱為一個位元組(byte)。也就是說,一個位元組一共可以用來表示256種不同的狀態,每一個狀態對應一個符
三種常見字元編碼:ASCII、Unicode和UTF-8
什麼是字元編碼? 計算機只能處理數字,如果要處理文字,就必須先把文字轉換為數字才能處理。最早的計算機在設計時採用8個位元(bit)作為一個位元組(byte),所以,一個位元組能表示的最大的整數就是255(二進位制11111111=十進位制255),如果要表示更大的整數,就必須用更多的位元組。比如
字元編碼:ASCII、Unicode和UTF-8
一、什麼是字元編碼? 字元編碼(英語:Character encoding)也稱字集碼,是把字符集中的字元編碼為指定集合中某一物件(例如:位元模式、自然數序列、8位組或者電脈衝),以便文字在計算機中儲存和通過通訊
字元編碼:ANSI和ASCII區別、Unicode和UTF-8區別
ANSI和ASCII區別 ANSI碼(American National Standards Institute) 美國國家標準學會的標準碼 ASCII碼(America Standard Code
字元編碼ANSI和ASCII區別、Unicode和UTF-8區別
今天看了一個說法,說是入坑windows程式開發,必先掌握文字的編碼和字符集知識。本部落格就整理下資訊儲存和字元編碼的相關知識。 一.位: 計算機儲存資訊的最小單位,稱之為位(bit),音譯位元,二進位制的一個“0”或一個“1”叫一位。 二.位元組 位元
【字元編碼】 ASCII、Unicode和UTF-8
1. ASCII碼 我們知道,在計算機內部,所有的資訊最終都表示為一個二進位制的字串。每一個二進位制位(bit)有0和1兩種狀態,因此八個二進位制位就可以組合出256種狀態,這被稱為一個位元組(byte)。也就是說,一個位元組一共可以用來表示256種不同的狀態,每一個狀態對
Java 字符編碼 ASCII、Unicode和UTF-8
之間 family 打印 com 但是 例如 進制數 英語 utf-16 1 ASCII碼 統一規定英語字符與二進制位之間的關系。ASCII碼一共規定了128個字符的編碼。例如,空格“SPACE”是32(二進制00100000),大寫字母A是65(二進制010000
快速理解編碼,unicode與utf-8
logs 聯網 長度 unicode 為什麽 互聯網 什麽 描述 com 1.為什麽編碼,因為cpu只認識數字2.ASCII 一個字符共占7位,用一個字節表示,共128個字符3.那麽ASCII浪費了最高位多可惜,出現了ISO-8859-1,一個字節,256個字符,很多協議的
tomcat7中文字元編碼問題
關於一次tomcat URI中文編碼問題處理 異常: java.lang.IllegalArgumentException: Invalid character found in the request target. The valid characters are defined in
第7天字元編碼
什麼是字元編碼? 計算機只能識別0和1,當我們與計算機進行互動的時候不可能通過0和1進行互動,因此我們需要一張表把我們人類的語言一一對應成計算機能夠識別的語言,這張表就是我們通常所說的字元編碼表。因為計算機是美國人發明的,在設計之初的時候並未考慮到全世界的情況,所以最開始只有一張ASCII表(這個表只是英
編碼方式ASCII、Unicode和UTF-8的區別及聯絡
最早的計算機在設計時採用8個位元(bit)作為一個位元組(byte),所以,一個位元組能表示的最大的整數就是255(二進位制11111111=十進位制255),如果要表示更大的整數,就必須用更多的位元組。比如兩個位元組可以表示的最大整數是65535,4個位元組可以表示的最大整
中文字元編碼簡介 GB2312/GBK/GB18030/BIG5
2 GBKGB2312-80僅收漢字6763個,這大大少於現有漢字,隨著時間推移及漢字文化的不斷延伸推廣,有些原來很少用的字,現在變成了常用字,例如:朱鎔基的“鎔”字,未收入GB2312-80,現在大陸的報業出刊只得使用(金+容)、(金容)、(左金右容)等來表示,形式不一而同,這使得表示、儲存、輸入、處理都非
中文字元編碼的相互轉換(一)
作為程式設計師,在日常的工作中總會遇到編碼的知識。尤其是在前後臺互動的過程中,字元編碼如影隨行。如果多個平臺的字元編碼不一致,需要相互轉化的話,很有必要了解一下編碼的工作原理。網上有太多關於編碼的知識了,在此我儘量按照我對編碼的理解描述的簡單易懂。1,ASCII碼在計算機內