
MapReduce程式設計 一步步地教你開啟 第一個程式wordcount
例項描述
計算出檔案中每個單詞的頻數,要求輸出結果按照單詞的字母順序進行排序,按照key-value格式輸出結果。
比如輸入檔案為:
hello world
hello hadoop
hello mapreduce
輸出檔案為:
hadoop 1
hello 3
mapreduce 1
world 1
設計思路
就是將檔案內容切分成單詞,然後將所有相同的單詞聚集在一起,最後計算單詞出現次數並輸出。 根據MapReduce並行程式設計原則可知,內容切分步驟和資料不相關,可以並行化處理,每個獲得原始 資料的機器只要將資料切分成單詞就行。所以可以在Map階段完成單詞切分任務。另外,相同的單詞 頻數計算也可以進行並行處理。例項來看,不同單詞之間的頻數不相關。所以可以將相同的單詞交給 同一臺機器進行處理,然後輸出結果。這個過程可以在Reduce過程完成。將中間結果在根據不同的 單詞分組分發給不同的機器。
- Map階段:完成由輸入資料到單詞切分工作
- shuffle階段:完成相同單詞的聚集和分發工作
- Reduce階段:負責接收所有單詞,並計數
MapReduce中資料傳遞都是key-value形式。shuffle排序聚集分發是按照key進行排序的
執行步驟
使用eclipse作為編譯工具的:
1,新建MapReduce專案
2,檢查MapReduce jar包集全不
3,寫程式碼
4,配置執行引數
選擇run Configurations
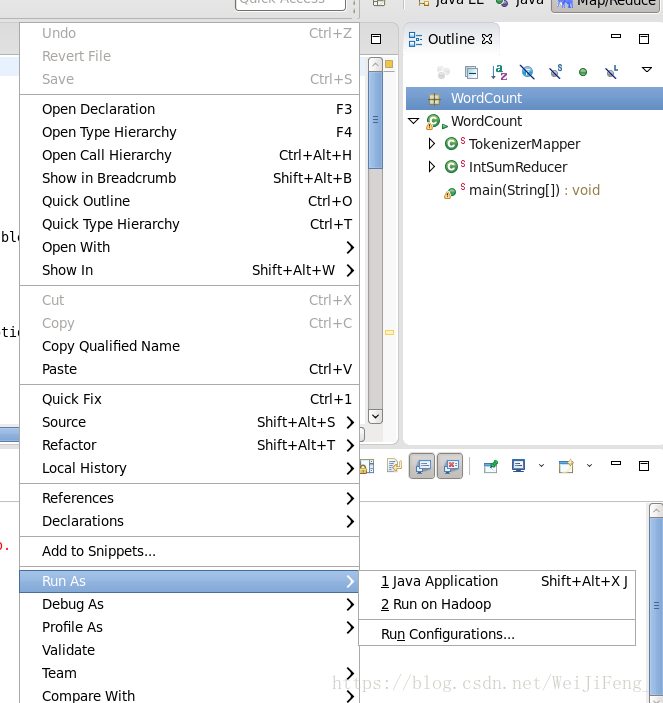
檢查Mian方法路徑
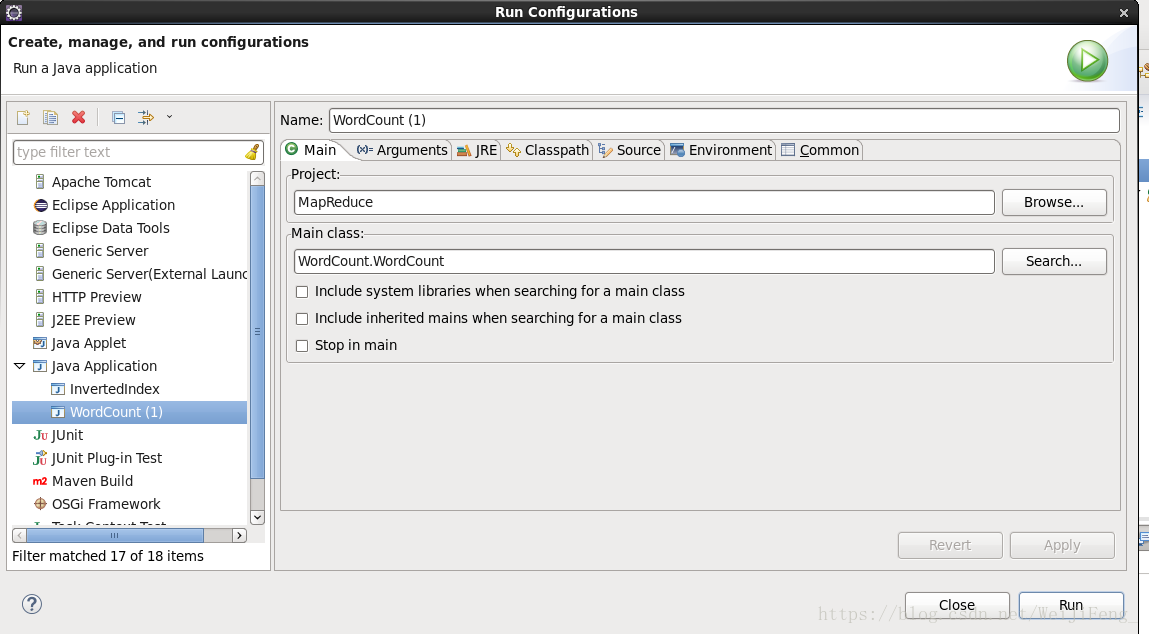
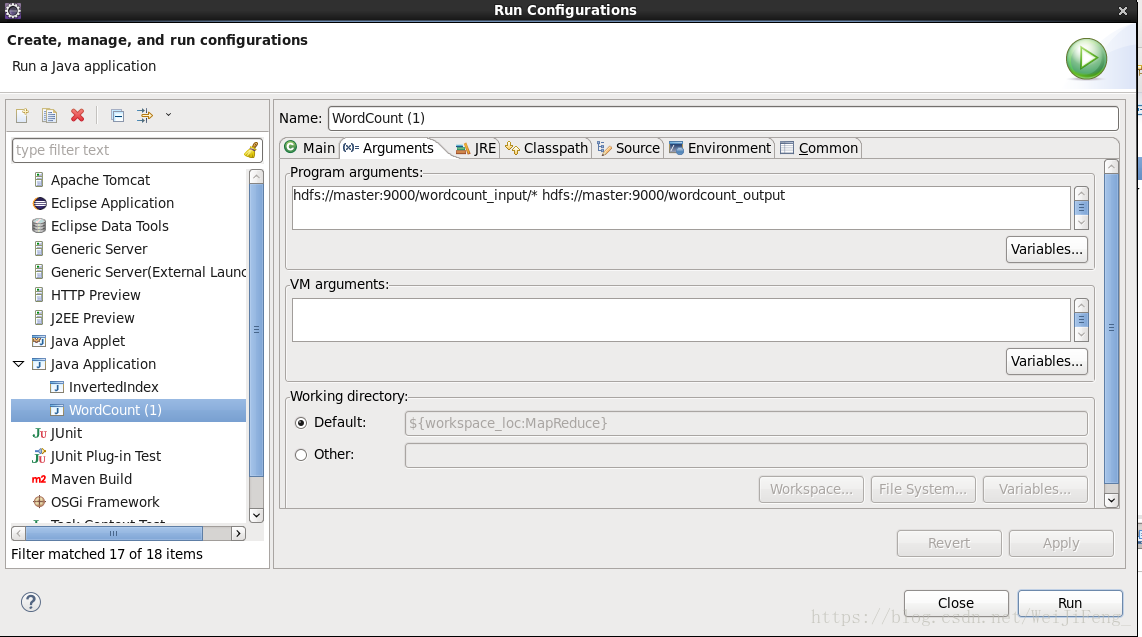
選擇引數欄,第一個為輸入檔案的位置(Liunx上執行支援萬用字元匹配路徑),第二個為輸出檔案位置,在run就能執行了,執行完畢,結果在對應的輸出引數路徑。
使用命令列執行的
1.先新建一個java檔案
2.寫好程式
3.編譯程式
對於hadoop-1.x的編譯指令為(僅為樣例,版本不同,要改版本號)
javac -classpath hadoop-1.0.1-core.jar:lib/commons-cli-1.2.jar -d WordCount WordCount.java對於hadoop-2.x的編譯指令為(僅為樣例,版本不同,要改版本號) javac -classpath $HADOOP_HOME/share/hadoop/common/hadoop-common-2.6.0.jar:$ HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-client-core-2.6.0.jar -d /opt/hadoop-2.6.0-cdh5.6.0/MapReduceClass WordCount.java
這是因為hadoop-2.x版本沒有core jar了,被拆分成多個jar了
打包成jar
jar -cvf wordcount.jar -C WordCount叢集上執行程式
bin/hadoop jar wordcount.jar WordCount wordcount_input wordcount_output檢視結果
bin/hadoop fs -cat wordcount_output/part-r-00000WordCount程式碼
package WordCount;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;
public class WordCount {
//繼承Mapper介面,設定Mapper輸入型別為 Object , Text>
//輸出型別為<Text,IntWritable>
public static class TokenizerMapper extends Mapper<Object,Text,Text,IntWritable>{
//one 表示單詞出現一次
private final static IntWritable one = new IntWritable(1);
//word用於儲存切下的單詞
private Text word = new Text();
public void map(Object key,Text value,Context context) throws IOException,InterruptedException{
StringTokenizer itr = new StringTokenizer(value.toString());
while(itr.hasMoreTokens()){
word.set(itr.nextToken()); //切下的單詞存入word
context.write(word,one);
}
}
}
//繼承Reducer介面,設定Reduce的輸入型別為<Text,IntWritable>
//輸出型別為<Text,IntWritable>
public static class IntSumReducer extends Reducer<Text,IntWritable,Text,IntWritable>{
//result記錄單詞的頻數
private IntWritable result = new IntWritable();
public void reduce(Text key,Iterable<IntWritable> values,Context context) throws IOException,InterruptedException{
int sum = 0;
//對獲取的<key,value-list>計算value的和
for(IntWritable val : values)
{
sum+=val.get();
}
//將頻數設定到result
result.set(sum);
//收集結果
context.write(key,result);
}
}
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
// conf.set("fs.hdfs.impl",org.apache.hadoop.hdfs.DistributedFileSystem.class.getName());
String[] otherArgs = new GenericOptionsParser(conf,args).getRemainingArgs();
if(otherArgs.length != 2){
System.err.println("Usage:wordcount <in> <out>");
System.exit(2);
}
Job job = new Job(conf,"word count");
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job,new Path(args[0]));
FileOutputFormat.setOutputPath(job,new Path(args[1]));
System.exit(job.waitForCompletion(true)?0:1);
}
}總結
對於wordcount這個程式,開啟了我MapReduce程式設計的第一步吧,最開始,看的書是1.0.1版本的
但是自己的環境是2.6.5版本的,在指令上,一直執行問題。後面查了查知道,hadoop-2.x,已經
沒有core jar了。命令列執行一直失敗。後來在進行改進,所以這個問題是很必要注意的
相關推薦
MapReduce程式設計 一步步地教你開啟 第一個程式wordcount
例項描述 計算出檔案中每個單詞的頻數,要求輸出結果按照單詞的字母順序進行排序,按照key-value格式輸出結果。 比如輸入檔案為: hello world hello hadoop hello mapreduce
一步步的教你如何建立第一個APP?-swift
準備好了麼? 準備好建立你的第一個app了麼? 在這個教程中,你會學習到如何建立一個簡單的遊戲,叫做“Tap me",遊戲的玩法是看你在30秒之內可以點選按鈕多少次,來給你評分。
一步一步地教你實現OLE讀取EXCEL(一)
#include "stdafx.h" #include "CExcelFileRead.h" COleVariant covTrue((short)TRUE), covFalse((short)FALSE), covOptional((long)DISP_E_PARAMNOTFOUND, VT_ERRO
一步一步地教你實現OLE讀取EXCEL(二)
在上一篇中本人向大家介紹了OLE讀取EXCEL檔案所用到的動態連結庫的方法!下面這一章節為大家介紹簡單的UI介面以及使用DLL的方法! (一)介面 介面很垃圾,內容很樸實。在lineedit中輸入學生姓名後點擊“開始搜尋”,之後在textedit顯示該學生參加的社會實踐
[C++]多執行緒: 教你寫第一個執行緒
hello thread! 宣告執行緒A的埠號 #include <pthread.h> pthread_t tid; 定義執行緒執行函式 void thread_function(void *args) { printf("th
4分鐘手把手教你做出第一個微信小程式
關於如何開發自己第一個程式,上一篇我釋出了圖文版本,有的閣友自己說沒能實現,我也擔心看圖實在會讓大家感覺不直觀,所以我花了點時間做了一個教學視訊,希望能繼續幫助到對微信小程式感興趣的人。用了愛剪輯稍微做
[原]手把手教你appium_第一個示例日誌解讀
1. 啟動一個http伺服器:127.0.0.1:4723 2. 根據測試程式碼setUp()進行初始化,在http伺服器上建立一個session物件; 3. 開始呼叫adb,找到連線上的裝置,設定裝置id 猜測:這次我只連線了一個模擬器,如果還有多個裝置呢,在第二篇文章中是命令列啟動的,使用了-U
手把手教你selenium_第一個指令碼_登入新浪微博
假定各位以前看過前兩篇文章,已經搭建好了環境,現在開始錄製回放第一個selenium的指令碼:登入新浪微博 基本的步驟是: 1. 開啟firefox,設定seleniumIDE選項,使之可以錄製下junit的程式碼; 2. 使用seleniumIDE進行錄製,
概率論與數理統計(一):教你一步步推貝葉斯公式
參考資料:《概率論與數理統計》 陳希孺 2000.3/2016.8 1,概率是什麼? 概率是表示某種情況出現的可能性大小的一種數量指標,它介於0和1之間。 概
一只兔子教你看盡人生滄海桑田
content size con doc log post style com tar http://www.360doc.com/content/11/0610/09/4358047_122832120.shtml一只兔子教你看盡人生滄海桑田
一張圖教你看懂Java的八種基本資料型別
String和Integer不是Java的八種基本資料型別。char只能儲存一個字元(用單引號),String能夠儲存多個字元(用雙引號)。String屬於final類,定義的是物件,Integer 是 java 為 int 提供的封裝類。int 的預設值為 0,
一片文章教你爬蟲入門,學習原來這麼簡單!
好多朋友在入門python的時候都是以爬蟲入手,而網路爬蟲是近幾年比較流行的概念,特別是在大資料分析熱門起來以後,學習網路爬蟲的人越來越多,哦對,現在叫資料探勘了! 其實,一般的爬蟲具有2個功能:取資料和存資料!好像說了句廢話。。。 而從這2個功能拓展,需要的知識就很
一篇文章教你順利入門和開發chrome擴充套件程式
前言 關於chrome extension的開發經驗總結或說明文件等資料很多,很多人在寫,然而,我也是一員。但是,也許這篇文章,可能給你一些不一樣的感受。 前面部分大多數是一些基礎介紹,和別人的資料大同小異,但是用的是通俗的語言或者我自己理解來描述的,不是拷貝官方的描述,不然的話,你乾脆看官方文件就好啦,幹
一篇文章教你在android studio 成為Gradle高手
昨天我想弄個自動打包的玩意,結果倒騰了半天也沒倒騰好,想了想還是因為自己太懶了不願意去學習Gradle基礎知識,所以我決定今天好好把這方面的知識梳理一遍,說起來熟悉gradle開發還是很有必要的; 當然
教你開啟二維碼和條形碼的正確識別方式
今天老師給了張圖片,裡面有很多二維碼和條形碼,然後說不管大家用什麼辦法,試試看能不能用個程式碼儘可能多的把裡面的二維碼和條形碼資訊讀出來!腦海突然閃現出之前做過的微信自動回覆過程中自動生成的二維碼。但似乎沒太大關係(略略略),二維碼不也是一張圖片嘛,那就影象識別?通過解析來提
純乾貨:手把手地教你搭建Oracle Sharding資料庫分片技術
select TABLESPACE_NAME, BYTES/1024/1024 MB from sys.dba_data_files order by tablespace_name; TABLESPACE_NAME MB ------------------
ffmpeg實戰教程(十一)手把手教你實現直播功能,不依賴第三方SDK
先上圖: 推流的手機 拉流的網頁和VL播放器 拉流的手機客戶端 對於nginx伺服器的搭建之前有寫過: 這篇也建議看一下: 下面開始實現手機直播功能 1
一篇文章教你學會Git
本文轉載於掘金Ruheng,總結非常好,故不再重複造輪子。 在日常工作中,經常會用到Git操作。但是對於新人來講,剛上來對Git很陌生,操作起來也很懵逼。本篇文章主要針對剛開始接觸Git的新人,理解Git的基本原理,掌握常用的一些命令。 一、Git工作流
大資料初學者福利:一片文章教你搭建Hadoop大資料處理環境
由於Hadoop需要執行在Linux環境中,而且是分散式的,因此個人學習只能裝虛擬機器,本文都以VMware Workstation為準,安裝CentOS7,具體的安裝此處不作過多介紹,只作需要用到的知識介紹。 VMware的安裝,裝好一個虛擬機器後利用複製虛擬機器的方式建立後面幾個虛擬機器,省
一篇文章教你使用RDMA技術提升Spark的Shuffle效能
Spark Shuffle 基礎 在 MapReduce 框架中,Shuffle 是連線 Map 和 Reduce 之間的橋樑,Reduce 要讀取到 Map 的輸出必須要經過 Shuffle 這個環節;而 Reduce 和 Map 過程通常不在一臺節點,這意味著 Shuffle 階段通常需要跨網路以及