
Flume+Kafka+Spark Streaming實現大資料實時流式資料採集
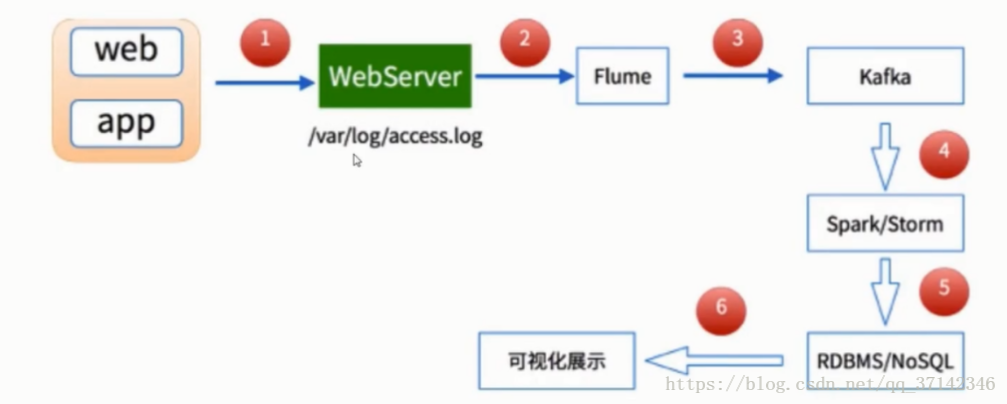
大資料實時流式資料處理是大資料應用中最為常見的場景,與我們的生活也息息相關,以手機流量實時統計來說,它總是能夠實時的統計出使用者的使用的流量,在第一時間通知使用者流量的使用情況,並且最為人性化的為使用者提供各種優惠的方案,如果採用離線處理,那麼等到使用者流量超標了才通知使用者,這樣會使得使用者體驗滿意度降低,這也是這幾年大資料實時流處理的進步,淡然還有很多應用場景。因此Spark Streaming應用而生,不過對於實時我們應該準確理解,需要明白的一點是Spark Streaming不是真正的實時處理,更應該成為準實時,因為它有延遲,而真正的實時處理Storm更為適合,最為典型場景的是淘寶雙十一大螢幕上盈利額度統計,在一般實時度要求不太嚴格的情況下,Spark Streaming+Flume+Kafka是大資料準實時資料採集的最為可靠並且也是最常用的方案,大資料實時流式資料採集的流程圖如下所示:
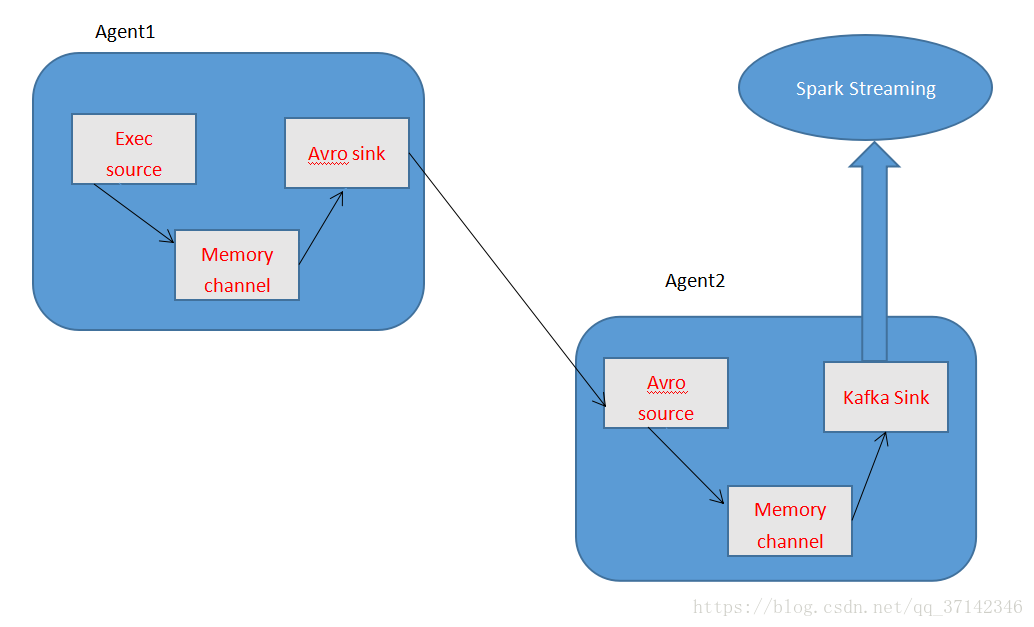
在本篇文章中使用Flume+Kafka+Spark Streaming具體實現大資料實時流式資料採集的架構圖如下:
轉發請標明原文地址:原文地址
對Flume,Spark Streaming,Kafka的配置如有任何問題請參考筆者前面的文章:
開發環境、工具:
- Linux作業系統,JDK環境,SCALA環境、CDH5版本軟體
- Spark
- Kafka_2.10-0.8.2.1
- Flume-1.5.0-cdh5.3.6-bin
- Zookeeper-3.4.5
下面我們就開始進行實戰配置:
Flume檔案配置
首先建立兩個配置檔案分別來啟動兩個Agent。
exec-memory-avro.conf:
# The configuration file needs to define the sources,
# the channels and the sinks.
# Sources, channels and sinks are defined per agent,
# in this case called 'agent'
f1.sources = r1
f1.channels = c1
f1.sinks = k1
#define sources
f1.sources.r1.type = exec
f1.sources.r1.command avro-memory-kafka.conf:
# The configuration file needs to define the sources,
# the channels and the sinks.
# Sources, channels and sinks are defined per agent,
# in this case called 'agent'
f2.sources = r2
f2.channels = c2
f2.sinks = k2
#define sources
f2.sources.r2.type = avro
f2.sources.r2.bind =hadoop-senior.shinelon.com
f2.sources.r2.port =44444
#define channels
f2.channels.c2.type = memory
f2.channels.c2.capacity = 1000
f2.channels.c2.transactionCapacity = 100
#define sink
f2.sinks.k2.type = org.apache.flume.sink.kafka.KafkaSink
f2.sinks.k2.brokerList = hadoop-senior.shinelon.com:9092
f2.sinks.k2.topic =testSpark
f2.sinks.k2.batchSize=4
f2.sinks.k2.requiredAcks=1
#bind sources and sink to channel
f2.sources.r2.channels = c2
f2.sinks.k2.channel = c2上面的配置檔案關鍵需要注意kafka的配置,如有不懂也可參考Flume官方文件的說明。
接著我們啟動Flume,記得首先啟動avro-memory-kafka.conf的Agent:
bin/flume-ng agent
--conf conf --name f2 \
--conf-file conf/avro-memory-kafka.conf \
-Dflume.root.logger=DEBUG,console
bin/flume-ng agent
--conf conf --name f1 \
--conf-file conf/exec-memory-avro.conf \
-Dflume.root.logger=DEBUG,consoleKafka配置
注意:在啟動Kafka之前要啟動Zookeeper
下面就是kafka的配置:
server.properties:
主要注意下面幾個引數的配置,其他的引數預設就好。
broker.id=0
port=9092
host.name=hadoop-senior.shinelon.com
log.dirs=/opt/cdh-5.3.6/kafka_2.10-0.8.2.1/kafka_logs
zookeeper.connect=hadoop-senior.shinelon.com:2181啟動kafka(以後臺程序的方式啟動):
bin/kafka-server-start.sh -daemon config/server.properties &建立topic:
注意topic的名稱,需要與上面Flume中的配置一致,也要與下面Spark Streaming中設定的一致。
bin/kafka-topics.sh --create --zookeeper hadoop-senior.shinelon.com:2181 --replication-factor 1 --partitions 1 --
topic testSparkSpark Streaming配置
首先需要匯入Spark Streaming所需要的jar包並且啟動Spark:
bin/spark-shell --master local[2] --jars \
/opt/cdh-5.3.6/spark-1.3.0-bin-2.5.0-cdh5.3.6/externallibs/spark-streaming-kafka_2.10-1.3.0.jar,/opt/cdh-5.3.6/spark-1.3.0-bin-2.5.0-cdh5.3.6/externallibs/kafka_2.10-0.8.2.1.jar,/opt/cdh-5.3.6/spark-1.3.0-bin-2.5.0-cdh5.3.6/externallibs/kafka-clients-0.8.2.1.jar,/opt/cdh-5.3.6/spark-1.3.0-bin-2.5.0-cdh5.3.6/externallibs/zkclient-0.3.jar,/opt/cdh-5.3.6/spark-1.3.0-bin-2.5.0-cdh5.3.6/externallibs/metrics-core-2.2.0.jar接著編寫指令碼啟動Spark Streaming,這個指令碼使用Spark Streaming實現wordCount功能,程式碼如下:
SparkWordCount.scala:
import java.util.HashMap
import org.apache.spark._
import org.apache.spark.streaming._
import org.apache.spark.streaming.StreamingContext._
import org.apache.spark.streaming.kafka._
val ssc = new StreamingContext(sc, Seconds(5))
val topicMap = Map("testSpark" -> 1)
// read data
val lines = KafkaUtils.createStream(ssc, "hadoop-senior.shinelon.com:2181", "testWordCountGroup", topicMap).map(_._2)
val words = lines.flatMap(_.split(" "))
val wordCounts = words.map(x => (x, 1)).reduceByKey(_ + _)
wordCounts.print()
ssc.start() // Start the computation
ssc.awaitTermination() // Wait for the computation to terminate執行上面的指令碼就啟動了Spark Streaming(對應指令碼的路徑):
:load /opt/spark/SparkWordCount.scala這時就啟動好了Spark Streaming,至此所有的配置已經完成,所有的伺服器也已經啟動,現在進行測試,在上面Flume中exec中設定的檔案中寫入資料:
[shinelon@hadoop-senior datas]$ echo hadoop spark hadoop saprk hadoop>>flume.log
[shinelon@hadoop-senior datas]$ echo hadoop spark hadoop saprk hadoop>>flume.log
[shinelon@hadoop-senior datas]$ echo hadoop spark hadoop saprk hadoop>>flume.log
[shinelon@hadoop-senior datas]$ echo hadoop spark hadoop saprk hadoop>>flume.log
[shinelon@hadoop-senior datas]$ echo hadoop spark hadoop saprk hadoop>>flume.log
[shinelon@hadoop-senior datas]$ echo hadoop spark hadoop saprk hadoop>>flume.log可以看見在Spark Streaming中採集到了資料並且進行了計數:
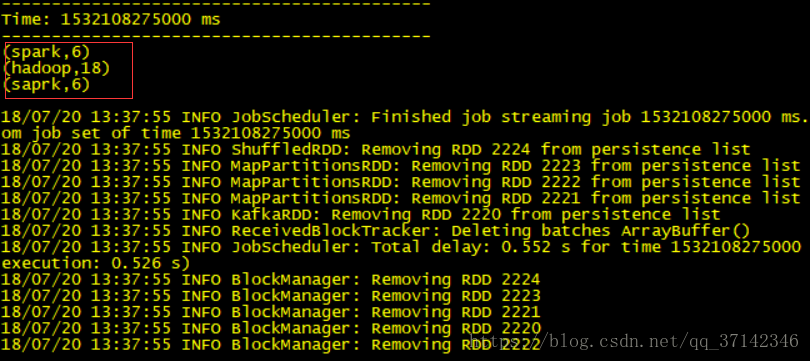
至此,我們就完成了Flume+Kafka+Spark Streaming的整合實現大資料實時流式資料採集,如有任何問題歡迎留言討論。
相關推薦
Flume+Kafka+Spark Streaming實現大資料實時流式資料採集
大資料實時流式資料處理是大資料應用中最為常見的場景,與我們的生活也息息相關,以手機流量實時統計來說,它總是能夠實時的統計出使用者的使用的流量,在第一時間通知使用者流量的使用情況,並且最為人性化的為使用者提供各種優惠的方案,如果採用離線處理,那麼等到使用者流量超標
基於 Flume+Kafka+Spark Streaming 實現實時監控輸出日誌的報警系統
運用場景:我們機器上每天或者定期都要跑很多工,很多時候任務出現錯誤不能及時發現,導致發現的時候任務已經掛了很久了。 解決方法:基於 Flume+Kafka+Spark Streaming 的框架對這些任務的輸出日誌進行實時監控,當檢測到日誌出現Error的資訊就傳送郵件給
大資料求索(9): log4j + flume + kafka + spark streaming實時日誌流處理實戰
大資料求索(9): log4j + flume + kafka + spark streaming實時日誌流處理實戰 一、實時流處理 1.1 實時計算 跟實時系統類似(能在嚴格的時間限制內響應請求的系統),例如在股票交易中,市場資料瞬息萬變,決策通常需要秒級甚至毫秒級。通俗來
基於Flume+Kafka+Spark Streaming打造實時流處理項目實戰課程
大數據本課程從實時數據產生和流向的各個環節出發,通過集成主流的分布式日誌收集框架Flume、分布式消息隊列Kafka、分布式列式數據庫HBase、及當前最火爆的Spark Streaming打造實時流處理項目實戰,讓你掌握實時處理的整套處理流程,達到大數據中級研發工程師的水平!下載地址:百度網盤下載
flume+kafka+spark streaming(持續更新)
kafka Kafka是一種高吞吐量的分散式釋出訂閱訊息系統,它可以處理消費者規模的網站中的所有動作流資料。 kafka的設計初衷是希望作為一個統一的資訊收集平臺,能夠實時的收集反饋資訊,並需要能夠支撐較大的資料量,且具備良好的容錯能力. Apache
大資料實時流式處理引擎比較
從流處理的核心概念,到功能的完備性,再到周邊的生態環境,全方位對比了目前比較熱門的流處理框架:Spark,Flink,Storm和 Gearpump。結合不同的框架的設計,為大家進行深入的剖析。與此同時,從吞吐量和延時兩個方面,對各個框架進行效能評估。 主要技術點:流失資料處理,Spark,
Spark入門實戰系列--7.Spark Streaming(上)--實時流計算Spark Streaming原理介紹
【注】該系列文章以及使用到安裝包/測試資料 可以在《》獲取 1、Spark Streaming簡介 1.1 概述 Spark Streaming 是Spark核心API的一個擴充套件,可以實現高吞吐量的、具備容錯機制的實時流資料的處理。支援從多種資料來源獲取資料,包括Kafk、Flume、Twitt
Flume+Kafka+Storm+Redis構建大資料實時處理系統
資料處理方法分為離線處理和線上處理,今天寫到的就是基於Storm的線上處理。在下面給出的完整案例中,我們將會完成下面的幾項工作: 如何一步步構建我們的實時處理系統(Flume+Kafka+Storm+Redis) 實時處理網站的使用者訪問日誌,並統計出該網站的PV、UV 將實時
Flume, Kafka和NiFi,大資料實時日誌資料收集、資料獲取技術哪家強?
作者Tony Siciliani 本文為36大資料獨譯,譯者:隨風 我們在建設一個大資料管道時,需要在Hadoop生態系統前仔細考慮,如何獲取大體量、多樣化以及高速性的資料。在決定採用何種工具以滿足我們的需求時,最初對於擴充套件性、可靠性、容錯性以及成本的考慮便發揮了作
Kafka:ZK+Kafka+Spark Streaming集群環境搭建(二)VMW安裝四臺CentOS,並實現本機與它們能交互,虛擬機內部實現可以上網。
centos 失敗 sco pan html top n 而且 div href Centos7出現異常:Failed to start LSB: Bring up/down networking. 按照《Kafka:ZK+Kafka+Spark Streaming集群環
大資料下的實時熱點功能實現討論(實時流的TopN)
我司內部有個基於jstorm的實時流程式設計框架,文件裡有提到實時Topn,但是還沒有實現。。。。這是一個挺常見挺重要的功能,但仔細想想實現起來確實有難度。實時流的TopN其實離大家很近,比如下圖百度和微博的實時熱搜榜,還有各種資訊類的實時熱點,他們具體實現方式不清楚,甚至有可能是半
[Spark]Spark-streaming通過Receiver方式實時消費Kafka流程(Yarn-cluster)
1.啟動zookeeper 2.啟動kafka服務(broker) [[email protected] kafka_2.11-0.10.2.1]# ./bin/kafka-server-start.sh config/server.properties 3.啟動kafka的producer(
學習筆記 --- Kafka Spark Streaming獲取Kafka資料 Receiver與Direct的區別
Receiver 使用Kafka的高層次Consumer API來實現 receiver從Kafka中獲取的資料都儲存在Spark Executor的記憶體中,然後Spark Streaming啟動的job會去處理那些資料 要啟用高可靠機制,讓資料零丟失,就必須啟用Spark
flume+zookeeper+kafka+spark streaming
1.flume安裝部署 1.1、下載安裝介質,並解壓: cd /usr/local/wget http://archive.cloudera.com/cdh5/cdh/5/flume-ng-1.6.0-cdh5.7.0.tar.gztar -zxvf flume-ng-1.6.0-cdh
Kafka+Spark Streaming+Redis實時系統實踐
基於Spark通用計算平臺,可以很好地擴充套件各種計算型別的應用,尤其是Spark提供了內建的計算庫支援,像Spark Streaming、Spark SQL、MLlib、GraphX,這些內建庫都提供了高階抽象,可以用非常簡潔的程式碼實現複雜的計算邏輯、這也得益於S
flume+kafka+storm整合實現實時計算小案例
我們做資料分析的時候常常會遇到這樣兩個場景,一個是統計歷史資料,這個就是要分析歷史儲存的日誌。我們會使用hadoop,具體框架可以設計為:1.flume收集日誌;2.HDFS輸入路徑儲存日誌;3.MapReduce計算,將結果輸出到HDFS輸出路徑;4.hive+sq
從 Spark Streaming 到 Apache Flink : 實時資料流在愛奇藝的演進
作者:陳越晨 整理:劉河 本文將為大家介紹Apache Flink在愛奇藝的生產與實踐過程。你可以藉此瞭解到愛奇藝引入A
【自動化】基於Spark streaming的SQL服務實時自動化運維
body oop nbsp define mysq tco source font getc 設計背景 spark thriftserver目前線上有10個實例,以往通過監控端口存活的方式很不準確,當出故障時進程不退出情況很多,而手動去查看日誌再重啟處理服務這個過程很低效
Flume+Kafka+Storm+Redis構建大數據實時處理系統:實時統計網站PV、UV+展示
大數據 實時計算 Storm [TOC] 1 大數據處理的常用方法 前面在我的另一篇文章中《大數據采集、清洗、處理:使用MapReduce進行離線數據分析完整案例》中已經有提及到,這裏依然給出下面的圖示: 前面給出的那篇文章是基於MapReduce的離線數據分析案例,其通過對網站產生的用戶訪問
Kafka:ZK+Kafka+Spark Streaming集群環境搭建(三)安裝spark2.2.1
node word clas 執行 選擇 dir clust 用戶名 uil 如何配置centos虛擬機請參考《Kafka:ZK+Kafka+Spark Streaming集群環境搭建(一)VMW安裝四臺CentOS,並實現本機與它們能交互,虛擬機內部實現可以上網。》 如