
python爬蟲----網易雲音樂之熱門評論
上次爬取了歌手的熱門歌曲,這次就來爬取熱門歌曲的熱門評論
熱門評論可沒歌曲那麼容易搞到手,還好有前輩們寫過類似的爬蟲,所以有許多資料參考。
lyrichu這位作者也寫了一篇關於網易雲熱門評論的爬蟲,寫的很詳細,可以去看看
http://www.cnblogs.com/lyrichu/p/6635798.html
關於爬取熱門評論的主要難點就是,在歌曲評論的頁面用一般方法去爬會獲取不到資料。
通過審查元素找到這個
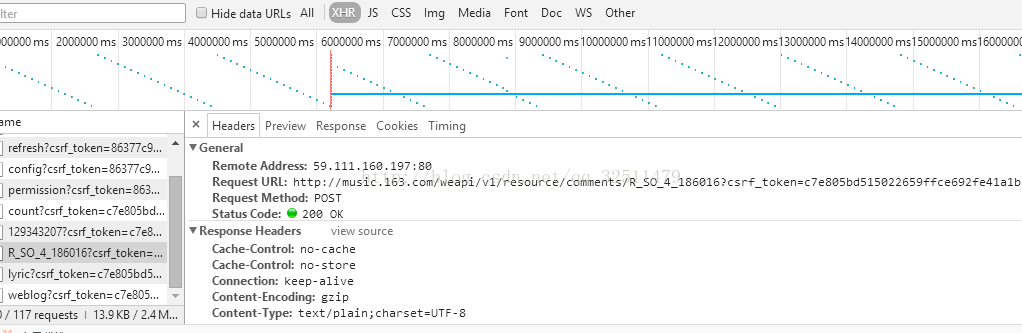
這上面的request url:http://music.163.com/weapi/v1/resource/comments/R_SO_4_186016?csrf_token=c7e805bd515022659ffce692fe41a1b3
自己打不開,用爬蟲也得不到資料。值得注意的是這裡用的方法是POST而不是GET,但無論是GET還是POST都不行。
經過一番查詢,只需要確定params和encSceKey兩個引數,就能得到評論。

這倆引數是加過密的,要想得到所有的評論就必須知道加密的方式。有許多人已經破解加密的方式了,有興趣可以去看看https://www.zhihu.com/question/21471960這個問題裡@路人甲的回答和https://www.zhihu.com/question/36081767這個問題@平胸小仙女的回答
既然我們爬的是熱門評論,就是單獨的一頁評論,params和encSceKey兩個引數直接拿來用就好。
經測試params和encSceKey兩個引數可以用在不同的歌曲的熱門評論。
還有一點URL中R_SO_4_186016數字部分就是歌曲的id,後面csrf_token=c7e805bd515022659ffce692fe41a1b3這段在換了歌曲id後沒有影響。
現在就可以開始爬取了,但我遇到一個異常

我以為是r.encoding那裡有問題,就改成了r.encoding = r.apparent_encoding。結果得到

呃.....一堆亂碼。後面用print(r.apparent_encoding)顯示的是windos-1245,原本的r.encoding是utf-8。
沒辦法只好去搜下那個出現的異常,又是一番搜尋。終於在https://www.zhihu.com/question/28704728這裡找到了答案
具體方法是

這裡要import sys,來執行sys.maxunicode
用這段程式碼就可以正常的顯示出來所爬去的東西了。關於這段程式碼的詳細解釋可以看https://stackoverflow.com/questions/32442608/ucs-2-codec-cant-encode-characters-in-position-1050-1050。就是出現這種異常的解決辦法。
因為我們爬取得到的資料是json,因此我們要引入json包,用json_data = json.loads(data)這條語句就可以解析json資料了。
http://www.bejson.com/這是個線上json校驗格式化工具,在這個網站可以清晰的看到json的結構,方面我們抓取資料。
程式碼:
import requests
import re
from bs4 import BeautifulSoup
import sys
import json
import os
def get_song_id(url):
try:
r = requests.get(url)
r.raise_for_status()
r.encoding = r.apparent_encoding
except:
print('wrong!!!!!!!')
html = r.text
soup = BeautifulSoup(html,'html.parser')
song = soup.find_all('ul',attrs = {'class':'f-hide'})[0]
all_song_id = re.findall(r'<a href="/song\?id=(\d+)">(.*?)</a>',str(song))
print(all_song_id)
return all_song_id
def get_hotcontent(url):
song_list = get_song_id(url)
fpath = 'E:/python/網易雲音樂熱門評論----周杰倫'
os.makedirs(fpath)
os.chdir(fpath)
non_bmp_map = dict.fromkeys(range(0x10000,sys.maxunicode + 1),0xfffd)
for single_id in song_list:
get_content_url = 'http://music.163.com/weapi/v1/resource/comments/R_SO_4_{}?csrf_token=86377c99d2ebe6570c4146676b9cb36d'.format(single_id[0])
param = {'params':'h84Z4kuySxni4TTba7U9khiYWVea9p8Gr+Vlh93EjFPNCtBGh+BTr7BMvx1M3a8FQ9X2UW4Pvif5zCy1gxuR+Ap/52ddf+pXrXlpTIrlkJEtnW0VCiBx7wm7UhFC47JUPtMlvsvm0NJZ+E57lBKHkUzuW3j12gWwnB1Qkvmbl3AC9912lUQIeWCyhN+V3n90yD+3jXxQBLQRDxlZIUWx81/UwV0RhY6kfLxIbZPghFI=',
'encSecKey':'526f02ffc615b9d13974e44ac551608e65a6d14b0adcc05d7cbe86c368aebef465e451a6250de12664a6faf585d567b24a9871a282aff757df2983584c7d5db2d12bbebdaa93b20d8fc65a4d0852ad01b0d450b0cf7373b2b5089edcc394d00925fd82a1e7e11e497f6ab9780cc3280ab3328fc4822d925b137d7bc8721d0f75'}
header = {'Host':'music.163.com',
'Origin':'http://music.163.com',
'Referer':'http://music.163.com/song?id='.format(single_id[0]),
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/45.0.2454.101 Safari/537.36'}
try:
r = requests.post(get_content_url, headers = header, data = param)
except:
print('獲取評論失敗!')
continue
data = r.text.translate(non_bmp_map)
#print(data)
json_data = json.loads(data)
hotcomment = json_data['hotComments']
print('歌曲:' + str(single_id[1]) + '\n')
Info = []
for i in range(len(hotcomment)):
user_name = hotcomment[i]['user']['nickname']
comment = hotcomment[i]['content']
like_num = hotcomment[i]['likedCount']
Info.append([str(i + 1),user_name,like_num,comment])
print('No.'+ str(i + 1))
print('使用者名稱:'+ str(user_name) + '\t' + '點贊:'+ str(like_num))
print('評論:'+ comment + '\n')
print('........................................................\n\n')
save(fpath,single_id,Info)
def save(fpath,single_id,Info):
final_fpath = fpath + '/' +str(single_id[1]) + '.txt'
with open(final_fpath,'w',encoding = 'utf-8') as f:
f.write('歌曲名稱:'+ str(single_id[1]) + '\n\n')
for i in Info:
f.write('No.'+ str(i[0]) + '\n')
f.write('使用者名稱:'+ str(i[1]) + '\t' + '點贊:' + str(i[2]) + '\n')
f.write('評論:'+ str(i[3]) + '\n\n')
def main():
url = 'http://music.163.com/artist?id=6452'
get_hotcontent(url)
main()
相關推薦
python爬蟲----網易雲音樂之熱門評論
上次爬取了歌手的熱門歌曲,這次就來爬取熱門歌曲的熱門評論 熱門評論可沒歌曲那麼容易搞到手,還好有前輩們寫過類似的爬蟲,所以有許多資料參考。 lyrichu這位作者也寫了一篇關於網易雲熱門評論的爬蟲,寫的很詳細,可以去看看 http://www.cnblogs.com/lyr
抓取網易雲音樂歌曲熱門評論生成詞雲(轉)
非原創作品,轉載自:http://blog.csdn.net/marksinoberg/article/details/70809830 前言 網易雲音樂一直是我向往的“神壇“,聽音樂看到走心的評論的那一刻,高山流水。於是今天來抓取一下歌曲的熱門評論。並做成詞
Python解密網易雲音樂.ncm檔案,將.ncm檔案轉換為.mp3檔案,實現隨處播放(另附C++已編譯轉換器)
網易雲音樂把.mp3音樂檔案加密為.ncm檔案,導致不能將下載好的音樂複製到其它裝置或使用非網易雲音樂播放器播放,該程式可將.ncm檔案逆向解密為.mp3檔案並保留最高音質。 另有C++已編譯.exe轉換器,將.ncm檔案拖到.exe上直接執行轉換,生成.mp3檔案在.ncm檔案相同路徑。點選下
爬蟲網易雲音樂,熱評,詞雲,prettytable。
樂爬網易雲 熱門評論 第三方庫 api介面 獲取評論 解析資料 顯示資料 詞雲 第三方庫 製作流程 詞雲程式碼 詞雲 排行榜 api
Python破解網易雲音樂下載版權限制
在播放某個音樂時,網易雲音樂會通過使用其api來解析這首音樂的id。 用Eminem的Rap God來舉例。 Rap God by Eminem https://music.163.com/#/song?id=27853227 #注意其中顯示此音樂的id為27853227 網易
python爬取網易雲音樂,python下載網易雲音樂
import requests import time import os from urllib import request from bs4 import BeautifulSoup import urllib class Wy: page = 0 wymusic = {}
python使用網易雲音樂 api下載mv
import json import requests import urllib import os import sys from urllib.parse import urlparse,parse_qs def http_get(api):
python利用網易雲音樂介面搭建的音樂推薦,根據單曲歌名推薦相關使用者喜愛的歌曲
一、網易雲音樂的相關介面 這邊我想要的資料介面有: * 網易的搜尋功能,根據歌名獲取歌曲的id * 歌曲相關的評論使用者介面 * 使用者的相關資料包括歌單或聽歌記錄,這邊聽歌記錄的介面好像不能用,所以我就用的歌單介面 關於每個介面大家可以自己F12網易官網看看是長什麼樣子,
【Python 】網易雲音樂【3】
之前用到的是別人伺服器的API介面: 現在自己搭建一個API平臺: 1. 下載NodeJS,並安裝,配置好環境變數 2. 下載 NodeJS原始碼 3. 解壓進入目錄,並執行命令 4. 成功! 5.寫一個指令碼啟動 title 網易雲音樂API
Python從網易雲音樂、QQ 音樂、酷狗音樂、蝦米音樂等搜尋和下載歌曲
music-dl 從網易雲音樂、QQ音樂、酷狗音樂、百度音樂、蝦米音樂等搜尋和下載歌曲。 Search and download
python爬蟲綜合篇,採集網易雲音樂全部歌手的熱門歌曲以及評論!
今天我給大家介紹一下用Python爬取網易雲音樂全部歌手的熱門歌曲.由於歌手個人主頁的網頁原始碼中還嵌入了一個子網頁(框架原始碼裡面包含了我們需要的資訊),因此我們不能使用requests庫來爬取,而使用selenium,接下來,讓我詳細講解整個爬取過程. 學習Pyt
小白都懂的Python爬蟲之網易雲音樂下載
微信又改版了,為了方便第一時間看到我們的推送,請按照下列操作,設定“置頂”:點選上方藍色字型“程
爬蟲入門——用python爬取網易雲音樂熱門歌手評論數
本文參考Monkey_D_Newdun 的文章用爬蟲獲取網易雲音樂熱門歌手評論數執行平臺:Windows 10IDE:spyderPython版本:3.6瀏覽器:360一、爬蟲基本思路a. 通過URL或者檔案獲取網頁:開啟網頁-F12-找到需要獲取的url,request h
Python 3爬蟲網易雲(五)——每天進步一點點(正則表達式下篇之HTML標簽)
tdd htm python swf sofm pts 正則表達 eal href 51忠酶9euka杖淪28炊http://jz.docin.com/ngaxf40277 嵌擲Ic白冉qgw抑亢84http://jz.docin.com/fejci232 gw2d4永
如何用Python網絡爬蟲爬取網易雲音樂歌曲
今天 http 分享圖片 分享 圖片 分分鐘 參考 down 技術 今天小編帶大家一起來利用Python爬取網易雲音樂,分分鐘將網站上的音樂down到本地。 跟著小編運行過代碼的筒子們將網易雲歌詞抓取下來已經不再話下了,在抓取歌詞的時候在函數中傳入了歌手ID和歌曲名兩個參數
如何用Python網絡爬蟲爬取網易雲音樂歌詞
網易雲歌詞 Python網絡爬蟲 網絡爬蟲 前幾天小編給大家分享了數據可視化分析,在文尾提及了網易雲音樂歌詞爬取,今天小編給大家分享網易雲音樂歌詞爬取方法。 本文的總體思路如下: 找到正確的URL,獲取源碼; 利用bs4解析源碼,獲取歌曲名和歌曲ID; 調用網易雲歌曲API,獲取歌詞; 將歌詞寫入
簡單的網易雲音樂熱門評論爬蟲
新手練習 all pymongo code rmi success 技術 ftime 加密算 簡單的網易雲音樂熱門評論爬蟲 註:本文沒有什麽技術含量,就是一個普通的AJAX數據爬蟲,適合新手練習 目標:爬取網易雲音樂歌曲的熱門評論 分析:本次爬蟲不難,思路是請求和獲取數據,
Python 網易雲音樂評論爬蟲
引言 之前網易雲音樂和農夫山泉合作,將熱門評論印在農夫山泉上引爆了朋友圈。於是想爬取一下網易雲的評論。網上搜了一下,對於網易雲評論的爬蟲不少,主要參考這篇文章:對網易雲音樂引數(params,encSecKey)的分析 。在此基礎上,添加了爬取雲音樂飆升榜中歌曲,再去爬取這些歌曲的評
網易雲音樂評論爬蟲(1):全部熱門歌曲及其 id 號
今天我給大家介紹一下用Python爬取網易雲音樂全部歌手的熱門歌曲.由於歌手個人主頁的網頁原始碼中還嵌入了一個子網頁(框架原始碼裡面包含了我們需要的資訊),因此我們不能使用requests庫來爬取,而使用selenium,接下來,讓我詳細講解整個爬取過程. 一,構造歌手個人主
網易雲音樂評論爬蟲:爬取全部熱門歌曲及其對應的id號
今天我給大家介紹一下用Python爬取網易雲音樂全部歌手的熱門歌曲.由於歌手個人主頁的網頁原始碼中還嵌入了一個子網頁(框架原始碼裡面包含了我們需要的資訊),因此我們不能使用requests庫來爬取,而使用selenium,接下來,讓我詳細講解整個爬取過程. 一,構造歌手個人