
Java 8-stream實現原理分析(一)
背景介紹
Java 8中引入了lambda和stream,極大的簡化了程式碼編寫工作,但是簡單的程式碼為何能實現如何豐富的功能,其背後又是如何實現的呢?
Spliterator和Iterator
Iterator
Iterator是Java中的第二個迭代器介面,在Java 1.2就已存在,相比Enumeration方法名更簡短,還增加了remove()方法,但是Iterator始終存在兩個問題:
Iterator 有兩個方法:
hasNext()和next();訪問下一個元素可能涉及到(但不需要)呼叫這兩個方法。因此,正確編寫 Iterator 需要一定量的防禦性和重複性編碼。(如果客戶端沒有在呼叫 next() 之前呼叫 hasNext() 會怎麼樣?如果它呼叫 hasNext() 兩次會怎麼樣?)
此外,這種兩方法協議通常需要一定水平的有狀態性,比如前窺 (peek ahead ) 一個元素(並跟蹤您是否已前窺)。這些要求累積形成了大量的每元素訪問開銷。
第一個問題比較容易理解,第二個問題就是因為Iterator中有remove()方法存在,若要在Iterator迴圈中使用remove(),就一定要記錄前一個元素(即前窺 一個元素),比如在ArrayList.Itr中除了有cursor代表下一個要訪問的元素下標外,還有lastRet記錄上一個訪問元素的下標.
Spliterator
Spliterator(splitable iterator可分割迭代器)是Java 中引進的第三個迭代器介面
- 使用boolean tryAdvance(Consumer);代替
hasNext()和next() - 不再提供
remove()方法 - 提供Spliterator trySplit();將自身一分為二,支援併發
流來源
Spliterator即為流來源
實現方式
本來還想繼續寫下去,但是發現再如何寫也無法超越我當時學習時看的部落格,暫時放棄.
深入理解Java Stream流水線
程式碼分析
下面以一段程式碼示例分析下stream的原始碼
public class StreamDemo {
public static void main(String[] args) {
List<String> strings = List.of("Apple", "bug", "ABC", "Dog");
strings = new 由於直到終端操作才會執行真正的運算,直接看到max(),max其實是reduce操作,最後會呼叫ReduceOp.evaluateSequential()
/**
* @param helper 終端操作的前一箇中間操作,通過呼叫"helper.wrapSink()"將"sink"構造成鏈
* @param spliterator 流來源,即ArrayList.Spliterator()
*/
@Override
public <P_IN> R evaluateSequential(PipelineHelper<T> helper,
Spliterator<P_IN> spliterator) {
return helper.wrapAndCopyInto(makeSink(), spliterator).get();
} /**
*
* @param sink ReduceOp呼叫makeSink()獲得的Sink
*/
@Override
@SuppressWarnings("unchecked")
final <P_IN> Sink<P_IN> wrapSink(Sink<E_OUT> sink) {
Objects.requireNonNull(sink);
//從最後一個stage直到第一個stage向前呼叫每個stage的opWrapSink()將sink構造成鏈
for ( @SuppressWarnings("rawtypes") AbstractPipeline p=AbstractPipeline.this; p.depth > 0; p=p.previousStage) {
sink = p.opWrapSink(p.previousStage.combinedFlags, sink);
}
return (Sink<P_IN>) sink;
}opWrapSink()是個抽象方法,我們看下filter()的opWrapSink()如何實現
@Override
public final Stream<P_OUT> filter(Predicate<? super P_OUT> predicate) {
Objects.requireNonNull(predicate);
return new StatelessOp<P_OUT, P_OUT>(this, StreamShape.REFERENCE,
StreamOpFlag.NOT_SIZED) {
/**
*
* @param flags 下一個sink的標誌位,供優化使用
* @param sink 下一個sink,通過此引數將sink構造成單鏈
* @return 當前中間操作關聯的sink
*/
@Override
Sink<P_OUT> opWrapSink(int flags, Sink<P_OUT> sink) {
//Sink.ChainedReference是Sink介面的預設實現,僅呼叫下一個sink的相應方法
return new Sink.ChainedReference<P_OUT, P_OUT>(sink) {
@Override
public void begin(long size) {
downstream.begin(-1);
}
@Override
public void accept(P_OUT u) {
if (predicate.test(u))
downstream.accept(u);
}
};
}
};
}opWrapSink()根據下一個sink和flags構造當前sink,並將當前sink返回,便於構成sink鏈
/**
*
* @param wrappedSink 呼叫wrapSink()返回的結果,即"第一個sink"
* @param spliterator 流來源
*/
@Override
final <P_IN> void copyInto(Sink<P_IN> wrappedSink, Spliterator<P_IN> spliterator) {
Objects.requireNonNull(wrappedSink);
if (!StreamOpFlag.SHORT_CIRCUIT.isKnown(getStreamAndOpFlags())) {
//依次呼叫begin()-->accept()-->end(),由於sink已經連結在一起,可以呼叫下一個sink的相應方法
wrappedSink.begin(spliterator.getExactSizeIfKnown());
spliterator.forEachRemaining(wrappedSink);
wrappedSink.end();
}
else {
copyIntoWithCancel(wrappedSink, spliterator);
}
}copyInto()依次呼叫第一個sink的begin(),accept(),end(),此時終端操作結果存放在最後一個sink中,返回終端操作結果即可.
Sink執行分析
接下來我們分析下4個sink(3箇中間操作+1個終端操作)之間是如何協作的
filter的begin()
@Override
public void begin(long size) {
//什麼都不做,僅僅呼叫dowStream.begin(),由於不確定傳給downStream的元素個數是多少,因此用引數"-1"代表不確定
downstream.begin(-1);
}map的begin()
@Override
public void begin(long size) {
//也是什麼都不做,但是map不會減少傳給downStream的資料個數,引數依然是"size"
downstream.begin(size);
}sorted的begin()
@Override
public void begin(long size) {
if (size >= Nodes.MAX_ARRAY_SIZE)
throw new IllegalArgumentException(Nodes.BAD_SIZE);
//初始化相關的引數,不在傳給downStream
b = (size > 0) ? new SpinedBuffer.OfInt((int) size) : new SpinedBuffer.OfInt();
}filter的accpet()
@Override
public void accept(P_OUT u) {
//只有通過predicate.test(u)才會傳遞給downStream
if (predicate.test(u))
downstream.accept(u);
}map的accpet()
@Override
public void accept(P_OUT u) {
//執行map操作
downstream.accept(mapper.applyAsInt(u));
}sorted的accpet()
@Override
public void accept(int t) {
//呼叫b.accept(t),b是SpinedBuffer型別,暫不分析
//同樣並未傳遞給downStream
b.accept(t);
}可能到這裡就有些疑惑了,為什麼sorted stage一直沒有呼叫ReduceOp sink的相關方法?我們帶著這個疑問繼續.
filter的end()
@Override
public void end() {
//簡單傳遞
downstream.end();
}map的end()
@Override
public void end() {
//同樣是簡單傳遞
downstream.end();
}sorted的end()
@Override
public void end() {
int[] ints = b.asPrimitiveArray();
Arrays.sort(ints);
//傳遞
downstream.begin(ints.length);
if (!cancellationWasRequested) {
for (int anInt : ints)
//傳遞
downstream.accept(anInt);
}
else {
for (int anInt : ints) {
if (downstream.cancellationRequested()) break;
downstream.accept(anInt);
}
}
//傳遞
downstream.end();
}看到這裡,我們就可以解釋上面的問題了:
由於sorted是一個有狀態的中間操作,在sorted完成之前,不能傳遞給downStream,只有在sorted的end()中才可傳遞給downStream
ReduceOp的相關方法
...
public void begin(long size) {
empty = true;
//state儲存最後的max結果,初始為0
state = 0;
}
@Override
public void accept(int t) {
if (empty) {
empty = false;
state = t;
}
else {
//operator就是Math::max,state存放最大值
state = operator.applyAsInt(state, t);
}
}
...總結
stream的中間操作會構造一個
stage鏈,在遇到終端操作時才會真正執行
wrapSink()–>當遇到終端操作時,最後一個stage呼叫wrapSink(),將最後一個stage直到第一個stage向前呼叫每個stage的opWrapSink()將sink構造成鏈
copyInto–>sink鏈構造完畢後,依次呼叫第一個sink的begin(),accept(),end(),執行完畢後終端操作結果存放在最後一個sink中,返回終端操作結果即可
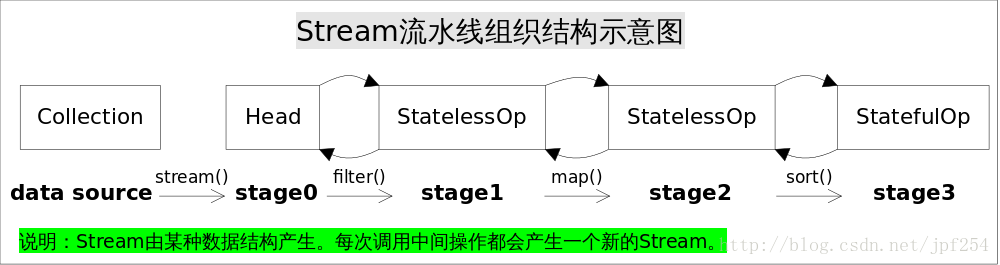

不足
- 尚未分析並行時如何執行
- 示例程式碼中的終端操作時非短路操作,沒有看出
Sink.cancellationRequested()的作用
參考
相關推薦
Java 8-stream實現原理分析(一)
背景介紹 Java 8中引入了lambda和stream,極大的簡化了程式碼編寫工作,但是簡單的程式碼為何能實現如何豐富的功能,其背後又是如何實現的呢? Spliterator和Iterator Iterator Iterator是Ja
Java原子類實現原理分析
upd hat 16px 檢查 () 過程 jvm api 處理 並發包中的原子類可以解決類似num++這樣的復合類操作的原子性問題,相比鎖機制,使用原子類更精巧輕量,性能開銷更小,下面就一起來分析下原子類的實現機理。 悲觀的解決方案(阻塞同步) 我們知道,num++看
根據時間戳轉Date實現(Java)及實現原理分析
時間戳是指格林威治時間1970年01月01日00時00分00秒(北京時間1970年01月01日08時00分00秒)起至現在的總秒數。 本次實現跟根據Java.text.* 包中的工具類實現的,示例程式碼: import java.text.SimpleDateFormat; public
Java NIO使用及原理分析 (一)
最近由於工作關係要做一些Java方面的開發,其中最重要的一塊就是Java NIO(New I/O),儘管很早以前瞭解過一些,但並沒有認真去看過它的實現原理,也沒有機會在工作中使用,這次也好重新研究一下,順便寫點東西,就當是自己學習 Java NIO的筆記了。本文為NIO使用及
Java Lambda表示式 實現原理分析
本文分析基於JDK 9 一、目標 本文主要解決兩個問題: 1、函式式介面 到底是什麼? 2、Lambda表示式是怎麼實現的? 先介紹一個jdk的bin目錄下的一個位元組碼檢視工具及反編譯工具:javap 二、函式式介面 @Funct
java併發機制的底層實現原理(一):volatile深入分析
java程式碼最終會被類載入器載入到JVM中,然後轉化為彙編指令在CPU上執行。java中所使用的併發機制依賴於JVM的實現和CPU的指令。 1.volatile的應用 volatile是一個輕量級的synchronize,它保證了共享變數的可見性,確保了所有執
JAVA中的集合原始碼分析一:ArrayList的內部實現原理
作為以java為語言開發的android開發者,集合幾乎天天都要打交道,無論是使用頻率最高的ArrayList還是HashSet,都頻繁的出現在平時的工作中。但是其中的原理之前卻一直沒深入探究,接下來記錄一下這次自己學習ArrayList原始碼的過程。 一.構造方法:
微信跳一跳輔助之JAVA版(最容易理解的演算法)實現原理分析
上幾周更新微信後,進入歡迎介面就提示出讓玩一把微信小遊戲《跳一跳》。一向不愛玩遊戲的我(除了經典QQ飛車、CS外),當時抱著沒興趣的態度簡單看了下,沒有玩。與朋友玩耍時,常聽他們聊起這個小遊戲,偶爾也在網頁和微信公眾號上看見些關於這個小遊戲的一些話題,為了不落伍,我決定繼續
Java 8 動態型別語言Lambda表示式實現原理分析
Java 8支援動態語言,看到了很酷的Lambda表示式,對一直以靜態型別語言自居的Java,讓人看到了Java虛擬機器可以支援動態語言的目標。 import java.util.function.Consumer; public class Lambda { pub
Java併發(4)深入分析java執行緒池框架及實現原理(一)
先說說我個人對執行緒池的理解:執行緒池顧名思義是一個裝有很多執行緒的池子,這個池子維護著從執行緒建立到銷燬的怎個生命週期以及執行緒的分配,使用者只需要把任務提交給這個執行緒池而不用去關心執行緒池如何建立執行緒,執行緒池會自己給這些任務分配執行緒資源來完成任務。 java的E
1.Java集合-HashMap實現原理及源碼分析
int -1 詳細 鏈接 理解 dac hash函數 順序存儲結構 對象儲存 哈希表(Hash Table)也叫散列表,是一種非常重要的數據結構,應用場景及其豐富,許多緩存技術(比如memcached)的核心其實就是在內存中維護一張大的哈希表,而HashMap的實
Java並發AQS原理分析(一)
jpg 子類 ole success ces || pro 同步 無法 我們說的AQS就是AbstractQueuedSynchronizer,他在java.util.concurrent.locks包下,這個類是Java並發的一個核心類。第一次知道有這個類是在看可重入鎖R
java併發程式設計一一執行緒池原理分析(一)
1、併發包 1、CountDownLatch(計數器) CountDownLatch 類位於 java.util.concurrent 包下,利用它可以實現類似於計數器的功能。 比如有一個任務A,它要等待其他4個任務執行完成之後才能執行,此時就可以利用CountDownLatch
Java JDK 動態代理使用及實現原理分析
一、什麼是代理? 代理是一種常用的設計模式,其目的就是為其他物件提供一個代理以控制對某個物件的訪問。代理類負責為委託類預處理訊息,過濾訊息並轉發訊息,以及進行訊息被委託類執行後的後續處理。 代理模式 UML 圖: 簡單結構示意圖: 為了保持行為的一致性,代
Java 內部類實現原理簡單分析
轉載:原文地址http://www.fzhen.info/?p=300 本文重點不在與內部類的語法及使用,而是試圖解釋一些背後的原理。 內部類簡介 Java支援在類內部定義類,即為內部類。 普通內部類 把類的定義放在類的內部,例如: 程式碼清單1: public class Outer{ priv
Java JDK 動態代理(AOP)使用及實現原理分析
/** * A factory function that generates, defines and returns the proxy class given * the ClassLoader and array of interfaces. */ privat
Java Annotation原理分析(一)
小引: 在當下的Java語言層面上,Annotation已經被應用到了語言的各個方面,它已經在現在的ssh開發中,通過Annotation極大的提高了開發的效率,堪稱開發神器。在這篇文章中,我們來了解一下的Annotation在Java中的前身今世吧。 1. Java
【java基礎】ReentrantReadWriteLock原始碼及實現原理分析
繼承關係 ReadLock和WriteLock是ReentrantReadWriteLock的兩個內部類,Lock的上鎖和釋放鎖都是通過AQS來實現的。 AQS定義了獨佔模式的acquire()和release()方法,共享模式的acquireShared()和r
JAVA基礎學習之-AQS的實現原理分析
ctf red 無限 ole 同步器 failed err lang 行鎖 AbstractQueuedSynchronizer是JUC的核心框架,其設計非常精妙。 使用了Java的模板方法模式。 首先試圖還原一下其使用場景:對於排他鎖,在同一時刻,N個線程只有1個線程能獲
Java ArrayList底層實現原理原始碼詳細分析Jdk8
簡介 ArrayList是基於陣列實現的,是一個動態陣列,其容量能自動增長,類似於C語言中的動態申請記憶體,動態增長記憶體。 ArrayList不是執行緒安全的,只能用在單執行緒環境下,多執行緒環境下可以考慮用Collections.synchronizedList(List l)函式返回一個執行緒安全的A