
Spark任務執行流程解析
Spark任務流程如下圖所示:
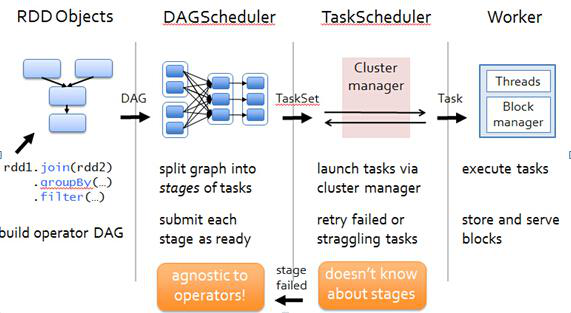
下面會根據該圖對每個步驟做詳細介紹:
1、RDD Objects
RDD(ResilientDistributed Dataset)叫做分散式資料集,是Spark中最基本的資料抽象,它代表一個不可變、可分割槽、裡面的元素可平行計算的集合。RDD具有資料流模型的特點:自動容錯、位置感知性排程和可伸縮性。RDD允許使用者在執行多個查詢時顯式地將工作集快取在記憶體中,後續的查詢能夠重用工作集,這極大地提升了查詢速度。
>>其中spark Rdd運算元可分為兩類:
1)transformation (轉換) 延遲載入,只會記錄元資料資訊其中當RDD進行一系列transformation操作後最終遇到Action方法時,DAG圖即確定了邊界,DAG圖形成。
DAG(Directed Acyclic Graph)叫做有向無環圖,原始的RDD通過一系列的轉換就就形成了DAG,根據RDD之間的依賴關係的不同將DAG劃分成不同的Stage,對於窄依賴,partition的轉換處理在Stage中完成計算。對於寬依賴,由於有Shuffle的存在,只能在parent RDD處理完成後,才能開始接下來的計算,因此寬依賴是劃分Stage的依據。
隨後會將DAG提交給DAGScheduler.
2
2、DAGScheduler會將DAG切分成多個stage,切分依據(寬依賴—shuffledRDD—即資料需要網路傳遞)
>>RDD和它依賴的父RDD的關係有兩種不同的型別,即窄依賴和寬依賴 >>窄依賴指的是每一個父RDD的partition最多被子RDD的一個Partition使用。(獨生子女) >>寬依賴指的是多個子RDD的partition會依賴同一個父RDD的Partition。(超生)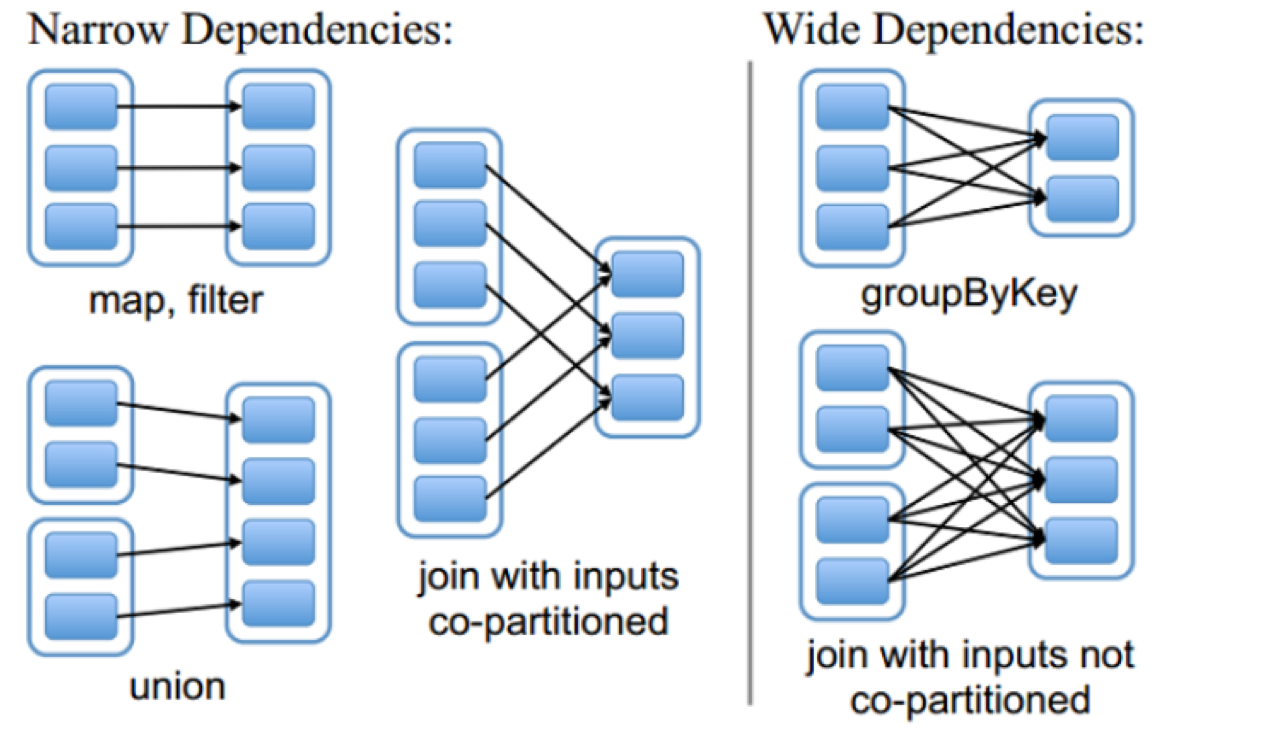
3、將多個stage封裝到TaskSet後提交給TaskScheduler 。 4、隨後TaskScheduler把任務提交給worker執行 。 注:其中DAGScheduler 和TaskScheduler都在Driver端(開啟spark-shell的那一端),main函式建立SparkContext時會使得driver和Master節點建立連線,Master會根據任務所需資源在叢集中找符合條件的worker. 隨後Master對worker進行RPC通訊,通知worker啟動Executor ,Executor會和Driver 建立連線,隨後的工作worker和Master不再有關係。 隨後Driver會向Executor提交Task。
相關推薦
Spark任務執行流程解析
Spark任務流程如下圖所示: 下面會根據該圖對每個步驟做詳細介紹: 1、RDD Objects RDD(ResilientDistributed Dataset)叫做分散式資料
spark的任務執行流程解析
一、從架構上看Spark的Job工作(Master\Worker) [睡著的水-hzjs-2016.8.18] 1.Master節點上是Master程序,主要是管理資源的,資源主要是記憶體和CPU。M
Spark任務執行流程
這是Spark官方給的圖,大致意思就是: 四個步驟 1.構建DAG(有向無環圖)(呼叫RDD上的方法) 2.DAGScheduler將DAG切分Stage(切分的依據是Shuffle),將Stage中生成的Task以TaskSet的形式給TaskSchedul
Spark-任務執行流程
目錄 Application在叢集中執行的大概流程 Application提交的方式 Application提交的叢集 Application在叢集中執行的大概流程 流程: 1.Driver分發task到資料所在的節點上執行。
Spark修煉之道(進階篇)——Spark入門到精通:第九節 Spark SQL執行流程解析
1.整體執行流程 使用下列程式碼對SparkSQL流程進行分析,讓大家明白LogicalPlan的幾種狀態,理解SparkSQL整體執行流程 // sc is an existing SparkContext. val sqlContext = new or
死磕 java執行緒系列之執行緒池深入解析——普通任務執行流程
(手機橫屏看原始碼更方便) 注:java原始碼分析部分如無特殊說明均基於 java8 版本。 注:執行緒池原始碼部分如無特殊說明均指ThreadPoolExecutor類。 簡介 前面我們一起學習了Java中執行緒池的體系結構、構造方法和生命週期,本章我們一起來學習執行緒池中普通任務到底是怎麼執行的。
死磕 java執行緒系列之執行緒池深入解析——未來任務執行流程
(手機橫屏看原始碼更方便) 注:java原始碼分析部分如無特殊說明均基於 java8 版本。 注:執行緒池原始碼部分如無特殊說明均指ThreadPoolExecutor類。 簡介 前面我們一起學習了執行緒池中普通任務的執行流程,但其實執行緒池中還有一種任務,叫作未來任務(future task),使用它
死磕 java執行緒系列之執行緒池深入解析——定時任務執行流程
(手機橫屏看原始碼更方便) 注:java原始碼分析部分如無特殊說明均基於 java8 版本。 注:本文基於ScheduledThreadPoolExecutor定時執行緒池類。 簡介 前面我們一起學習了普通任務、未來任務的執行流程,今天我們再來學習一種新的任務——定時任務。 定時任務是我們經常會用到的一
Spark Streaming執行流程及原始碼解析(一)
本系列主要描述Spark Streaming的執行流程,然後對每個流程的原始碼分別進行解析 之前總聽同事說Spark原始碼有多麼棒,咱也不知道,就是瘋狂點頭。今天也來擼一下Spark原始碼。 對Spark的使用也就是Spark Streaming使用的多一點,所以就拿Spark Streaming開涮。
Spark作業執行流程原始碼解析
目錄 相關概念 概述 原始碼解析 作業提交 劃分&提交排程階段 提交任務 執行任務 結果處理 Refe
通過Spark Rest 服務監控Spark任務執行情況
com 理想 ask cin *** lib add pan etime 1、Rest服務 Spark源為了方便用戶對任務做監控,從1.4版本啟用Rest服務,用戶可以通過訪問地址,得到application的運行狀態。 Spark的REST API返回的信息是JS
Scrapy框架的執行流程解析
... run方法 att page 集合 exception nco 生成 lis 這裏主要介紹七個大類Command->CrawlerProcess->Crawler->ExecutionEngine->sceduler另外還有兩個類:Reque
spark筆記2之spark粗略執行流程
目錄 一、Spark粗略的執行流程 二、程式碼流程 1、建立一個SparkConf 2、建立一個上下文物件SparkContext 3、建立一個RDD 4、使用transformations類運算元進行各種各樣的資料轉換 5、使用Action類運算元觸發執行 6、關閉
一篇讓你看懂Spark任務執行各物件建立時機!
1.SparkContext哪一端生成的? Driver端 2.DAG是在哪一端被構建的? Driver端 3.RDD是在哪一端生成的? Driver端 4.廣播變數是在哪一端呼叫的方法進行廣播的? Driver端 5.要廣播的資料應該在哪一端先建立好再廣播呢? Driver
Spark任務執行過程簡介
--executor-memory 每一個executor使用的記憶體大小 --total-executor-cores 整個application使用的核數 1.提交一個spark程式到spark叢集,會產生哪些程序?
Spark WordCount 執行流程
[[email protected] ~]$ spark-submit --class WordCount /home/hadoop/WordCount.jar Using Spark's default log4j profile: org/apache/spark/log4j-defaul
spark任務提交流程與管依賴和窄依賴
spark核心執行流程圖 代表4個階段 1構建RDD,進行join,groupBy,filter操作,形成DAG有向無環圖(有方向,沒有閉環),在最後一個action時完成DAG圖,代表著資料流向 2提交DAG為DAGScheduler,DAG排程器,主要是將
Quartz任務排程框架--任務執行流程(二)
上一篇部落格Quartz任務排程框架--簡介與示例(一)中我們已經簡介和示例程式碼對quartz有了初步的認識,這篇部落格我們通過追蹤quartz的定時任務執行流程來加深對quartz的瞭解。 1、執行活動執行緒 (1)Quartz_Worker-*執行
Spark運算元執行流程詳解之六
coalesce顧名思義為合併,就是把多個分割槽的RDD合併成少量分割槽的RDD,這樣可以減少任務排程的時間,但是請記住:合併之後不能保證結果RDD中的每個分割槽的記錄數量是均衡的,因為合併的時候並沒有考慮合併前每個分割槽的記錄數,合併只會減少RDD的分割槽個數,因此並不能利用它來解決資料傾斜的問題。 d
Spark應用執行流程
相關基本術語 Application:應用,即使用者需要完成的應用程式。一般來說,這部分程式碼需要使用者根據自己的需求來完成。這部分程式碼主要包括兩部分:Driver和Executor。 Driver:顧名思義,驅動者,為Application準備執行環境,驅動並監控Applicatio