
機器學習方法:迴歸(一):線性迴歸Linear regression
開一個機器學習方法科普系列:做基礎回顧之用,學而時習之;也拿出來與大家分享。數學水平有限,只求易懂,學習與工作夠用。週期會比較長,因為我還想寫一些其他的,呵呵。
content:
linear regression, Ridge, Lasso
Logistic Regression, Softmax
Kmeans, GMM, EM, Spectral Clustering
Dimensionality Reduction: PCA、LDA、Laplacian Eigenmap、 LLE、 Isomap(修改前面的blog)
SVM
ID3、C4.5
Apriori,FP
PageRank
minHash, LSH
Manifold Ranking,EMR
待補充
…
…
開始幾篇將詳細介紹一下線性迴歸linear regression,以及加上L1和L2的正則的變化。後面的文章將介紹邏輯迴歸logistic regression,以及Softmax regression。為什麼要先講這幾個方法呢?因為它們是機器學習/深度學習的基石(building block)之一,而且在大量教學視訊和教材中反覆被提到,所以我也記錄一下自己的理解,方便以後翻閱。這三個方法都是有監督的學習方法,線性迴歸是迴歸演算法,而邏輯迴歸和softmax本質上是分類演算法(從離散的分類目標匯出),不過有一些場合下也有混著用的——如果目標輸出值的取值範圍和logistic的輸出取值範圍一致。
ok,廢話不多說。
1、Linear Regression
可以說基本上是機器學習中最簡單的模型了,但是實際上其地位很重要(計算簡單、效果不錯,在很多其他演算法中也可以看到用LR作為一部分)。
先來看一個小例子,給一個“線性迴歸是什麼”的概念。圖來自[2]。
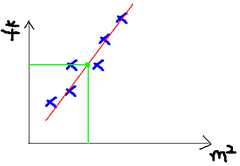
假設有一個房屋銷售的資料如下:
面積(m^2) 銷售價錢(萬元)
123 250
150 320
87 160
102 220
… …

當我們有很多組這樣的資料,這些就是訓練資料,我們希望學習一個模型,當新來一個面積資料時,可以自動預測出銷售價格(也就是上右圖中的綠線);這樣的模型必然有很多,其中最簡單最樸素的方法就是線性迴歸,也就是我們希望學習到一個線性模型(上右圖中的紅線)。不過說是線性迴歸,學出來的不一定是一條直線,只有在變數x是一維的時候才是直線,高維的時候是超平面。
定義一下一些符號表達,我們通常習慣用
線性迴歸的模型是這樣的,對於一個樣本
其中,
線性迴歸的目標是用預測結果儘可能地擬合目標label,用最常見的Least square作為loss function:
從下圖來直觀理解一下線性迴歸優化的目標——圖中線段距離(平方)的平均值,也就是最小化到分割面的距離和。
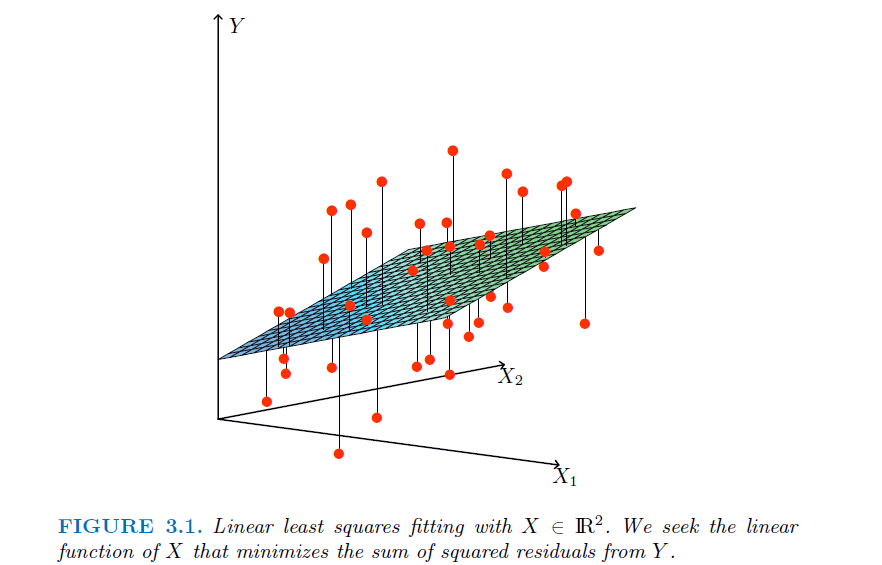
也就是很多中文教材中提到的最小二乘;線性迴歸是convex的目標函式,並且有解析解:
線性迴歸到這裡就訓練完成了,對每一個樣本點的預測值是
接下來看一下我們尋找到的預測值的一個幾何解釋:從上面的解析解
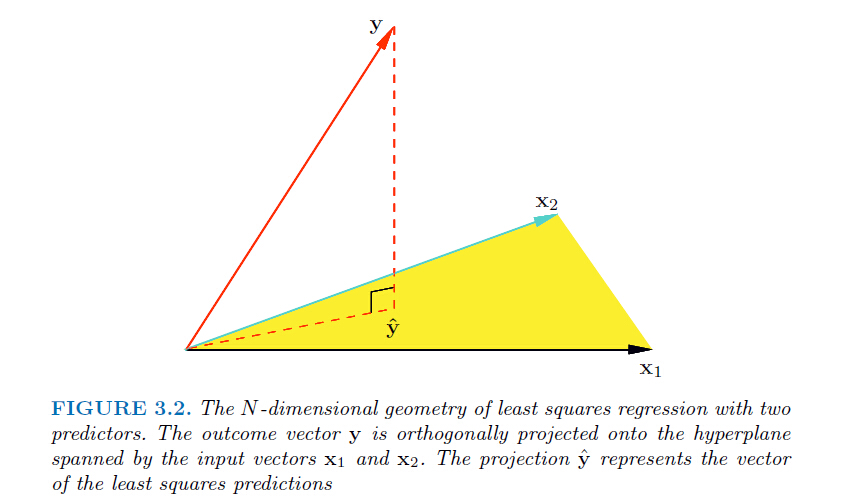
ok,一般介紹線性迴歸的文章到這裡也就結束了,因為實際使用中基本就是用到上面的結果,解析解計算簡單而且是最優解;當然如果求逆不好求的話就可以不用解析解,而是通過梯度下降等優化方法來求最優解,梯度下降的內容不在本篇中,後面講邏輯迴歸會說到。也可以看我前面寫的今天開始學PRML第5章中有寫到,或者直接翻閱wikipedia:gradient descent。
不過在這裡我再稍微提幾個相關的分析,可以參考ESL[3]的第3章中的內容。前面我們對資料本身的分佈是沒有任何假設的,本節下面一小段我們假設觀察值
證明:
相關推薦
《機器學習實戰》 筆記(一):K-近鄰演算法
一、K-近鄰演算法 1.1 k-近鄰演算法簡介 簡單的說,K-近鄰演算法採用測量不同特徵值之間的距離的方法進行分類。 1.2 原理 存在一個樣本資料集合,也稱作訓練樣本集,並且樣本集中每個資料都存在標籤,即我們知道樣本集中每一資料 與所屬分類的對應關係。輸入沒有標籤的新資料
機器學習方法:迴歸(一):線性迴歸Linear regression
開一個機器學習方法科普系列:做基礎回顧之用,學而時習之;也拿出來與大家分享。數學水平有限,只求易懂,學習與工作夠用。週期會比較長,因為我還想寫一些其他的,呵呵。 content: linear regression, Ridge, Lasso Logi
機器學習練習(一)——簡單線性迴歸
這篇文章是一系列 Andrew Ng 在 Coursera 上的機器學習課程的練習的一部分。這篇文章的原始程式碼,練習文字,資料檔案可從這裡獲得。 這些年來,我專業開發的一個關鍵時刻是當我發現 Courser
機器學習入坑指南(三):簡單線性迴歸
學習了「資料預處理」之後,讓我們一起來實現第一個預測模型——簡單線性迴歸模型。 一、理解原理 簡單線性迴歸是我們接觸最早,最常見的統計學分析模型之一。 假定自變數 xxx與因變數 yyy 線性相關,我們可以根據一系列已知的 (x,y)(x,y)(x,y) 資料
ng機器學習視頻筆記(一)——線性回歸、代價函數、梯度下降基礎
info 而且 wid esc 二維 radi pan 圖形 clas ng機器學習視頻筆記(一) ——線性回歸、代價函數、梯度下降基礎 (轉載請附上本文鏈接——linhxx) 一、線性回歸 線性回歸是監督學習中的重要算法,其主要目的在於用一個函數表
機器學習之數學基礎(一)-微積分,概率論和矩陣
系列 學習 python 機器學習 自然語言處理 圖片 clas 數學基礎 記錄 學習python快一年了,因為之前學習python全棧時,沒有記錄學習筆記想回顧發現沒有好的記錄,目前主攻python自然語言處理方面,把每天的學習記錄記錄下來,以供以後查看,和交流分享。~~
貝葉斯在機器學習中的應用(一)
需要 基礎 under 情況下 學生 意義 span 公式 ext 貝葉斯在機器學習中的應用(一) 一:前提知識 具備大學概率論基礎知識 熟知概率論相關公式,並知曉其本質含義/或實質意義
深度學習論文翻譯解析(一):YOLOv3: An Incremental Improvement
cluster tina ble mac 曾經 media bject batch 因此 原標題: YOLOv3: An Incremental Improvement 原作者: Joseph Redmon Ali Farhadi YOLO官網:YOLO: Real-Tim
吳恩達老師機器學習筆記異常檢測(一)
明天就要開組會了,天天在辦公室划水都不知道講啥。。。 今天開始異常檢測的學習,同樣程式碼比較簡單一點 異常檢測的原理就是假設樣本的個特徵值都呈高斯分佈,選擇分佈較離散的樣本的作為異常值。這裡主要注意的是通過交叉驗證對閾值的選擇和F1score的應用。 原始資料: 程式碼如下:
機器學習之數學系列(一)矩陣與矩陣乘法
1.對於矩陣的認識應當把它看成是多個向量的排列表或把矩陣看成行向量,該行向量中的每個元素都是一個列向量,即矩陣是複合行向量。如下圖所示。 2.對於下面這個矩陣的乘法有兩種看法: (1)矩陣將向量[b1,b2,b3].T進行了運動變換,這種變換可以是同空間內變換,也可以是不同空間間的變換;
《機器學習實戰》筆記(三):樸素貝葉斯
4.1 基於貝葉斯決策理論的分類方法 樸素貝葉斯是貝葉斯決策理論的一部分,貝葉斯決策理論的的核心思想,即選擇具有最高概率的決策。若p1(x,y)和p2(x,y)分別代表資料點(x,y)屬於類別1,2的概率,則判斷新資料點(x,y)屬於哪一類別的規則是: 4.3 使用條件概率來分類
Python機器學習基礎教程筆記(一)
description: 《Python機器學習基礎教程》的第一章筆記,書中用到的相關程式碼見github:https://github.com/amueller/introduction_to_ml_with_python ,筆記中不會記錄。 為何選擇機器學習 人為制訂決
機器學習技法筆記總結(一)SVM系列總結及實戰
機器學技法筆記總結(一)SVM系列總結及實戰 1、原理總結 在機器學習課程的第1-6課,主要學習了SVM支援向量機。 SVM是一種二類分類模型。它的基本模型是在特徵空間中尋找間隔最大化的分離超平面的線性分類器。 (1)當訓練樣本線性可分時,通過硬間隔最大化,學習
【機器學習+sklearn框架】(一) 線性模型之Linear Regression
前言 一、原理 1.演算法含義 2.演算法特點 二、實現 1.sklearn中的線性迴歸 2.用Python自己實現演算法 三、思考(面試常問) 參考 前言 線性迴歸(Linear Regression)基本上可以說是機器
機器學習實戰--決策樹(一)
決策樹是一種通過推斷分解,逐步縮小待推測事物範圍的演算法結構,重要任務就是理解資料中所蘊含的知識資訊,可以使用不熟悉的資料集合,並從中提取出一系列規則,根據資料集建立規則的過程就是機器學習的過程。 優點:計算複雜度不高,輸出結果易於理解,對中間值的缺失不敏感,可以處理不相關特
機器學習基本概念梳理(一)
1.輸入空間:輸入所有可能取值的集合 2.輸出空間:輸出所有可能的集合 3.特徵空間:所有特徵向量存在的空間 4.統計學習方法三要素:模型、策略、演算法。 5.監督學習的目的在於找到一個從輸入到輸出的對映,分為學習和預測。 6.期望損失:又稱風險函式,R=∫L(
機器學習實戰決策樹(一)——資訊增益與劃分資料集
from math import log #計算給定的熵 def calcsahnnonent(dataset): numentries = len(dataset) #計算例項的總數 labelcounts ={} #
[學習筆記]機器學習——演算法及模型(五):貝葉斯演算法
傳統演算法(五) 貝葉斯演算法 一、貝葉斯定理 簡介 貝葉斯定理是18世紀英國數學家托馬斯·貝葉斯(Thomas Bayes)提出得重要概率論理論;貝葉斯方法源於他生前為解決一個“逆概”問題寫的一篇文章
機器學習實戰讀書筆記(四):樸素貝葉斯演算法
樸素貝葉斯 優點: 在資料較少的情況下仍然有效 可以處理多類別問題 缺點:對輸入的資料的準備方式較為敏感 適用資料型別:標稱型資料 p1(x,y)>p2(x,y) 那麼類別是1 p2(x,y)>p1(x,y) 那麼類別是2 貝葉斯決策的核心是選擇具有最高概率的決策
學習之路-RabbitMQ(一):什麼是RabbitMQ
** RabbitMQ ** MQ全稱為Message Queue,即訊息佇列, RabbitMQ是由erlang語言開發,基於AMQP(Advanced Message Queue 高階訊息佇列協議)協議實現的訊息佇列,它是一種應用程式之間的通訊方法,訊息佇列在分散式系統開 發中應