
Spark+Kafka的Direct方式將偏移量傳送到Zookeeper的實現
Apache Spark 1.3.0引入了Direct API,利用Kafka的低層次API從Kafka叢集中讀取資料,並且在Spark Streaming系統裡面維護偏移量相關的資訊,並且通過這種方式去實現零資料丟失(zero data loss)相比使用基於Receiver的方法要高效。但是因為是Spark Streaming系統自己維護Kafka的讀偏移量,而Spark Streaming系統並沒有將這個消費的偏移量傳送到Zookeeper中,這將導致那些基於偏移量的Kafka叢集監控軟體(比如:Apache Kafka監控之Kafka Web Console、Apache Kafka監控之KafkaOffsetMonitor等)失效。本文就是基於為了解決這個問題,使得我們編寫的Spark Streaming程式能夠在每次接收到資料之後自動地更新Zookeeper中Kafka的偏移量。
我們從Spark的官方文件可以知道,維護Spark內部維護Kafka便宜了資訊是儲存在HasOffsetRanges類的offsetRanges中,我們可以在Spark Streaming程式裡面獲取這些資訊:
val offsetsList = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
這樣我們就可以獲取所以分割槽消費資訊,只需要遍歷offsetsList,然後將這些資訊傳送到Zookeeper即可更新Kafka消費的偏移量。完整的程式碼片段如下:
val messages = KafkaUtils.createDirectStream[String, String, StringDecoder, StringDecoder](ssc, kafkaParams, topicsSet)
messages.foreachRDD(rdd => {
val offsetsList = rdd.asInstanceOf[HasOffsetRanges].offsetRanges
val kc = new KafkaCluster(kafkaParams)
for (offsets < - offsetsList) {
val topicAndPartition = TopicAndPartition("test-topic", offsets.partition)
val o = kc.setConsumerOffsets(args(0), Map((topicAndPartition, offsets.untilOffset)))
if (o.isLeft) {
println(s"Error updating the offset to Kafka cluster: ${o.left.get}")
}
}
})
KafkaCluster類用於建立和Kafka叢集的連結相關的操作工具類,我們可以對Kafka中Topic的每個分割槽設定其相應的偏移量Map((topicAndPartition, offsets.untilOffset)),然後呼叫KafkaCluster類的setConsumerOffsets方法去更新Zookeeper裡面的資訊,這樣我們就可以更新Kafka的偏移量,最後我們就可以通過KafkaOffsetMonitor之類軟體去監控Kafka中相應Topic的消費資訊,下圖是KafkaOffsetMonitor的監控情況: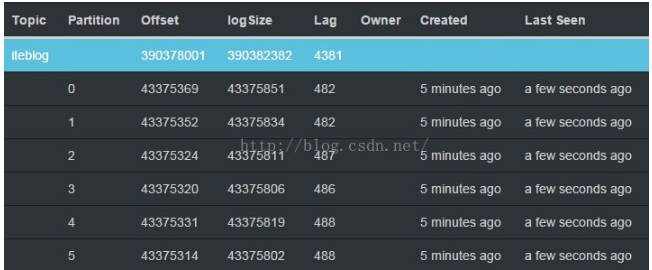
從圖中我們可以看到KafkaOffsetMonitor監控軟體已經可以監控到Kafka相關分割槽的消費情況,這對監控我們整個Spark Streaming程式來非常重要,因為我們可以任意時刻了解Spark讀取速度。另外,KafkaCluster工具類的完整程式碼如下:
package org.apache.spark.streaming.kafka
import kafka.api.OffsetCommitRequest
import kafka.common.{ErrorMapping, OffsetMetadataAndError, TopicAndPartition}
import kafka.consumer.SimpleConsumer
import org.apache.spark.SparkException
import org.apache.spark.streaming.kafka.KafkaCluster.SimpleConsumerConfig
import scala.collection.mutable.ArrayBuffer
import scala.util.Random
import scala.util.control.NonFatal
class KafkaCluster(val kafkaParams: Map[String, String]) extends Serializable {
type Err = ArrayBuffer[Throwable]
@transient private var _config: SimpleConsumerConfig = null
def config: SimpleConsumerConfig = this.synchronized {
if (_config == null) {
_config = SimpleConsumerConfig(kafkaParams)
}
_config
}
def setConsumerOffsets(groupId: String,
offsets: Map[TopicAndPartition, Long]
): Either[Err, Map[TopicAndPartition, Short]] = {
setConsumerOffsetMetadata(groupId, offsets.map { kv =>
kv._1 -> OffsetMetadataAndError(kv._2)
})
}
def setConsumerOffsetMetadata(groupId: String,
metadata: Map[TopicAndPartition, OffsetMetadataAndError]
): Either[Err, Map[TopicAndPartition, Short]] = {
var result = Map[TopicAndPartition, Short]()
val req = OffsetCommitRequest(groupId, metadata)
val errs = new Err
val topicAndPartitions = metadata.keySet
withBrokers(Random.shuffle(config.seedBrokers), errs) { consumer =>
val resp = consumer.commitOffsets(req)
val respMap = resp.requestInfo
val needed = topicAndPartitions.diff(result.keySet)
needed.foreach { tp: TopicAndPartition =>
respMap.get(tp).foreach { err: Short =>
if (err == ErrorMapping.NoError) {
result += tp -> err
} else {
errs.append(ErrorMapping.exceptionFor(err))
}
}
}
if (result.keys.size == topicAndPartitions.size) {
return Right(result)
}
}
val missing = topicAndPartitions.diff(result.keySet)
errs.append(new SparkException(s"Couldn't set offsets for ${missing}"))
Left(errs)
}
private def withBrokers(brokers: Iterable[(String, Int)], errs: Err)
(fn: SimpleConsumer => Any): Unit = {
brokers.foreach { hp =>
var consumer: SimpleConsumer = null
try {
consumer = connect(hp._1, hp._2)
fn(consumer)
} catch {
case NonFatal(e) =>
errs.append(e)
} finally {
if (consumer != null) {
consumer.close()
}
}
}
}
def connect(host: String, port: Int): SimpleConsumer =
new SimpleConsumer(host, port, config.socketTimeoutMs,
config.socketReceiveBufferBytes, config.clientId)
}