
5.大資料學習之旅——hadoop-簡介及偽分散式安裝
Hadoop簡介
是Apache的頂級專案,是一個可靠的、可擴充套件的、支援分散式計算的開源
專案。
起源
創始人:Doug Cutting 和Mike
2004 Doug和Mike建立了Nutch - 利用通用爬蟲爬取了網際網路上的所有數
據,獲取了10億個網頁資料 - 10億個網頁資料是非結構化資料,就意味
著這些資料是無法儲存到資料庫中

Doug發現了Google在2003年發表的一篇論文:《Google File System》,設計
了NDFS - Nutch Distributed File System解決了Nutch的儲存問題
Doug發現了Google在2003年發表的另一篇論文:《Google MapReduce》,
這篇論文講述了Google分散式系統的中的計算問題,Doug根據這篇論文設
計了MapReduce
後來,從Nutch0.8版本開始,就將NDFS和MapReduce模組獨立出來成為了
Hadoop,並且將NDFS更名為HDFS
Doug帶著Hadoop去了Yahoo,在Yahoo期間,設計了Pig, Hive, HBase等框架
Yahoo將Hadoop等框架貢獻給了Apache
Hadoop:Doug在命名的時候希望用一些無意義的單詞,就是為了防止重
名
Hadoop的版本
- Hadoop1.0:HDFS和MapReduce
- Hadoop2.0:完全重構的一套系統,不相容1.0。包含了
HDFS、MapReduce和Yarn - Hadoop3.0:包含了HDFS、MapReduce、Yarn以及Ozone
Hadoop的模組
- Hadoop Common:基本模組
- Hadoop Distributed File System:HDFS。進行資料的分散式儲存
- Hadoop YARN:進行任務排程和節點資源管理
- Hadoop MapReduce:基於Yarn對海量資料進行並行處理
- Hadoop Ozone:基於HDFS進行物件的儲存
Hadoop的偽分散式安裝
Hadoop的安裝方式
- 單機安裝。除了MapReduce模組以外,其他的都不能使用
- 偽分散式安裝。利用一臺主機模擬Hadoop的執行環境,可以使用
Hadoop的所有模組 - 全分散式安裝。在真正的叢集上去安裝Hadoop。
偽分散式的安裝
- 關閉防火牆 service iptables stop
vim /etc/sysnconfig/network
更改HOSTNAME,例如
HOSTNAME=hadoop01
source /etc/sysconfig/network - 修改主機名。在Hadoop叢集中,主機名中不允許出現_以及-,如果出現
會導致找不到這臺主機。
vim /etc/hosts
新增 ip 主機名 ,例如
192.168.60.132 hadoop01 - 更改hosts檔案
- 配置免密互通
ssh-keygen
ssh-copy-id 使用者名稱@主機地址,例如
ssh-copy-id [email protected] - 重啟計算機 reboot
- 安裝jdk
- 解壓Hadoop的安裝包 tar -xvf hadoop-2.7.1_64bit.tar.gz
- 進入安裝目錄下的子目錄etc下的子目錄hadoop cd
hadoop-2.7.1/etc/hadoop - 編輯hadoop-env.sh vim hadoop-env.sh
- 將JAVA_HOME替換為具體的jdk安裝目錄, 例如
export JAVA_HOME=/home/preSoftware/jdk1.8 - 將HADOOP_CONF_DIR替換為具體的Hadoop的配置目錄。例如
export HADOOP_CONF_DIR=/home/software/hadoop-2.7.1/etc/hadoop - 重新生效 source hadoop-env.sh
- 編輯core-site.xml vim core-site.xml
- 新增內容
<!-- 指定HDFS中的管理節點 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://hadoop01:9000</value>
</property>
<!-- 指定儲存位置 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/software/hadoop-2.7.1/tmp</value>
</property>
- 編輯hdfs-site.xml vim hdfs-site.xml
- 新增內容
<!-- hdfs中的複本數量 -->
<!-- 在偽分散式中,複本數量必須為1 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
- 將mapred-site.xml.template複製為mapred-site.xml cp mapred-
site.xml.template mapred-site.xml - 編輯mapred-site.xml vim mapred-site.xml
- 新增內容:
<!-- 在Hadoop的2.0版本中,MapReduce是基於Yarn執行 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
- 配置yarn-site.xml vim yarn-site.xml
- 新增內容
<property>
<name>yarn.resourcemanager.hostname</name>
<value>hadoop01</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
- Hadoop本身是主從結構,配置slaves指定從節點
vim slaves
新增從節點的地址 - 配置環境變數
vim /etc/profile
新增:
export HADOOP_HOME=/home/software/hadoop-2.7.1
export PATH= HADOOP_HOME/bin:$HADOOP_HOME/sbin
重新生效
source /etc/profile - 格式化資料目錄 hadoop namenode -format

- 啟動hadoop start-all.sh

- 如果啟動成功,可以在瀏覽器中輸入地址:50070訪問hadoop的頁面
HDFS
本身是用於儲存資料的
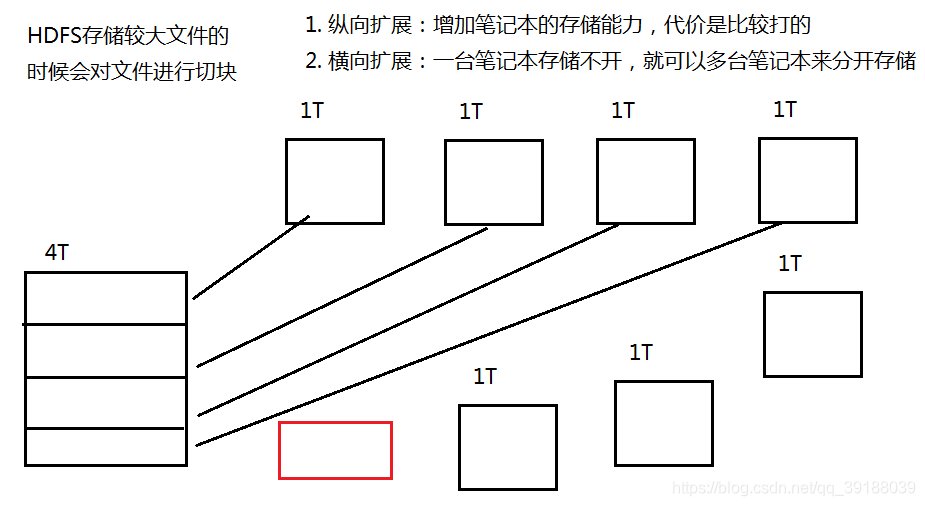
- 儲存資料的節點 - datanode, 管理資料的節點 - namenode
- HDFS儲存資料的時候會將檔案進行切塊,並且給每一個檔案塊分配
一個遞增的編號 - HDFS儲存資料的時候會對資料進行備份,每一個備份稱之為是一個
複本。在偽分散式下,複本設定為1,但是在全分散式下,複本預設
是3個 - 3個複本是放到不同的datanode中。複本的放置策略 - 機架感知策
略:- 第一個複本:客戶端連線的是哪一個datanode,複本就放到哪一
個datanode上 - 第二個複本:要放到另一個機架的datanode上
- 第三個複本:放到和第二個複本同機架的另一個datanode上
- 如果有更多的複本數量,其他的複本隨機放到其他的datanode
- 第一個複本:客戶端連線的是哪一個datanode,複本就放到哪一
- 如果某一個datanode宕機,那麼這個時候namenode就會將這個
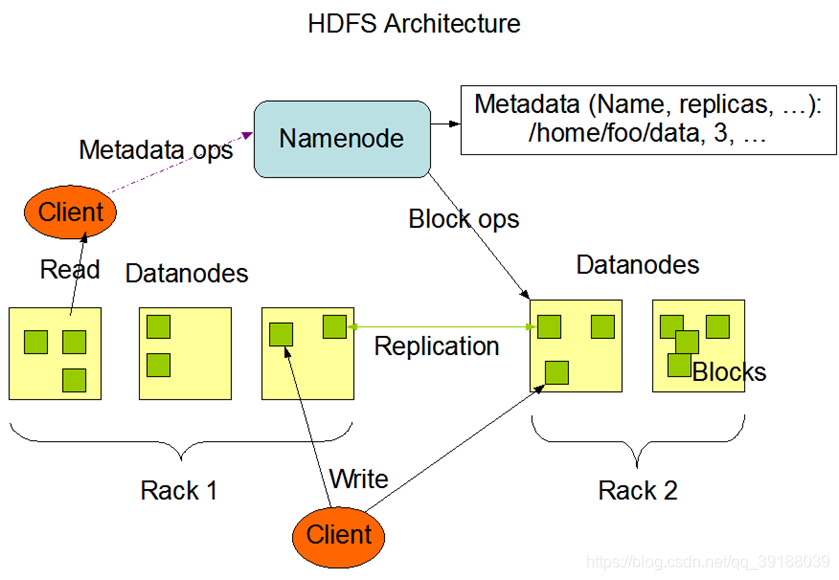
datanode上所存放的複本進行復制,保證整個hdfs中有指定的複本數量 - namenode需要管理datanode,namenode中儲存管理資訊 — 元資料 -
metadata — FileName replicas block-Ids id2host:- 記錄檔案儲存位置 /node01/a.txt
- 記錄檔案切的塊數
- 檔案塊儲存的datanode的地址
/test/a.log,3,{b1,b2},[{b1:[h0,h1,h3]},{b2:[h0,h2,h4]}] — 儲存的檔案
時a.log檔案,儲存在/test路徑下,複本數量為3,切了2塊,編號
為b1,b2,b1存放在h0,h1,h3節點下,b2存放在h0,h2,h4節點下
- datanode主動向namenode傳送心跳,保持namenode對datanode的管
理。心跳資訊包含:1.節點狀態 2.節點儲存的資料 - 如果超過10min中,namenode沒有收到datanode的心跳,那麼就認
為這個datanode已經lost,那麼namenode就會將這個lost的datanode
中的資料進行備份
優點
- 支援超大檔案:將檔案進行切塊分別放到不同的節點上
- 檢測和快速應對硬體故障:心跳機制
- 流式資料訪問
- 簡化的一致性模型:只要一個檔案塊寫好,那麼這個檔案塊就不允許
在進行改動,只能讀取 - 高容錯性:多複本。
- 可構建在廉價機器上:HDFS具有較好的擴充套件性。
缺點
- 高延遲資料訪問:不適合於互動式,也就意味著Hadoop不適合做實
時分析,而是做的離線分析 - 大量的小檔案:檔案的儲存要經過namenode,namenode中要記錄元
資料,元資料是儲存在記憶體中。大量的小檔案會產生大量的元資料,導
致記憶體被大量佔用,降低namenode的處理效率 - 多使用者寫入檔案、修改檔案:在hadoop2.0版本中,不支援修改,但
是支援追加 - 不支援超強的事務
技術細節
Block
HDFS在儲存資料的時候是將資料進行切塊,分別儲存到不同的節點上。
在Hadoop1.0版本中,每一個block預設是64M大小,在Hadoop2.0版本
中,每一個block預設是128M大小
400M - 4 - 其中前3塊,每一塊是128M,第4塊是16M
100M - 1 - 檔案塊按照實際大小100M儲存
好處:
- 利於大檔案的儲存
- 方便傳輸
- 便於計算
NameNode
負責datanode的管理以及儲存元資料。
元資料存在記憶體(快速查詢)和磁碟(崩潰恢復)中
HDFS的結構中,namenode存在單點問題
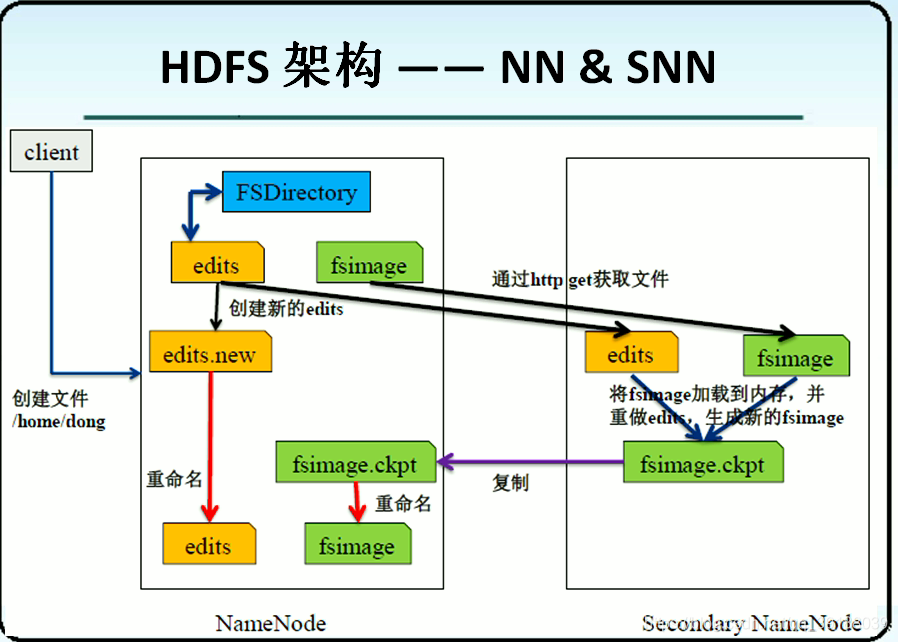
fsimage - 儲存元資料。但是注意fsimage中的元資料和記憶體中並不一致,
也就意味著fsimage中的資料並不是實時資料
edits - 儲存HDFS的操作
fstime - 記錄上一次的更新時間

觸發更新的條件:
- 檔案大小 — 根據配置檔案設定的edits log大小 fs.checkpoint.size 預設
64MB - 定時更新 — 根據配置檔案設定的時間間隔:fs.checkpoint.period 默
認3600秒 - 重啟hdfs的時候也會觸發更新 — 在合併過程中,HDFS不對外提供
寫服務,只提供讀服務 — 重啟hdfs的時候進行的更新階段 — 安
全模式
安全模式:
- 只能讀不能寫
- 檢查複本數量以及總量 — 導致偽分散式環境下,複本數量必須設
置為1
安全模式:
如果重啟hdfs,處於安全模式,等待一會兒,檢查完資料都沒有問題,
自動退出安全模式
在學習期間,重啟hdfs之後如果長期處於安全模式中,說明資料有損
壞: - 強制退出安全模式 hadoop dfsadmin -safemode leave
- 關閉HDFS
- 刪除dfs、nm-local-dir、logs
- 重新格式化 hadoop namenode -format
SecondaryNameNode
不是namenode的熱備份,而是進行fsimage和edits的合併的
hdfs體系結構
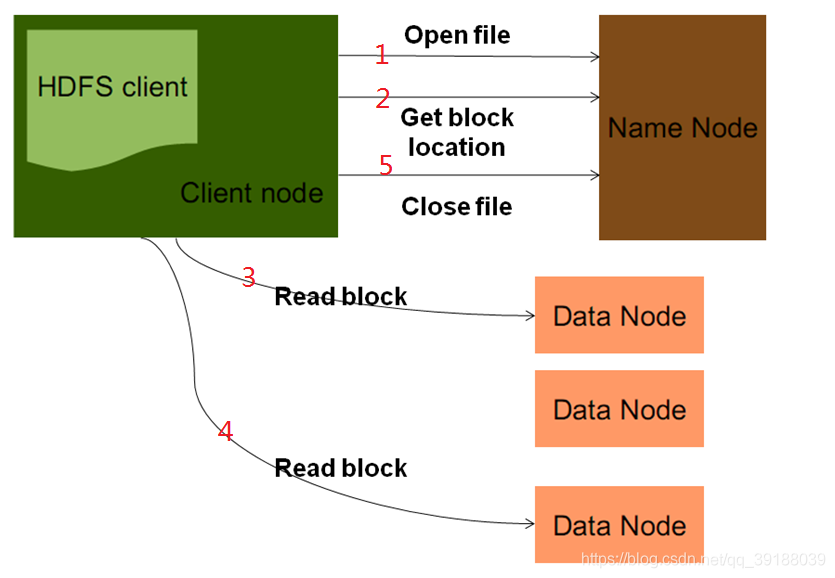
hdfs讀取資料
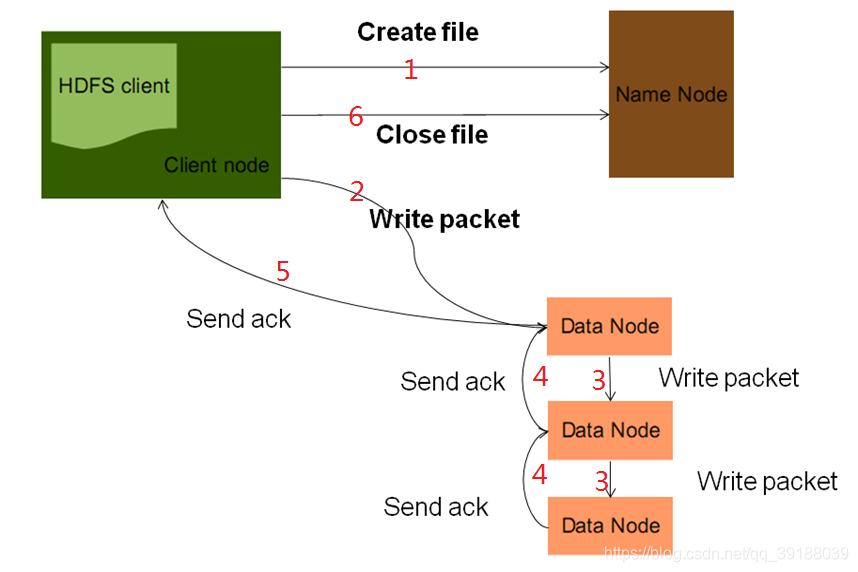
#hdfs寫入資料
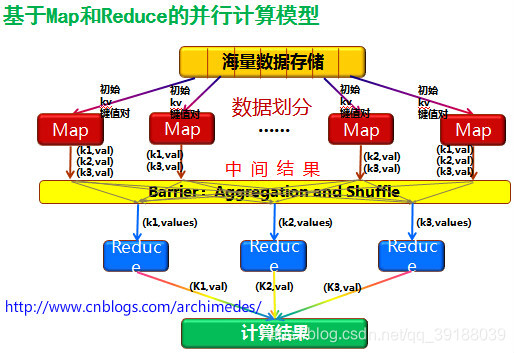
mr原理
ssn合併流程
上一篇 4.大資料學習之旅——Avro