
KNN(k-nearest neighbor algorithm)--從原理到實現
零.廣告
本文所有程式碼實現均可以在
DML 找到,不介意的話請大家在github裡給我點個Star
一.引入
K近鄰演算法作為資料探勘十大經典演算法之一,其演算法思想可謂是intuitive,就是從訓練集裡找離預測點最近的K個樣本來預測分類
因為演算法思想簡單,你可以用很多方法實現它,這時效率就是我們需要慎重考慮的事情,最簡單的自然是求出測試樣本和訓練集所有點的距離然後排序選擇前K個,這個是O(nlogn)的,而其實從N個數據找前K個數據是一個很常見的演算法題,可以用最大堆(最小堆)實現,其效率是O(nlogk)的,而最廣泛的演算法是使用kd樹來減少掃描的點,這也就是這篇文章的主要內容,本文偏實現,詳細理論教程見
二.前提:堆的實現
堆是一種二叉樹,用一個數組儲存,對於k號元素,k*2號是其左兒子,k*2+1號是其右兒子
而大根堆就是跟比左兒子和右兒子都大,小根堆反之。
要滿足這個條件我們需要通過up( index )操作和down( index )維護它的結構
當然講這個的文章實在有些多了,隨便搜一篇大家看看:點選開啟連結
大小根堆的作用是
a) 優先佇列:因為第一個元素是最大或者最小的元素,所以可以實現優先佇列
b) 前K個最大(最小)值
因為事先KD-tree+BBF 要同時用到這兩個東西,所以把它們實現在了同一個類裡,感覺程式碼略漂亮,貼出來觀賞一下:
傳入的時候不設定K就是正常的優先佇列,設定了K就是限制堆的大小了from __future__ import division import numpy as np import scipy as sp def heap_judge(a,b): return a>b class Heap: def __init__(self,K=None,compare=heap_judge): ''' 'K' is the parameter to restrict the length of Heap !!! when K is confirmed,the Min heap contain Max K elements while Max heap contain Min K elements 'compare' is the compare function which return a BOOL when pass two variable default is Max heap ''' self.K=K self.compare=compare self.heap=['#'] self.counter=0 def insert(self,a): #print self.heap if self.K!=None: print a.x,'===' if self.K==None: self.heap.append(a) self.counter+=1 self.up(self.counter) else: if self.counter<self.K: self.heap.append(a) self.counter+=1 self.up(self.counter) else: if (not self.compare(a,self.heap[1])): self.heap[1]=a self.down(1) return def up(self,index): if (index==1): return ''' print index for t in range(index+1): if t==0: continue print self.heap[t].x print ''' if self.compare(self.heap[index],self.heap[int(index/2)]): #fit the condition self.heap[index],self.heap[int(index/2)]=self.heap[int(index/2)],self.heap[index] self.up(int(index/2)) return def down(self,index): if 2*index>self.counter: return tar_index=0 if 2*index<self.counter: if self.compare(self.heap[index*2],self.heap[index*2+1]): tar_index=index*2 else: tar_index=index*2+1 else: tar_index=index*2 if not self.compare(self.heap[index],self.heap[tar_index]): self.heap[index],self.heap[tar_index]=self.heap[tar_index],self.heap[index] self.down(tar_index) return def delete(self,index): self.heap[index],self.heap[self.counter]=self.heap[self.counter],self.heap[index] self.heap.pop() self.counter-=1 self.down(index) pass def delete_ele(self,a): try: t=self.heap.index(a) except ValueError: t=None if t!=None: self.delete(t) return t
compare引數是比較大小的,預設是“數”的大根堆,你可以往堆裡傳任何類,只要有相適應的compare引數,比如我們KD-tree傳的就是KD-Node
三.KD-BFF的原理:
首先從KD-Tree的建立說起:(直接貼《統計學習方法》的內容了)

事實上從選擇哪一個feature開始切割,還可以選擇方差最大的那個引數,但是考慮到簡便,以及我們可以選擇更多的相似性度量方法,還是用《統計學習方法》裡面的選擇方式了。
然後是KD-tree搜尋的方法:(來自《統計學習方法》,但注意這裡是最近鄰,也就是k=1的時候)

那麼我們要K近鄰要怎麼做呢?就是用堆的第二個應用,用大根堆保持K個最小的距離,然後用根的距離(也就是其中最大的一個)來作為判斷的依據是否有更近的點不在結果中,這一點很重要!
同時摘錄july部落格的一段讀者留言講得非常好的:
在某一層,分割面是第ki維,分割值是kv,那麼 abs(q[ki]-kv) 就是沒有選擇的那個分支的優先順序,也就是計算的是那一維上的距離; 同時,從優先佇列裡面取節點只在某次搜尋到葉節點後才發生,計算過距離的節點不會出現在佇列的,比如1~10這10個節點,你第一次搜尋到葉節點的路徑是1-5-7,那麼1,5,7是不會出現在優先佇列的。換句話說,優先佇列裡面存的都是查詢路徑上節點對應的相反子節點,比如:搜尋左子樹,就把對應這一層的右節點存進佇列。
大致這就是我們實現的基本思路了
四.KD-BFF的實現:
知道原理了,並且有了堆這個工具之後我們就可以著手實現這個演算法了:(終於要貼程式碼了)
程式碼~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~此程式碼是 dml / KNN / kd.py
from __future__ import division
import numpy as np
import scipy as sp
from operator import itemgetter
from scipy.spatial.distance import euclidean
from dml.tool import Heap
class KDNode:
def __init__(self,x,y,l):
self.x=x
self.y=y
self.l=l
self.F=None
self.Lc=None
self.Rc=None
self.distsToNode=None
class KDTree:
def __init__(self,X,y=None,dist=euclidean):
self.X=X
self.k=X.shape[0] #N
self.y=y
self.dist=dist
self.P=self.maketree(X,y,0)
self.P.F=None
def maketree(self,data,y,deep):
if data.size==0:
return None
lenght = data.shape[0]
case = data.shape[1]
p=int((case)/2)
l = (deep%self.k)
#print data
data=np.vstack((data,y))
data=np.array(sorted(data.transpose(),key=itemgetter(l))).transpose()
#print data
y=data[lenght,:]
data=data[:lenght,:]
v=data[l,p]
rP=KDNode(data[:,p],y[p],l)
#print data[:,p],y[p],l
if case>1:
ldata=data[:,data[l,:]<v]
ly=y[data[l,:]<v]
data[l,p]=v-1
rdata=data[:,data[l,:]>=v]
ry=y[data[l,:]>=v]
data[l,p]=v
rP.Lc=self.maketree(ldata,ly,deep+1)
if rP.Lc!=None:
rP.Lc.F=rP
rP.Rc=self.maketree(rdata,ry,deep+1)
if rP.Rc!=None:
rP.Rc.F=rP
return rP
def search_knn(self,P,x,k,maxiter=200):
def pf_compare(a,b):
return self.dist(x,a.x)<self.dist(x,b.x)
def ans_compare(a,b):
return self.dist(x,a.x)>self.dist(x,b.x)
pf_seq=Heap(compare=pf_compare)
pf_seq.insert(P) #prior sequence
ans=Heap(k,compare=ans_compare) #ans sequence
while pf_seq.counter>0:
t=pf_seq.heap[1]
pf_seq.delete(1)
flag=True
if ans.counter==k:
now=t.F
#print ans.heap[1].x,'========'
if now != None:
q=x.copy()
q[now.l]=now.x[now.l]
length=self.dist(q,x)
if length>self.dist(ans.heap[1].x,x):
flag=False
else:
flag=True
else:
flag=True
if flag:
tp,pf_seq,ans=self.to_leaf(t,x,pf_seq,ans)
#print "============="
#ans.insert(tp)
return ans
def to_leaf(self,P,x,pf_seq,ans):
tp=P
if tp!=None:
ans.insert(tp)
if tp.x[tp.l]>x[tp.l]:
if tp.Rc!=None:
pf_seq.insert(tp.Rc)
if tp.Lc==None:
return tp,pf_seq,ans
else:
return self.to_leaf(tp.Lc,x,pf_seq,ans)
if tp.Lc!=None:
pf_seq.insert(tp.Lc)
if tp.Rc==None:
return tp,pf_seq,ans
else:
return self.to_leaf(tp.Rc,x,pf_seq,ans)
然後KNN就是對上面這個類的一個包裝:
程式碼~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~此程式碼是 dml / KNN / knn.py
#coding:utf-8
import numpy as np
import scipy as sp
from scipy.spatial.distance import cdist
from scipy.spatial.distance import euclidean
from dml.KNN.kd import KDTree
#import pylab as py
class KNNC:
"""docstring for KNNC"""
def __init__(self,X,K,labels=None,dist=euclidean):
'''
X is a N*M matrix where M is the case
labels is prepare for the predict.
dist is the similarity measurement way,
The distance function can be ‘braycurtis’, ‘canberra’,
‘chebyshev’, ‘cityblock’, ‘correlation’, ‘cosine’,
‘dice’, ‘euclidean’, ‘hamming’, ‘jaccard’, ‘kulsinski’,
‘mahalanobis’,
'''
self.X = np.array(X)
if labels==None:
np.zeros((1,self.X.shape[1]))
self.labels = np.array(labels)
self.K = K
self.dist = dist
self.KDTrees=KDTree(X,labels,self.dist)
def predict(self,x,k):
ans=self.KDTrees.search_knn(self.KDTrees.P,x,k)
dc={}
maxx=0
y=0
for i in range(ans.counter+1):
if i==0:
continue
dc.setdefault(ans.heap[i].y,0)
dc[ans.heap[i].y]+=1
if dc[ans.heap[i].y]>maxx:
maxx=dc[ans.heap[i].y]
y=ans.heap[i].y
return y
def pred(self,test_x,k=None):
'''
test_x is a N*TM matrix,and indicate TM test case
you can redecide the k
'''
if k==None:
k=self.K
test_case=np.array(test_x)
y=[]
for i in range(test_case.shape[1]):
y.append(self.predict(test_case[:,i].transpose(),k))
return y
因為KNN畢竟是一個分類演算法,所以我在predict是加上了分類的程式碼,如果只想檢驗Kd-tree的話,你可以直接用for_point()找最近k個點
五.測試+後記
測試:
我們選取《統計學習方法》上面的例子:
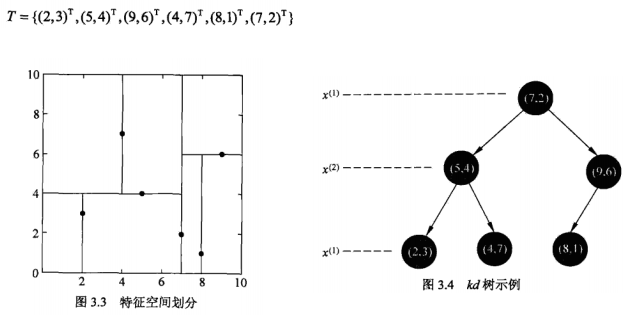
使用程式碼:
X=np.array([[2,5,9,4,8,7],[3,4,6,7,1,2]])
y=np.array([2,5,9,4,8,7])
knn=KNNC(X,1,y)
print knn.for_point([[6.5],[7]],1)輸出中後面帶了“===”的是掃描過的點,最後的是搜尋的結果:

我們可以看到的確避免掃描了(2,3),Bingo!!
我們再knn.for_point([[2],[2]]):可以看到避免掃了很多點!!!
後記:
從實現寫此文前後耗時兩天,昨天寫程式碼寫到熄燈且剛好測試通過,怎一個爽字了得!!最後,再在github上求個Star
reference:
【2】《統計學習方法》 李航
相關推薦
KNN(k-nearest neighbor algorithm)--從原理到實現
零.廣告 本文所有程式碼實現均可以在 DML 找到,不介意的話請大家在github裡給我點個Star 一.引入 K近鄰演算法作為資料探勘十大經典演算法之一,其演算法思想可謂是intuitive,就是從訓練集裡找離預測點最近的K個樣本來預測分類
KNN(k-nearest neighbor的縮寫)最近鄰演算法原理詳解
k-最近鄰演算法是基於例項的學習方法中最基本的,先介紹基於例項學習的相關概念。 基於例項的學習 已知一系列的訓練樣例,很多學習方法為目標函式建立起明確的一般化描述;但與此不同,基於例項的學習方法只是簡單地把訓練樣例儲存起來。 從這些例項中泛化的工作被推遲到必須分類新的例
KNN(K-Nearest Neighbor)演算法Matlab實現
KNN(K-Nearest Neighbor)演算法即K最鄰近演算法,是實現分類器中比較簡單易懂的一種分類演算法。K臨近之所以簡單是因為它比較符合人們直觀感受,即人們在觀察事物,對事物進行分類的時候,人們最容易想到的就是誰離那一類最近誰就屬於哪一類,即俗話常說的“近朱者赤,
MachineLearning— (KNN)k Nearest Neighbor實現手寫數字識別(三)
本篇博文主要結合前兩篇的knn演算法理論部分knn理論理解(一)和knn理論理解(二),做一個KNN的實現,主要是根據《機器學習實戰》這本書的內容,一個非常經典有趣的例子就是使用knn最近鄰演算法來實現對手寫數字的識別,下面將給出Python程式碼,儘量使用詳盡的解
MachineLearning— (KNN)k Nearest Neighbor之最近鄰法原理舉例理解(一)
K近鄰法(k-nearest neighbor)是機器學習當中較為簡單理解的一種基本分類與迴歸方法,KNN輸入的是例項的特徵向量,也就是特徵空間上的點;輸出的是其對應的類別標籤,KNN的訓練資料集的
kNN(k-nearest neighbor)理解與實現
一、理解 kNN三要素:k值選擇、距離度量、分類決策規則 流程:計算輸入例項與訓練集中各例項的距離,選出K個最近鄰訓練例項點,然後根據這K個點多數類進行分類。 k值選擇:k值選得過小意
演算法一 knn 擴充套件 BBF演算法,在KD-tree上找KNN ( K-nearest neighbor)
Step1: BBF演算法,在KD-tree上找KNN。第一步做匹配咯~ 1. 什麼是KD-tree(from wiki) K-Dimension tree,實際上是一棵平衡二叉樹。 一般的KD-tree構造過程: function kdtree (list
kNN(K-Nearest Neighbor)最鄰近規則分類
K最近鄰分類演算法 方法的思路:如果一個樣本在特徵空間中的k個最相似(即特徵空間中最鄰近)的樣本中的大多數屬於這一類別,則該樣本也屬於這個類別。KNN演算法中,所選擇的鄰居都是已經正確分類的物件。該方法在定類決策上只依據最鄰近的一個或者幾個樣本的類別來決定待分類樣本所屬的類
機器學習演算法:kNN(K-Nearest Neighbor)最鄰近規則分類
KNN最鄰近規則,主要應用領域是對未知事物的識別,即判斷未知事物屬於哪一類,判斷思想是,基於歐幾里得定理,判斷未知事物的特徵和哪一類已知事物的的特徵最接近; K最近鄰(k-Nearest Neighbor,KNN)分類演算法,是一個理論上比較成熟的方法,也是最簡單的機器
K最近鄰(KNN,k-Nearest Neighbor)準確理解
用了之後,發現我用的都是1NN,所以查閱了一下相關文獻,才對KNN理解正確了,真是丟人了。 左圖中,綠色圓要被決定賦予哪個類,是紅色三角形還是藍色四方形?如果K=3,由於紅色三角形所佔比例為2/3,綠色圓將被賦予紅色三角形那個類,如果K=5,由於藍色四方形比例為3/5,因此綠色圓被賦予藍色四方形類。
k最近鄰演算法(K-Nearest Neighbor)理解與python實現
numpy 模組參考教程:http://old.sebug.net/paper/books/scipydoc/index.html 一:什麼是KNN演算法? kNN演算法全稱是k-最近鄰演算法(K-Nearest Neighbor) kNN演算法的核心思想是如果一個樣本在特
最鄰近規則分類(K-Nearest Neighbor)KNN算法
bubuko rev created 換行 差值 code 是否 clas 分隔 自寫代碼: 1 # Author Chenglong Qian 2 3 from numpy import * #科學計算模塊 4 import operat
機器學習實戰(一)k-近鄰kNN(k-Nearest Neighbor)
目錄 0. 前言 1. k-近鄰演算法kNN(k-Nearest Neighbor) 2. 實戰案例 2.1. 簡單案例 2.2. 約會網站案例 2.3. 手寫識別案例 學習完機器學習實戰的k-近鄰演算法,簡單的做個筆記。文中
我的人工智慧之旅——近鄰演算法KNN(K-Nearest Neighbor)
在影象識別中,影象分類是首要工作。因為需要將不同型別的影象先進行排除。近鄰演算法是最簡單的演算法之一,但由於其弊端的存在,本篇只做瞭解性的簡單介紹, K近鄰演算法的實質 將測試圖片在已經分類好的,具有不同標籤的訓練資料圖片中,找到K張最相似的圖片,進而根據K張圖片中型別的比例大小,推斷圖
k近鄰演算法(k-nearest neighbor)和python 實現
1、k近鄰演算法 k近鄰學習是一種常見的監督學習方法,其工作機制非常簡單:給定測試樣本,基於某種距離度量找出訓練集中與其最靠近的k個訓練樣本,然後基於這K個"鄰居"的資訊來進行預測。 通常,在分類任務中可使用"投票法",即選擇這K個樣本中出現最多的類別標記作為預測結果;在迴歸任務中可使用"平
機器學習實戰(一)k-近鄰演算法kNN(k-Nearest Neighbor)
目錄 0. 前言 簡單案例 學習完機器學習實戰的k-近鄰演算法,簡單的做個筆記。文中部分描述屬於個人消化後的理解,僅供參考。 如果這篇文章對你有一點小小的幫助,請給個關注喔~我會非常開心的~ 0. 前言 k-近鄰演算法kNN(k-Neare
K近鄰法-k-nearest neighbor,KNN
WIKI In pattern recognition, the k-nearest neighbors algorithm (k-NN) is a non-parametric method used for classification and regression.[
4.1 最鄰近規則分類(K-Nearest Neighbor)KNN演算法
1968年提出的分類演算法 輸入基於示例的學習(instance-based learning),懶惰學習(lazy learning) 例子: 演算法詳述步驟: 為了判斷未知例項類別,用所有已知類別的例項作為參照 選擇引數k 計算未知例項與所有已知例項的距離 選擇
【深度學習基礎-04】最鄰近規則分類(K Nearest Neighbor)KNN演算法
1 基本概念 Cover和Hart在1968年提出了最初的臨近演算法 分類演算法classfication 輸入基於例項的學習instance-based learning ,懶惰學習lazy learning 2 例子: &n
《機器學習實戰》k最近鄰演算法(K-Nearest Neighbor,Python實現)
============================================================================================ 《機器學習實