
頻繁模式挖掘(Frequent Pattern Mining)
頻繁模式挖掘(FrequentPatternMining)是資料探勘中很常用的一個種挖掘,今天給大家介紹的一種名叫Apriori的頻繁模式挖掘演算法。先來看看什麼叫頻繁模式?~就是經常一起出現的模式,這裡的“模式”是一個比較抽象的概念,我們來看一個具體的例子,那就是著名的“啤酒與尿布”的故事~說是在美國有嬰兒的家庭中,一般都是母親在家中照看嬰兒,年輕的父親前去超市購買尿布。父親在購買尿布的同時,往往會順便為自己購買啤酒,這樣就會出現啤酒與尿布這兩件看上去不相干的商品經常會出現在同一個購物籃的現象。如果這個年輕的父親在賣場只能買到這兩件商品之一,則他很有可能會放棄購物而到另外一家商店,直到可以一次同時購買到啤酒和尿布為止。沃爾瑪發現這一獨特的現象,開始在賣場嘗試將啤酒與尿布擺放在相同的區域,讓年輕的父親可以同時找到這兩件商品,並很快地完成購物;而沃爾瑪超市也可以讓這些客戶一次購買到兩件商品,而不是一件,從而獲得了很好的商品銷售收入,這就是“啤酒與尿布”故事的由來。再比如在超市的銷售記錄裡,常常會發現牛奶和麵包是經常被一起購買的,那麼牛奶和麵包這兩個item經常一起現在銷售記錄中,所以在這裡牛奶和麵包是一個可以看成是一個頻繁模式,當然單獨看牛奶,單獨看麵包,也是頻繁模式。
那麼頻繁模式挖掘就是想找出這些頻繁出現的模式,至於這個“頻繁”是怎麼定義的呢?那要看演算法裡的設定。我們來看看Apriori演算法,首先需要先介紹幾個概念,以便於演算法的理解:
1)支援度:表示某個item集合在資料表中出現的比例。
2)K-項候選集:由K-1項頻繁集組合而成,支援度大於等於指定支援度的含有K個項的集合,供計算K項頻繁集使用。
3)K-項頻繁集:支援度大於等於指定支援度的含有k個項的集合,由K項候選集計算而得。
看完這三個定義,是不是很茫然?。。我一慣很喜歡舉例子,因為看例子很容易理解,下面我們就通過例子來看看這個演算法,就會明白上述的術語是怎麼回事了。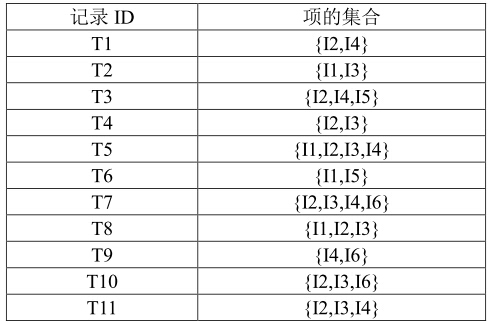
假設有上面這樣一張表,我們想找出有哪些item是經常一起出現的,這些item具體是什麼,要看具體的問題,比如可以是賣出的貨物,或者使用者的tag等等。下面我們開始計算。首先從1-項集開始,就是隻考慮一個item在多少條記錄中出現過,然後出現該項集的記錄數所佔的百分比,就是支援度,計算得:
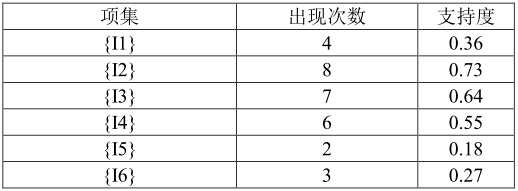
上面這張表中算出的項集,就是K-項候選集,這裡是1-項候選集。在演算法中,我們需要設定一個最小支援度,用來過濾掉一些不頻繁的項集,假設把最小支援度設為0.25,那麼把支援度小於0.25的項集就會被過濾掉,得到下表:
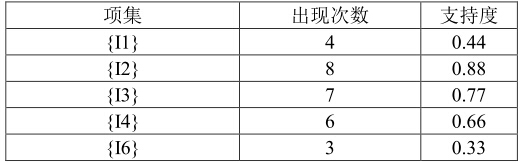
上表所計算得到的項集,就是K-項頻繁集,這裡是1-項頻繁集,就是在我們設定的最小支援度設為0.25的情況下,這些1-項集被認為是頻繁出現的。算出了1-項頻繁集後,再繼續擴充套件,算2-項頻繁集,也就是算什麼樣的兩個item頻繁出現。在算K+1-項頻繁項時,注意有一個這樣的結論:如果K+1個元素構成頻繁項集,那麼它的任意K個元素的子集也是頻繁項集。
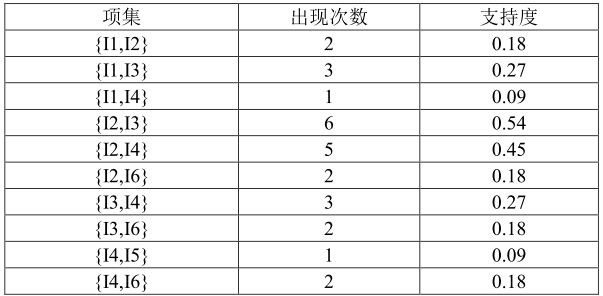
從中選出支援度大於等於 0.25 的項集,即是 2-項頻繁集:
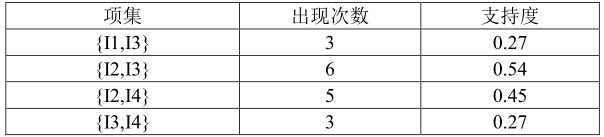
再用同樣的方法計算3-項候選集,得到:
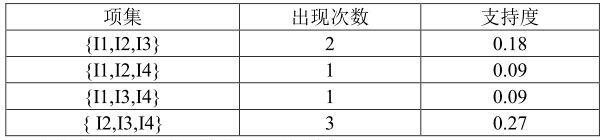
選出支援度大於等於 0.25的項集得 3-項頻繁集,得到:

繼續往下算,直到計算出的頻繁集為空集,這個例子的 4-項頻繁集即為空集,因此最大項集是 3-項頻繁集。就 2-項頻繁集來看,它表示這表示I1 和 I3 同時出現,或 I2 和 I3 同時出現,或 I2 和 I4 同時出現,或 I3 和 I4同時出現的概率大於等於設定的最小支援度,即大於等於 0.25。而 3-項頻繁集{ I2,I3,I4}表示{
I2,I3,I4}同時出現的概率也大於等於設定的最小支援度,即大於等於 0.25。
這個演算法還是挺有用的,因為我們常常會關心什麼和什麼經常一起出現,這個演算法給我提供了一個解決方案。
相關推薦
頻繁模式挖掘(Frequent Pattern Mining)
頻繁模式挖掘(FrequentPatternMining)是資料探勘中很常用的一個種挖掘,今天給大家介紹的一種名叫Apriori的頻繁模式挖掘演算法。先來看看什麼叫頻繁模式?~就是經常一起出現的模式,這裡的“模式”是一個比較抽象的概念,我們來看一個具體的例子,
購物籃分析分類演算法——頻繁模式挖掘(聚類演算法)
頻繁模式是頻繁地出現在資料集中的模式,包括頻繁項集(如牛奶和麵包)、頻繁子序列(首先購買PC,然後是數碼相機,再後是記憶體卡)或頻繁子結構(涉及不同的結構形式,如子圖、子樹或子格,它可
序列模式挖掘(AprioriAll和AprioriSome演算法)
序列模式(sequential pattern)挖掘最早由Agrawal等人提出,針對帶有交易時間屬性的交易資料庫,獲取頻繁專案序列以發現某段時間內客戶的購買活動規律。每一次交易包含customer-id,transaction-time和items(購置的商品內容)。 定義1一個序列(sequence)
Spark FPGrowth (Frequent Pattern Mining)
生成 app art lte spark 計算 con item lis 給定交易數據集,FP增長的第一步是計算項目頻率並識別頻繁項目。與為同樣目的設計的類似Apriori的算法不同,FP增長的第二步使用後綴樹(FP-tree)結構來編碼事務,而不會顯式生成候選集,生成的代
【安全牛學習筆記】?KALI版本更新和手動漏洞挖掘(SQL註入)
信息安全 security+ sql註入 漏洞 KALI版本更新-----第一個ROLLING RELEASEKali 2.0發布時聲稱將采用rolling release模式更新(但並未實施)Fixed-release 固定發布周期 使用軟件穩定的主流版本 發布--
設計模式 十七 狀態模式State(物件行為型)
分享一下我老師大神的人工智慧教程!零基礎,通俗易懂!http://blog.csdn.net/jiangjunshow 也歡迎大家轉載本篇文章。分享知識,造福人民,實現我們中華民族偉大復興!
設計模式 ( 十五 ) 觀察者模式Observer(物件行為型)
分享一下我老師大神的人工智慧教程!零基礎,通俗易懂!http://blog.csdn.net/jiangjunshow 也歡迎大家轉載本篇文章。分享知識,造福人民,實現我們中華民族偉大復興!
吳伯凡-自我迭代與自我迭代的第一步--》模式識別(第一天更新)
自我迭代 什麼是自我迭代 簡單的講自我迭代就是對自己的認知系統,進行持續系統的優化 那怎麼樣進行自我迭代呢? 自我迭代的第一步就是,要找準自己的定位,說的大白話一些,就是要認清自己是那塊料,古人不是常說人貴有自知之明嘛,說的就是這個意思 而比較好的教育方式,是因材施教,而這要求老師有能力去發現每個學
常用設計模式總結(面試常問)
Singleton(單例模式) 一句話總結:一個類在Java虛擬機器中只有一個物件,並提供一個全域性訪問點。 生活中例子:太陽、月亮、國家主席等。 解決什麼問題:物件的唯一性,效能浪費太多。 專案裡面怎麼用:資料庫連線物件,屬性配置檔案的讀取物件。 模式結構:分為餓漢式和懶漢式(
設計模式教程(Design Patterns Tutorial)筆記之一 建立型模式(Creational Patterns)
目錄 · 概述 · Factory · What is the Factory Design Pattern? ·
設計模式之單例模式二(懶漢式double check)
上一篇文章中的懶漢式單例模式採用同步方法保證了執行緒安全,但是開銷很大,每次執行該方法都會檢查鎖。下面採用double check的方式進行改寫,下面這種實現看似可行,實則有缺陷,具體缺陷在後文分析: 注意上面第二幅圖中對lazyDoubleCheckSingl
觀察者模式實現(模仿CSharpMessenger擴充套件)
我們在遊戲開發中經常會用到這種模式,用於模組之間的訊息分發,來降低模組之間耦合性,基本原來就是利用字串作為key值來儲存回撥函式(大多數觀察者模式使用字串作為訊息佇列中的key值),分發訊息時檢索key值來獲取回撥函式並執行來達到模組之間互動的功能,為了實現訊息型別拓展,這裡我使用了類模板來實現
評價頻繁模式挖掘和關聯分析的指標(模型興趣度度量方法)
強規則不一定是有趣的 關聯分析和頻繁模式挖掘的兩大經典演算法包括:Apriori演算法和FP-growth。 其在學習過程中的評價指標主要包括支援度(包括支援度計數)和置信度(也叫可信度)。但其實這兩個指標有一定的侷限性。 示例問題如下: 假設一共有10000個事務,其中包括A事件的
設計模式總結(Java語言實現)
有人說,為什麼要學習設計模式,有些設計模式寫起來十分複雜,在平時程式設計時不會刻意去使用它。但是,設計模式是程式碼規範的一種體現,學號設計模式併合理應用,可以避免bug的出現,增強程式碼的魯棒性,便於後
基於約束的頻繁模式挖掘
7.3.1 關聯規則的元規則制導挖掘 元規則的作用是什麼? 元規則使得使用者可以說明他們感興趣的規則的語法形式。規則的形式可以作為約束,幫助提高 挖掘的效能。也是說,它挖掘一種規則的形式(或者說,屬性的組合模式而不是這種組合本身。) 那麼如何使用元規則指導挖掘過程呢? 首
時間序列頻繁模式挖掘:A->(EFG)->C 模式的思考
首先了解一下 A->(EFG)->C 是個什麼形式: 這裡面被括號包覆的部分表示EFG是無序存在的,比如EFG,EGF,GEF,GFE他們都可以統一寫成(EFG)的形式,假設這四個項集都只
頻繁模式挖掘 Apriori 演算法簡介
本文主要介紹頻繁模式挖掘演算法,以及其典型的應用和Apriori演算法。頻繁模式挖掘,相關性挖掘,關聯規則學習,Apriori演算法等等,這些看似不同但本質上一樣的概念一直以來被用於描述資料探勘的相關內容。所謂的資料探勘是指利用統計的方法從某個資料集中發現有價值
【資料探勘學習筆記】10.頻繁模式挖掘基礎
一、基本概念頻繁模式– 頻繁的出現在資料集中的模式– 項集、子序或者子結構動機– 發現數據中蘊含的事物的內在規律• 項(Item) – 最小的處理單位 – 例如:Bread, Milk• 事務(Transaction) – 由事務號和項集組成 – 例如:<1, {Bre
頻繁模式挖掘 Apriori
原文地址:http://blog.sina.com.cn/s/blog_6a17628d0100v83b.html 1. 挖掘關聯規則 1.1 什麼是關聯規則 一言蔽之,關聯規則是形如X→Y的蘊涵式,表示通過X可以推導“得到”Y,其中X和Y分別稱
poll兩種模式淺析(ET or LT)
linux非同步IO淺析 http://hi.baidu.com/_kouu/blog/item/e225f67b337841f42f73b341.html epoll有兩種模式,Edge Triggered(簡稱ET) 和 Level Triggered(簡稱LT)