
【神經網路與深度學習】【計算機視覺】SSD
背景介紹:
基於“Proposal + Classification” 的 Object Detection 的方法,R-CNN 系列(R-CNN、SPPnet、Fast R-CNN 以及 Faster R-CNN),取得了非常好的結果,但是在速度方面離實時效果還比較遠在提高 mAP 的同時兼顧速度,逐漸成為 Object Detection 未來的趨勢。 YOLO 雖然能夠達到實時的效果,但是其 mAP 與剛面提到的 state of art 的結果有很大的差距。 YOLO 有一些缺陷:每個網格只預測一個物體,容易造成漏檢;對於物體的尺度相對比較敏感,對於尺度變化較大的物體泛化能力較差。針對 YOLO 中的這些不足,該論文提出的方法 SSD 在這兩方面都有所改進,同時兼顧了 mAP 和實時性的要求。在滿足實時性的條件下,接近 state of art 的結果。對於輸入影象大小為 300*300 在 VOC2007 test 上能夠達到 58 幀每秒( Titan X 的 GPU ),72.1% 的 mAP。輸入影象大小為 500 *500 , mAP 能夠達到 75.1%。作者的思路就是Faster R-CNN+YOLO,利用YOLO的思路和Faster R-CNN的anchor box的思想。
關鍵點:
關鍵點1:網路結構
該論文采用 VGG16 的基礎網路結構,使用前面的前 5 層,然後利用 astrous 演算法將 fc6 和 fc7 層轉化成兩個卷積層。再格外增加了 3 個卷積層,和一個 average pool層。不同層次的 feature map 分別用於 default box 的偏移以及不同類別得分的預測(慣用思路:使用通用的結構(如前 5個conv 等)作為基礎網路,然後在這個基礎上增加其他的層),最後通過 nms得到最終的檢測結果。
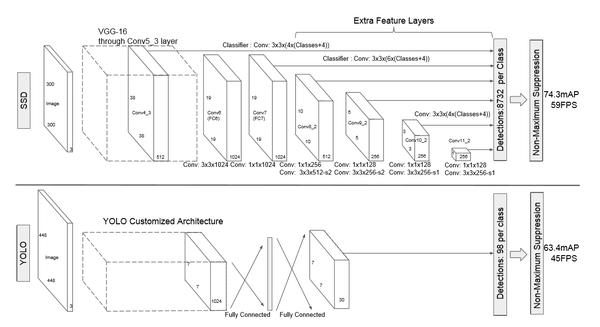
這些增加的卷積層的 feature map 的大小變化比較大,允許能夠檢測出不同尺度下的物體: 在低層的feature map,感受野比較小,高層的感受野比較大,在不同的feature map進行卷積,可以達到多尺度的目的。觀察YOLO,後面存在兩個全連線層,全連線層以後,每一個輸出都會觀察到整幅影象,並不是很合理。但是SSD去掉了全連線層,每一個輸出只會感受到目標周圍的資訊,包括上下文。這樣來做就增加了合理性。並且不同的feature map,預測不同寬高比的影象,這樣比YOLO增加了預測更多的比例的box。(下圖橫向的流程)
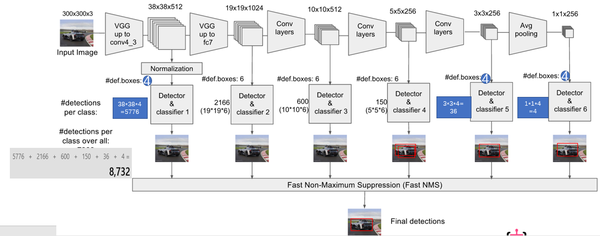
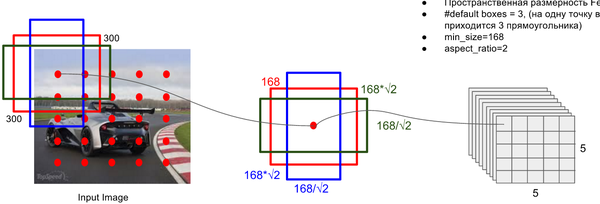
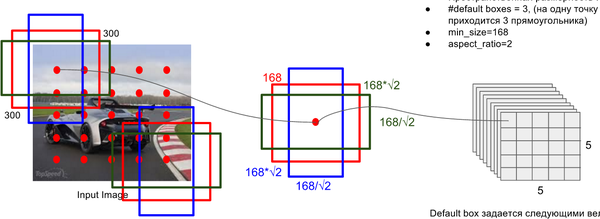
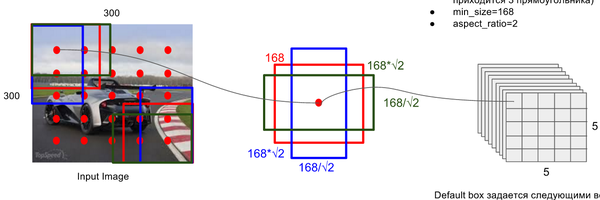
關鍵點2:多尺度feature map得到 default boxs及其 4個位置偏移和21個類別置信度
對於不同尺度feature map( 上圖中 38x38x512,19x19x512, 10x10x512, 5x5x512, 3x3x512, 1x1x256) 的上的所有特徵點: 以5x5x256為例 它的#defalut_boxes = 6
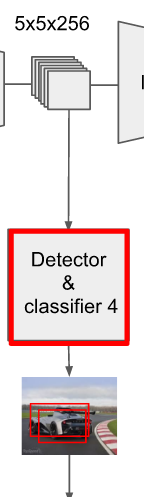
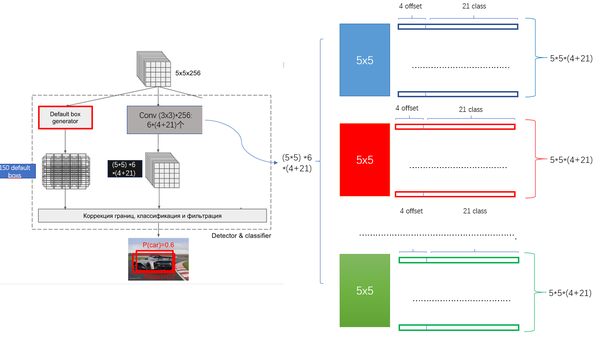
-
1 按照不同的 scale 和 ratio 生成,k 個 default boxes,這種結構有點類似於 Faster R-CNN 中的 Anchor。(此處k=6所以:5*5*6 = 150 boxes)
-
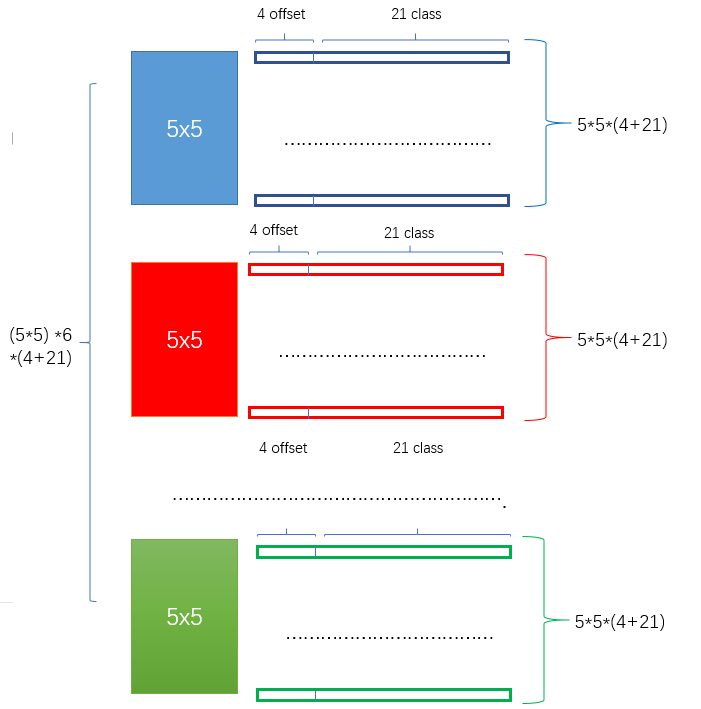
2 新增加的每個卷積層的 feature map 都會通過一些小的卷積核操作,得到每一個 default boxes 關於物體類別的21個置信度 (20個類別和1個背景) 和4偏移 (shape offsets) 。
- 假設feature map 通道數為 p 卷積核大小統一為 3*3*p (此處p=256)。個人猜想作者為了使得卷積後的feature map與輸入尺度保持一致必然有 padding = 1, stride = 1 :
-
假如feature map 的size 為 m*n, 通道數為 p,使用的卷積核大小為 3*3*p。每個 feature map 上的每個特徵點對應 k 個 default boxes,物體的類別數為 c,那麼一個feature map就需要使用 k(c+4)個這樣的卷積濾波器,最後有 (m*n) *k* (c+4)個輸出。
訓練策略
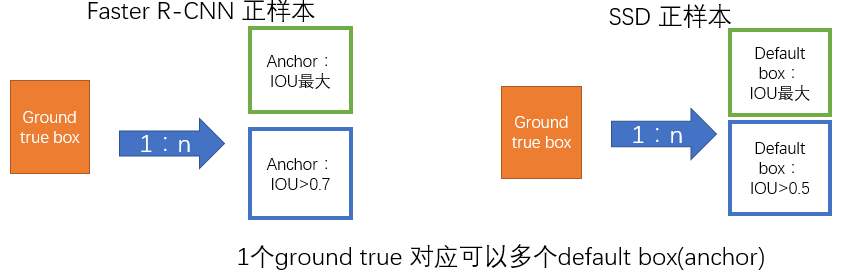
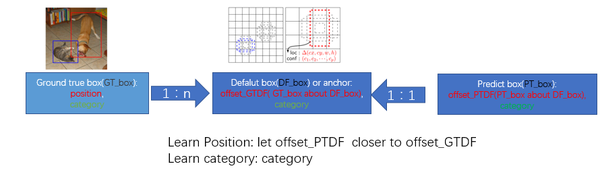
監督學習的訓練關鍵是人工標註的label。對於包含default box(在Faster R-CNN中叫做anchor)的網路模型(如: YOLO,Faster R-CNN, MultiBox)關鍵點就是如何把 標註資訊(ground true box,ground true category)對映到(default box上)
- 正負樣本: 給定輸入影象以及每個物體的 ground truth,首先找到每個ground true box對應的default box中IOU最大的作為(與該ground true box相關的匹配)正樣本。然後,在剩下的default box中找到那些與任意一個ground truth box 的 IOU 大於 0.5的default box作為(與該ground true box相關的匹配)正樣本。 一個 ground truth 可能對應多個 正樣本default box 而不再像MultiBox那樣只取一個IOU最大的default box。其他的作為負樣本(每個default box要麼是正樣本box要麼是負樣本box)。下圖的例子是:給定輸入影象及 ground truth,分別在兩種不同尺度(feature map 的大小為 8*8,4*4)下的匹配情況。有兩個 default box 與貓匹配(8*8),一個 default box 與狗匹配(4*4)。
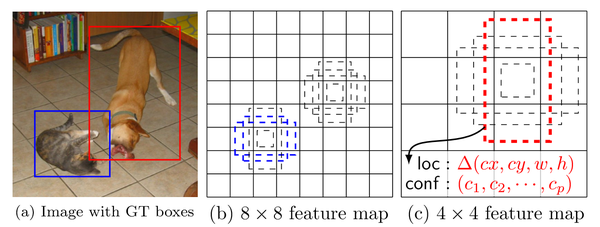
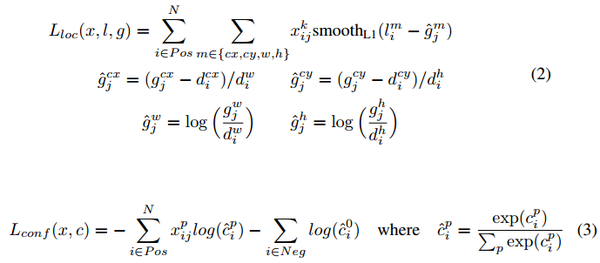
 該論文是在 ImageNet 分類和定位問題上的已經訓練好的 VGG16 模型中 fine-tuning 得到,使用 SGD,初始學習率為
該論文是在 ImageNet 分類和定位問題上的已經訓練好的 VGG16 模型中 fine-tuning 得到,使用 SGD,初始學習率為 -
在預測階段,直接預測每個 default box 的偏移以及對於每個類別相應的得分。最後通過 nms 的方式得到最後檢測結果。
Default Box 的生成:
該論文中利用不同層的 feature map 來模仿學習不同尺度下物體的檢測。
-
scale: 假定使用 m 個不同層的feature map 來做預測,最底層的 feature map 的 scale 值為 ,最高層的為 ,其他層通過下面公式計算得到
-
ratio: 使用不同的 ratio值 計算
default box 的寬度和高度:,。另外對於
ratio = 1 的情況,額外再指定 scale 為 也就是總共有
6 中不同的 default box。
- default box中心:上每個 default box的中心位置設定成 ,其中 表示第k個特徵圖的大小 。
Hard Negative Mining:
用於預測的 feature map 上的每個點都對應有 6 個不同的 default box,絕大部分的 default box 都是負樣本,導致了正負樣本不平衡。在訓練過程中,採用了 Hard Negative Mining 的策略(根據confidence loss對所有的box進行排序,使正負例的比例保持在1:3) 來平衡正負樣本的比率。這樣做能提高4%左右。
Data augmentation
為了模型更加魯棒,需要使用不同尺寸的輸入和形狀,作者對資料進行了如下方式的隨機取樣:
- 使用整張圖片
- 使用IOU和目標物體為0.1, 0.3,0.5, 0.7, 0.9的patch (這些 patch 在原圖的大小的 [0.1,1] 之間, 相應的寬高比在[1/2,2]之間)
- 隨機採取一個patch
當 ground truth box 的 中心(center)在取樣的 patch 中時,我們保留重疊部分。在這些取樣步驟之後,每一個取樣的 patch 被 resize 到固定的大小,並且以 0.5 的概率隨機的 水平翻轉(horizontally flipped)。用資料增益通過實驗證明,能夠將資料mAP增加8.8%。
參考:
相關推薦
【神經網路與深度學習】neural-style、chainer-fast-neuralstyle影象風格轉換使用
1. 安裝 我的作業系統是win10,裝了Anaconda,TensorFlow包是通過pip安裝的,中間沒什麼可說的.具體看TensorFlow官網就可以了. 2. 使用 python neural_style.py --content <content fi
【計算機視覺】【神經網路與深度學習】YOLO v2 detection訓練自己的資料
轉自:http://blog.csdn.net/hysteric314/article/details/54097845 說明 這篇文章是訓練YOLO v2過程中的經驗總結,我使用YOLO v2訓練一組自己的資料,訓練後的model,在閾值為.25的情況下,Reca
【神經網路與深度學習】【計算機視覺】SSD
背景介紹: 基於“Proposal + Classification” 的 Object Detection 的方法,R-CNN 系列(R-CNN、SPPnet、Fast R-CNN 以及 Faster R-CNN),取得了非常好的結果,但是在速度方面離實時效果還比較遠在提高 mAP 的同時兼顧速度,逐
【神經網路與深度學習】Google Protocol Buffer介紹
簡介 什麼是 Google Protocol Buffer? 假如您在網上搜索,應該會得到類似這樣的文字介紹: Google Protocol Buffer( 簡稱 Protobuf) 是 Google 公司內部的混合語言資料標準,目前已經正在使用的有超過 48,162 種報文格式定義和超過 12,1
【神經網路與深度學習】【C/C++】ZLIB學習
zlib(http://zlib.NET/)提供了簡潔高效的In-Memory資料壓縮和解壓縮系列API函式,很多應用都會用到這個庫,其中compress和uncompress函式是最基本也是最常用的。不過很奇怪的是,compress和uncompress函式儘管已經非常
【神經網路與深度學習】Win10+VS2015 caffe環境搭建(極其詳細)
caffe是好用,可是配置其環境實在是太痛苦了,依賴的庫很多不說,在VS上編譯還各種報錯,你能想象那種被一百多個紅色提示所籠罩的恐懼。 且網上很多教程是VS2013環境下編譯的,問人很多也說讓我把15解除安裝了裝13,我的答案是:偏不 記下這個艱難的過程,萬一還要再來
【神經網路與深度學習】Caffe原始碼中各種依賴庫的作用及簡單使用
1. Boost庫:它是一個可移植、跨平臺,提供原始碼的C++庫,作為標準庫的後備。 在Caffe中用到的Boost標頭檔案包括: (1)、shared_ptr.hpp:智慧指標,使用它可以不需要考慮記憶體釋放的問題; (2)、date_time/posi
【神經網路與深度學習】【C/C++】使用blas做矩陣乘法
#define min(x,y) (((x) < (y)) ? (x) : (y)) #include <stdio.h> #include <stdlib.h> #include <cublas_v2.h> #include <iostream>
【神經網路與深度學習】【計算機視覺】Fast R-CNN
先回歸一下: R-CNN ,SPP-net R-CNN和SPP-net在訓練時pipeline是隔離的:提取proposal,CNN提取特徵,SVM分類,bbox regression。 Fast R-CNN 兩大主要貢獻點 : 1 實現大部分end-to-end訓練(提proposal階段除外):
深度學習介紹(下)【Coursera deeplearning.ai 神經網路與深度學習】
1. shallow NN 淺層神經網路 2. 為什麼需要activation function? 如下圖所示,如果不用啟用函式,那麼我們一直都在做線性運算,對於複雜問題沒有意義。linear 其實也算一類啟用函式,但是一般只用在機器學習的迴歸問題,例如預測房價等。 3.
【神經網路和深度學習】筆記
文章導讀: 1.交叉熵損失函式 1.1 交叉熵損失函式介紹 1.2 在MNIST數字分類上使用交叉熵損失函式 1.3 交叉熵的意義以及來歷 1.4 Softmax 2. 過擬合和正則化 2.1 過擬合 2.2 正則化 2.3 為什麼正則化可以減輕
【神經網路和深度學習-開發案例】第四章 神經網路如何對數字進行分類
【神經網路和深度學習】 第四章 神經網路如何對數字進行分類 案例:使用神經網路識別手寫數字 好了,讓我們來寫一個程式,學習如何識別手寫的數字,使用隨機梯度下降和MNIST的訓練資料。我們將用一個簡短的Python(2.7)程式來完成這項工作,只
神經網路與深度學習課程筆記(第三、四周)
接著學習吳恩達老師第三、四周的課程。(圖片均來自吳恩達老師課件) 第三週 1. 普通的淺層網路
神經網路與深度學習課程筆記(第一、二週)
之前結束了吳恩達老師的機器學習的15節課,雖然看得很艱辛,但是也算是對於機器學習的理論有了一個入門,很多的東西需要不斷的思考以及總結。現在開始深度學習的學習,仍然做課程筆記,記錄自己的一些收穫以及思考。 第一週 1. ReLU (Rectified
分享《神經網路與深度學習(美)Michael Nielsen 著》中文版PDF+英文版PDF+原始碼
下載:https://pan.baidu.com/s/18_Y7fJMaKwFRKKuGjYIreg 更多資料分享:http://blog.51cto.com/3215120 《神經網路與深度學習(美)Michael Nielsen 著》中文版PDF+英文版PDF+原始碼中文版PDF,206頁,帶書籤目錄
deeplearning.ai神經網路與深度學習 第一章notes
神經網路與深度學習第一章 目錄 什麼是神經網路 用神經網路進行監督學習 為什麼深度學習會興起 什麼是神經網路 1.1定義 它是一個源於人腦工作機理的強大演算法 1.2單元神經網路 我們首先看一個例子,這個例子是一個房價評估問題。我們現在有一些資料,是房子的
《神經網路與深度學習(美)MichaelNielsen著》中英文版PDF+原始碼+吳岸城版PDF
資源連結:https://pan.baidu.com/s/1-v89VftxGHdzd4WAp2n6xQ《神經網路與深度學習(美)Michael Nielsen 著》中文版PDF+英文版PDF+原始碼以及《神經網路與深度學習 》(吳岸城版)中文版PDF,206頁,帶書籤目錄;英文版PDF,292頁,帶書籤目錄
吳恩達《神經網路與深度學習》課程筆記歸納(二)-- 神經網路基礎之邏輯迴歸
上節課我們主要對深度學習(Deep Learning)的概念做了簡要的概述。我們先從房價預測的例子出發,建立了標準的神經網路(Neural Network)模型結構。然後從監督式學習入手,介紹了Standard NN,CNN和RNN三種不同的神經網路模型。接著介紹了兩種不
吳恩達《神經網路與深度學習》課程筆記歸納(三)-- 神經網路基礎之Python與向量化
上節課我們主要介紹了邏輯迴歸,以輸出概率的形式來處理二分類問題。我們介紹了邏輯迴歸的Cost function表示式,並使用梯度下降演算法來計算最小化Cost function時對應的引數w和b。通過計算圖的方式來講述了神經網路的正向傳播和反向傳播兩個過程。本節課我們將來
Coursera 吳恩達《神經網路與深度學習》第三週程式設計作業
# Package imports import numpy as np import matplotlib.pyplot as plt from testCases import * import sklearn import sklearn.datasets impo