
模式識別:C-means(K-means)聚類演算法與分級聚類(層次聚類)演算法
C均值聚類演算法與分級聚類演算法的聚類分析
一、實驗目的
- 理解聚類的整體思想,瞭解聚類的一般方法;
- 掌握 C-means與分級聚類演算法演算法思想及原理,並能夠熟練運用這些演算法進行聚類分析;
- 能夠分析二者的優缺點
二、實驗內容
- 採用C均值聚類演算法對男女生樣本資料中的身高、體重2個特徵進行聚類分析,考察不同的類別初始值以及類別數對聚類結果的影響,並以友好的方式圖示化結果。
- 採用分級聚類演算法對男女生樣本資料進行聚類分析。嘗試採用身高,體重2個特徵進行聚類,並以友好的方式圖示化結果。
三、實驗原理
3.1 C-means
3.1.1演算法原理
C-means,常稱作K-means演算法,是基於距離的聚類演算法。採用距離作為相似性的評價指標,即認為兩個物件的距離越近,其相似度就越大。該演算法認為類簇是由距離靠近的物件組成的,因此把得到緊湊且獨立的簇作為最終目標。其基本思想:取定c 類,選取c 個初始聚類中心即 , 即代表點 。按最小距離原則將各樣本分配到離代表點最近的一類中 ,不斷重新計算類中心 , 調整 各樣本類別,最終使聚類準則函式 Je 最小。演算法採用誤差平方和準則函式作為聚類準則函式。
①用樣本間的距離(歐式距離)作為相似性度量
②用各類樣本與類均值間的平方誤差和作為聚類準則
定義準則函式:
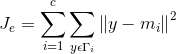
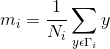
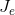
3.1.2 C-means聚類演算法流程(迭代優化)
輸入:樣本資料集D,聚類簇數c;輸出:各類簇的集合
步驟:初始化每個簇的均值向量
repeat:
a.(更新)簇劃分;
b. 計算每個簇的均值向量
until 當前均值向量均未更新
3.1.3 C-means聚類演算法虛擬碼
輸入:樣本集D={x_1,x_2,...,x_n};聚類簇數c
過程:
1
2:repeat
3:令C_i=Ø(1≤i≤c)
4:for j = 1,...,n do
5: 計算樣本x_j與各均值向量u_i(1≤i≤c)的距離:d_ji = ||x_j-u_i||2;
6: 根據距離最近的均值向量將x_j歸入該簇
7:end for
8:for i = 1,...,c do
9: 計算新的均值向量u'_i
10: if u'_i ≠ u_i then
11: 將當前均值向量u_i更新為u'_i
12: else
13: 保持當前均值向量不變
14: end if
15:end for
16:until 當前所有均值向量不再更新
17:return 簇劃分結果
輸出:簇劃分C={C_1,C_2,...,C_c}
3.2 分級聚類演算法
3.2.1演算法基本原理
思想:從各類只有一個樣本點開始, 逐級合併,每級只合並兩類,直到最後所有樣本都歸到一類。聚類過程中逐級考查類間相似度,依次決定類別數。在聚類過程中把 N 個沒有標籤的樣本分成一些合理的類時,極端情況下,最多可以分成 N 類,即每個樣本為一類;最少可以分成一類,即所有樣本為一類。那麼可以從 N 類到 1 類逐級地進行類別劃分,求得一系列類別數從多到少的劃分方案,然後根據一定的指標選擇中間某個適當地劃分方案作為聚類結果。分級聚類樹示例如圖3.1

圖3.1分級聚類樹
樹枝長度:反應節點之間的相似度或距離
距離/相似度量:如歐式距離(相似度量包括樣本之間的度量與聚類之間的度量)
常用的幾種類間相似度量:最近距離(single-link)、最遠距離(complete-link)、均值距離(average-link)
- 單鏈(MIN):定義簇的鄰近度為不同兩個簇的兩個最近的點之間的距離。
- 全鏈(MAX):定義簇的鄰近度為不同兩個簇的兩個最遠的點之間的距離。
- 組平均:定義簇的鄰近度為取自兩個不同簇的所有點對鄰近度的平均值。
3.2.2 演算法流程(自底向上)
a.將每個物件歸為一類, 共得到N類, 每類僅包含一個物件. 類與類之間的距離就是它們所包含的物件之間的距離;
b.找到最接近的兩個類併合併成一類, 於是總的類數少了一個;
c.重新計算新的類與所有舊類之間的距離;
d.重複第2步和第3步, 直到最後合併成一個類為止(此類包含了N個物件)。
四、實驗平臺
本實驗程式設計運用Python語言完成。
4.1讀取Excel資料應用了擴充套件工具包xlrd;
4.2 對於kmeans聚類演算法函式的呼叫應用的了擴充套件工具包sklearn.cluster中的主函式KMeans()。其主要引數如下:
1).n_clusters:簇的個數,即你想聚成幾類
2).init: 初始簇中心的獲取方法。有三個可選值:’k-means++’, ‘random’,或者傳遞一個ndarray向量。此引數指定初始化方法,預設值為 ‘k-means++’。本實驗我們使用該方法來獲取初始質心。
①‘k-means++’ 用一種特殊的方法選定初始質心從而能加速迭代過程的收斂。k-means++演算法選擇初始seeds的基本思想就是:初始的聚類中心之間的相互距離要儘可能的遠。
演算法步驟: (1)從輸入的資料點集合中隨機選擇一個點作為第一個聚類中心 (2)對於資料集中的每一個點x,計算它與最近聚類中心(指已選擇的聚類中心)的距離D(x) (3)選擇一個新的資料點作為新的聚類中心,選擇的原則是:D(x)較大的點,被選取作為聚類中心的概率較大 (4)重複2和3直到k個聚類中心被選出來
(5)利用這k個初始的聚類中心來執行標準的k-means演算法
②‘random’ 隨機從訓練資料中選取初始質心。
3).n_init: 獲取初始簇中心的更迭次數,為了彌補初始質心的影響,演算法預設會初始10次質心,實現演算法,然後返回最好的結果。
4).max_iter: 最大迭代次數(因為kmeans演算法的實現需要迭代)
4.3對於分級聚類演算法函式的呼叫應用到了scipy.cluster中的主函式hierarchy.linkage()。或者擴充套件工具包sklearn.cluster中的主函式AgglomerativeClustering()。
五、實驗結果
5.1 C-means聚類演算法結果與分析
將聚類數目c分別取2,3。聚類結果如下圖5-1與5-2:
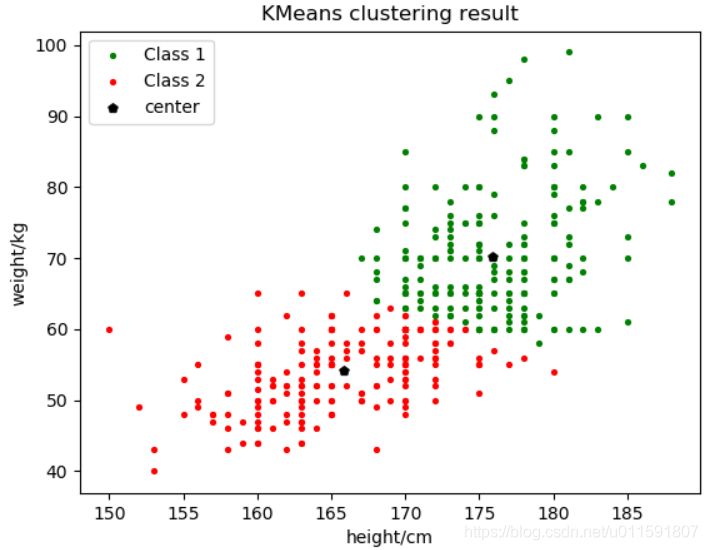

圖5-1聚為2類 圖5-2 聚為3類
質心位置如下表:
| 聚類c |
初始質心 |
Class1質心 |
Class2質心 |
Class3質心 |
|
2類 |
k-means++ |
(175.9,70.3) |
(165.8,54.1) |
|
|
3類 |
k-means++ |
(163.4,51.4)
|
(173.2,62.9) |
(177.8,78.2) |
若開始未知類別數,畫出C值與之間的關係曲線如下圖5-3:

圖5-3
由於已知樣本資料類別,故將樣本散點圖分佈與2聚類圖示做對比,如下圖5-4:
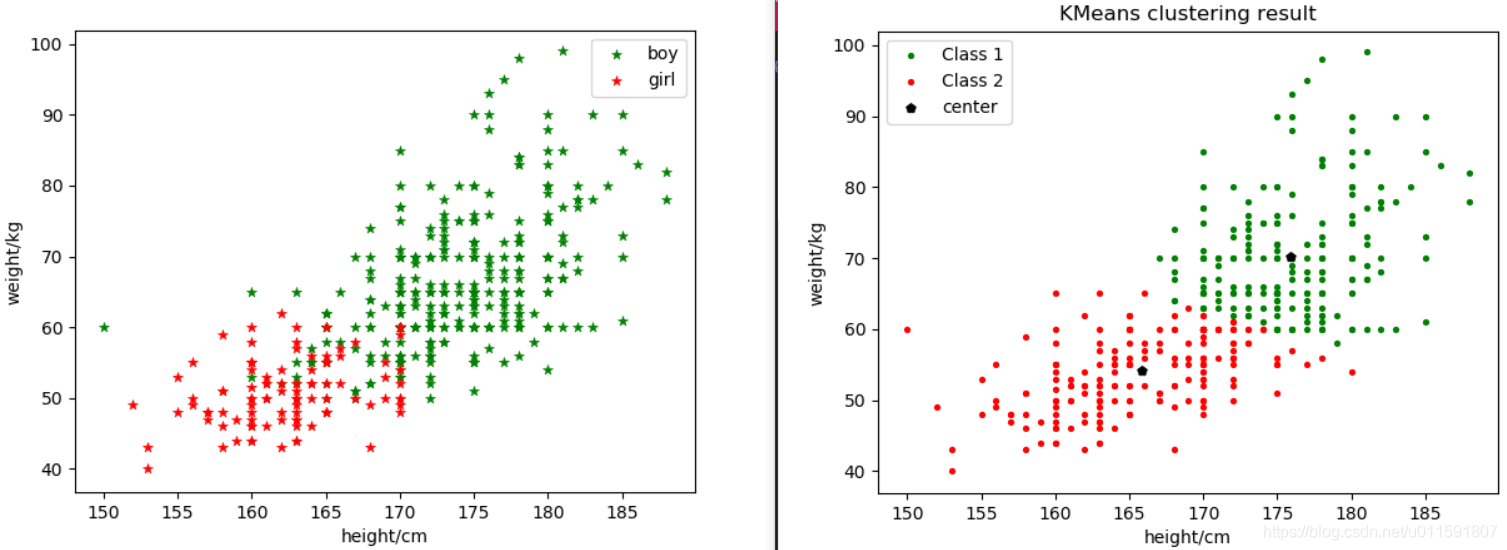
圖5-4
結果分析:由以上結果圖示可知,該樣本資料分為3類比較合理,但由於樣本為性別劃分,只可分為兩類。由2聚類結果圖示可知,在兩類分界處周圍出現了很多的錯誤劃分,主要是部分男生跟女生劃為一類。這些錯誤劃分的樣本資料,都體現出了體重較輕的情況(身高始終或者較矮),而這些特點與女生的體重特徵相符,所以才可能導致錯誤的劃分。這同時也說明,在做聚類時,特徵的選取非常重要。
5.2分級聚類結果與分析
將聚類數目c分別取2,3。聚類結果如下圖5-5與5-6:


圖5-5聚為2類 圖5-6聚為3類
樣本分級聚類枝狀圖如下圖5-7與5-8,分別採用不同的相似度量:
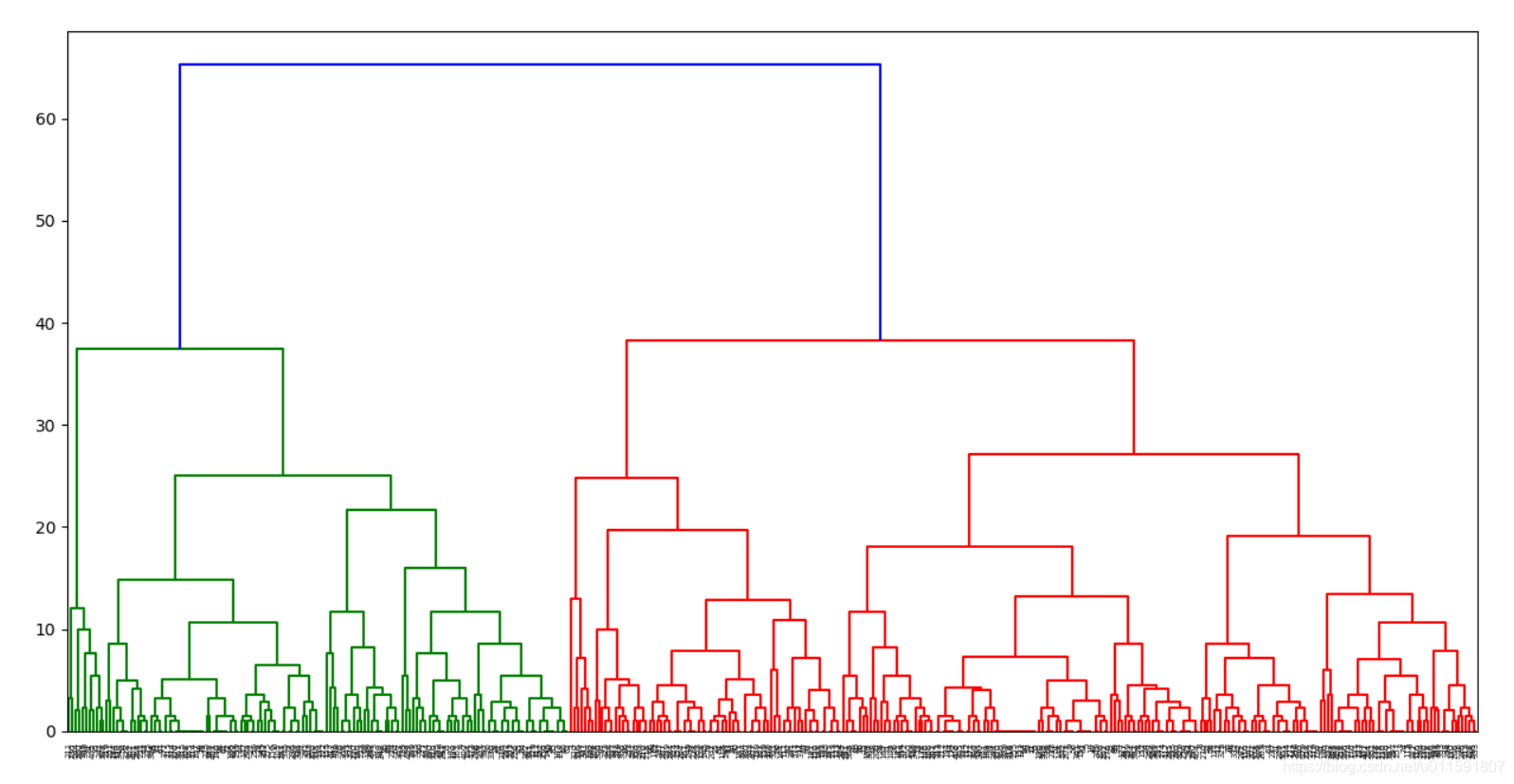
圖5-7分級聚類枝狀圖(相似度量complete)

圖5-8分級聚類枝狀圖(相似度量ward)
由於已知樣本資料類別,故將樣本散點圖分佈與2聚類圖示做對比,如下圖5-9:


圖5-9
結果分析:對於同一樣本集,聚為幾類並不會影響分級樹的形狀和聚類效果,只需要在不同的級數水平畫分界線就可得到分類情況。由圖5-1與5-5對比可知二兩聚類演算法得到的二分聚類結果很相似,沒有太大差別,都出現將部分男生錯分為女生的現象。層次聚類判斷相似度的方法在很大程度上會影響聚類的結果,因為可以看出分級聚類枝狀圖明顯有所不同。
從實驗結果來看,分級聚類的關鍵是:選取的特徵是否能夠完整地表徵樣本的資訊與如何選擇相似性度量。
5.2兩者的優缺點
|
|
優點 |
缺點 |
|
Kmeans |
(1)演算法快速、簡單; (2)對大資料集有較高的效率並且是可伸縮性的; (3)時間複雜度近於線性,而且適合挖掘大規模資料集。K-Means聚類演算法的時間複雜度是O(nkt) ,其中n代表資料集中物件的數量,t代表著演算法迭代的次數,k代表著簇的數目; (4)當結果簇是密集的,簇與簇之間區別明顯時,它的效果較好。
|
(1)在 K-means 演算法中 K 是事先給定的,這個 K 值的選定是非常難以估計的。有的演算法是通過類的自動合併和分裂,得到較為合理的型別數目 K,例如 ISODATA 演算法; (2)初始聚類中心的選擇對聚類結果有較大的影響,一旦初始值選擇的不好,可能無法得到有效的聚類結果; (3)它對於“噪聲”與孤立的點樣本是很敏感的,少量的該類樣本對資料d的平均值產生很大的影響。 |
|
|
優點 |
缺點 |
|
分級聚類 |
(1)層次聚類最主要的優點是叢集不再需要假設為類球形。另外其也可以擴充套件到大資料集; (2)對於K-means不能解決的非球形族就可以解決了; (3)可解釋性好。
|
(1)缺點是已做的分裂操作不能撤銷,類之間不能交換物件。如果在某步沒有選擇好分裂點,可能會導致低質量的聚類結果。大資料集不太適用; (2)時間複雜度高,o(m^3),改進後的演算法也有o(m^2lgm),m為點的個數;為貪心演算法,對當前獲得最優,一旦出錯將無法糾正; |
六、實驗心得
通過本次實驗,深入瞭解了kmeans聚類演算法與分級聚類演算法的思想與原理。同時熟練了對python的應用使用程度。也對演算法的相似度如何影響聚類效果有了更直觀的認識與理解。以及python中Kmeans如何獲取優良初始聚類中心的‘k-means++’方法,使每次聚類結果儘可能相同。由於本次資料樣本集較少,兩類演算法的分類結果相似,沒有很大差別。還無法直觀的看到兩者的分類區別。也只能從時間複雜度上來分析二者的不同了。
七、完整程式碼
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @Date : 2018-11-19 19:06:12
# @Author : Taylen Lee
# @Link : https://blog.csdn.net/u011591807
# @Version : 0.1
import xlrd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.cluster import AgglomerativeClustering
from scipy.cluster import hierarchy
from itertools import cycle #python自帶的迭代器模組
'''
/**************************task1**************************/
1.採用C均值聚類演算法對男女生樣本資料中的身高、體重2個特徵進行聚類分析,
考察不同的類別初始值以及類別數對聚類結果的影響,並以友好的方式圖示化結果。
/**************************task1**************************/
'''
mydata = xlrd.open_workbook('D:/program/py_code/data_2018.xls')
mysheet1 = mydata.sheet_by_name("Sheet1")
#獲取行數、列數
nRows = mysheet1.nrows
nCols = mysheet1.ncols
#用於存取男生女生身高資料
man_height = []
woman_height = []
man_weight = []
woman_weight = []
height_weight = []
#獲取第4,5列的內容:身高,體重
for i in range(nRows):
if i+1<nRows:
if mysheet1.cell(i+1,1).value==1:
man_height.append(mysheet1.cell(i+1,3).value)
man_weight.append(mysheet1.cell(i+1,4).value)
elif mysheet1.cell(i+1,1).value==0:
woman_height.append(mysheet1.cell(i+1,3).value)
woman_weight.append(mysheet1.cell(i+1,4).value)
height_weight.append([(mysheet1.cell(i+1,3).value),(mysheet1.cell(i+1,4).value)])
height_weight = np.array(height_weight)
#顯示男女生樣本散點圖
plt.figure(1)
plt.clf()
p1=plt.scatter(man_height, man_weight,c='g', marker = '*',linewidths=0.4)
p2=plt.scatter(woman_height, woman_weight,c='r', marker = '*',linewidths=0.4)
plt.xlabel('height/cm')
plt.ylabel('weight/kg')
gender_label=['boy','girl']
plt.legend([p1, p2],gender_label,loc=0)
plt.show()
#聚類數為2
kmeans_n_clusters = 2
#構造聚類器,聚類數為2
#kmeans_clusterer = KMeans(kmeans_n_clusters)
kmeans_clusterer = KMeans(n_clusters=kmeans_n_clusters,init='random',n_init=1)
#訓練聚類
kmeans_clusterer.fit(height_weight)
kmeans_cluster_label = kmeans_clusterer.labels_ #獲取聚類標籤
#print('kmeans_label_pred:',kmeans_cluster_label)
kmeans_cluster_center = kmeans_clusterer.cluster_centers_ #獲取聚類中心
#print('kmeans_cluster_center:',kmeans_cluster_center)
kmeans_inertia = kmeans_clusterer.inertia_ # 獲取聚類準則的總和
#print('kmeans_inertia:',kmeans_inertia)
#繪圖,顯示聚類結果
plt.figure(2)
plt.clf()
#markers = ['^', 'x', 'o', '*', '+']
colours = ['g', 'r', 'b', 'y', 'c']
#class_label = ['Class 1','Class 2','Class 3','Class 4','Class 5','center']
class_label = ['Class 1','Class 2','Class 3','center']
for i in range(kmeans_n_clusters):
kmeans_members = kmeans_cluster_label == i
plt.scatter(height_weight[kmeans_members, 0], height_weight[kmeans_members, 1], s=30, c=colours[i], marker='.')
#plt.legend(class_label,loc=0)
plt.title('KMeans clustering result')
plt.xlabel('height/cm')
plt.ylabel('weight/kg')
#顯示聚類中心
for i in range(kmeans_n_clusters):
plt.scatter(kmeans_cluster_center[i][0], kmeans_cluster_center[i][1], marker = 'p', c='k', linewidths=0.4)
#plt.annotate((kmeans_cluster_center[i][0], kmeans_cluster_center[i][1]), xy = (kmeans_cluster_center[i][0], kmeans_cluster_center[i][1]))
plt.legend(class_label,loc=0)
plt.show()
#確定最優聚類數,將將結果視覺化
plt.clf()
inertia_Je = []
k = []
#簇的數量
for n_clusters in range(1,10):
cls = KMeans(n_clusters).fit(height_weight)
inertia_Je.append(cls.inertia_)
k.append(n_clusters)
plt.scatter(k, inertia_Je)
plt.plot(k, inertia_Je)
plt.xlabel("k")
plt.ylabel("Je")
plt.show()
'''
/**************************task2**************************/
2.(#Hierarchical clustering)採用分級聚類演算法對男女生樣本資料進行聚類分析。
嘗試採用身高,體重2個特徵進行聚類,並以友好的方式圖示化結果。
/**************************task2**************************/
'''
'''
#指定層次聚類判斷相似度的方法:
complete:將兩個組合資料點中距離最遠的兩個資料點間的距離作為這兩個組合資料點的距離。
single :方法代表將兩個組合資料點中距離最近的兩個資料點間的距離作為這兩個組合資料點的距離。
這種方法容易受到極端值的影響。
average :計算兩個組合資料點中的每個資料點與其他所有資料點的距離。將所有距離的均值作為兩個
組合資料點間的距離。這種方法計算量比較大,但結果比前兩種方法更合理。
centroid:向量二範數
'''
linkages = ['ward', 'average', 'complete', 'single', 'average,' 'weighted', 'centroid']
hierarchical_n_clusters = 3 #構造聚類器,聚類數為2
'''
#方法一:利用sklearn.cluster.AgglomerativeClustering進行層次聚類,只適應linkages元素0-3
hierarchical_clusterer = AgglomerativeClustering(linkage=linkages[0],n_clusters = hierarchical_n_clusters)
#訓練資料
hierarchical_clusterer.fit(height_weight)
hierarchical_cluster_lables = hierarchical_clusterer.labels_ #每個資料的分類標籤
#print('hierarchical_cluster_lables:',hierarchical_cluster_lables)
#繪圖
plt.figure(3)
plt.clf()
colors = cycle('bgrcmyk')
for k, col in zip(range(hierarchical_n_clusters), colors):
##根據hierarchical_cluster_lables中的值是否等於k,重新組成一個True、False的陣列
hierarchical_members = hierarchical_cluster_lables == k
#height_weight[my_members, 0] 取出hierarchical_members對應位置為True的值的橫座標
plt.plot(height_weight[hierarchical_members, 0], height_weight[hierarchical_members, 1], col + '.')
plt.title('Hierarchical clustering result.Estimated number of clusters: %d' % hierarchical_n_clusters)
plt.show()
'''
#方法二:使用scipy進行層次聚類
Z = hierarchy.linkage(height_weight, method ='ward',metric='euclidean') #作用與以下兩句程式碼作用相同
'''
disMat = hierarchy.distance.pdist(points,'euclidean') #生成點與點之間的距離矩陣,歐氏距離
Z=hierarchy.linkage(disMat,method='average') #進行層次聚類
'''
hierarchy.dendrogram(Z)
plt.savefig('plot_dendrogram.png') #將層級聚類結果以樹狀圖表示出來並儲存為plot_dendrogram.png
label = hierarchy.cut_tree(Z,height=200) #在不同的位置裁剪即可得到不同的聚類數目,height要根據樹狀圖的高度與分類的數目進行調整
label = label.reshape(label.size,)
#繪圖
plt.figure(4)
plt.clf()
colors = cycle('bgrcmyk')
for k, col in zip(range(hierarchical_n_clusters), colors):
#根據hierarchical_cluster_lables中的值是否等於k,重新組成一個True、False的陣列
hierarchical_members = label == k
#height_weight[my_members, 0] 取出hierarchical_members對應位置為True的值的橫座標
plt.plot(height_weight[hierarchical_members, 0], height_weight[hierarchical_members, 1], col + '.')
plt.legend(class_label,loc=0)
#plt.title('Hierarchical clustering result.Estimated number of clusters: %d' % hierarchical_n_clusters)
plt.title('Hierarchical clustering result')
plt.xlabel('height/cm')
plt.ylabel('weight/kg')
plt.show()