
目標檢測演算法:RCNN、YOLO vs DPM
以下內容節選自我的研究報告。
1. 背景
目標檢測(object detection)簡單說就是框選出目標,並預測出類別的一個任務。它是一種基於目標幾何和統計特徵的影象分割,將目標的分割和識別合二為一,其準確性和實時性是整個系統的一項重要能力。尤其是在複雜場景中,需要對多個目標進行實時處理時,目標自動提取和識別就顯得特別重要[1]。

隨著計算機技術的發展和計算機視覺原理的廣泛應用,利用計算機影象處理技術對目標進行實時跟蹤研究越來越熱門,對目標進行動態實時跟蹤定位在智慧化交通系統、智慧監控系統、軍事目標檢測及醫學導航手術中手術器械定位等方面具有廣泛的應用價值。
2. 人工特徵
一般方法的步驟:滑窗提取特徵->分類器分類

圖2.2.1 DPM模型視覺化
文獻[2,3]提出的DPM模型應該是在目標檢測這塊最好的人工特徵方法。它對HOG特徵進行改進,並提出了全域性和區域性兩個模型(如圖2.2.1所示),大幅提高人工特徵在目標檢測上的精度。DPM的方法存在的缺點是特徵相對複雜,計算速度慢,對於旋轉、拉伸的物體檢測效果不好。因為無人機視訊普遍解析度比較大,且視角不固定,所以如果將DPM直接用來解決無人機視訊的目標檢測問題,很可能無法保證實時性和模型的泛化效能。
在2013年以前,利用深度學習進行目標檢測還未成為主流,大多數目標檢測的方法還是借鑑DPM方法的思路進行改進,並沒有發生本質變化的新方法提出,因而目標檢測的研究工作遭遇了瓶頸。3. 深度學習
在DPM方法遭遇瓶頸的時候,也有一部分人在研究如何利用深度學習進行目標檢測。
文獻[4]提出了可以利用深度學習來處理目標檢測的問題,作者將檢測當作一個迴歸boundingbox的問題來處理,優點是相比於用滑動視窗來提取特徵的方式,這樣的方法更高效,但是檢測精度非常差,遠遠落後於人工特徵的方法。
既然迴歸的方法效果不好,那麼當作分類問題來處理會怎麼樣呢?Girshick在文獻[5-8]中做了這樣的一系列研究,形成了RCNN->SPPNet->fastRCNN->fasterRCNN的一條研究線。這類方法的一般步驟:候選區域生成->深度網路提取特徵->分類器分類,迴歸修正。
為了解決“將目標檢測當作分類問題處理會怎樣?”這個問題,RCNN出現了。
RCNN:使用過分割[9]生成候選區域,再使用CNN提取特徵,特徵分別送入多個SVM分類,迴歸修正boundingbox,最後使用NMS和邊緣檢測再次修正,整個過程如圖2.3.1所示。它的貢獻是檢測效果大幅提升,提出了用深度學習進行目標檢測的新框架,但是缺點也很明顯,各候選區域重複提取特徵導致速度很慢。
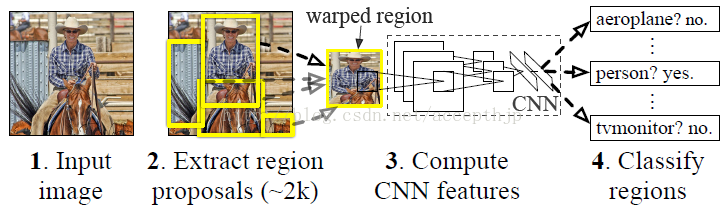
圖2.3.1 RCNN目標檢測流程
SPPNet:在最後一個卷積層後設計了空間金字塔池化層,這樣網路輸入可以不是一個固定的尺寸,能最大程度避免拉伸、裁剪造成影象的資訊損失。建立原始影象部分割槽域與提取特徵的對映關係,對於給定區域,可以直接計算特徵,避免重複卷積。
為了解決RCNN多個候選區域重複計算的問題,在借鑑SPPNet思想的基礎上,fast-RCNN出現了。
fast-RCNN:整個過程如圖2.3.2所示,與RCNN的不同在於有三個方面,加入了RoI pooling layer,這層與SPPNet的池化層作用相同;在充分實驗的基礎上,將SVM換成softmax;把分類和boundingbox迴歸放在同一個網路的後面進行,大幅減少了計算開銷。它的優點在於避免重複卷積,同時整合了多個任務,計算效率進一步提升。現在整個網路的架構和優化已基本完成,制約速度的關鍵在於候選區域的生成。
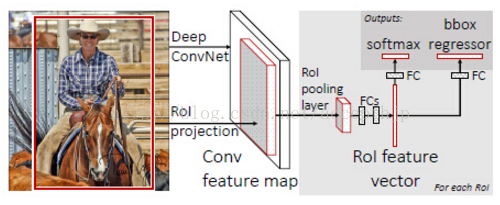
圖2.3.2 fast-RCNN目標檢測流程
為了解決Region proposal速度慢的問題,faster-RCNN出現了。
faster-RCNN:它的核心思想是將候選區域生成也交給網路來做。因為在下一個目標檢測的fast-RCNN中還需要修正目標位置,所以候選區域生成並不需要過於精確的方法。候選區域生成網路本質上也是一個fast-RCNN,它的輸入是預先設定好的影象中的一個區域,輸出是該區域屬於前景還是背景和修正後的區域。這樣的方法只指定了少數幾個可能為目標的區域,無論是比起滑窗,還是比起過分割,都快上了很多。
通過這一系列工作,網路的作用由單純提取特徵演化為完成目標檢測整個流程的一種深度架構,目標檢測的精度和速度也一再提高。現在,關於Faster-RCNN系列的工作也遇到了問題,以分類問題對待目標檢測暫時沒有什麼突破點,所以大家都在考慮以最開始的將目標檢測單純作為迴歸問題的思路進行研究。
RCNN系列的缺點在於將檢測問題轉化成了對圖片區域性區域的分類問題後,不能充分利用圖片區域性目標在整個圖片中的上下文資訊,於是文獻[10]又提出了一種將目標檢測作為迴歸問題的方法YOLO,整個過程如圖2.3.3所示。
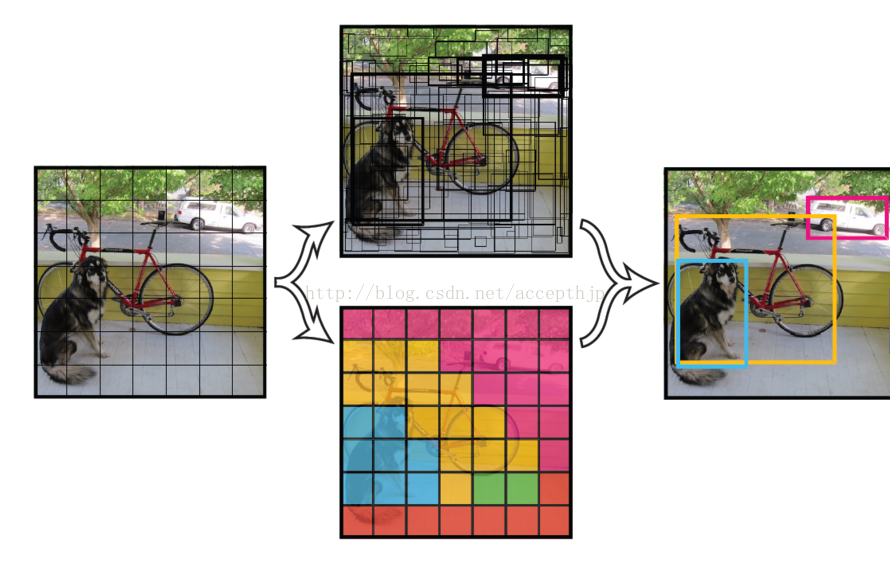
圖2.3.3 YOLO目標檢測流程
YOLO:將影象分成多個網格,分別迴歸boundingbox和信任值,最後以NMS過濾掉低分box。YOLO缺點在於對靠得很近的物體檢測效果不好,泛化能力弱,由於損失函式的問題,定位誤差是影響檢測效果的主要原因。即使YOLO目前還不完善,即使它比不上已經非常完善的faster-RCNN,但它的速度和精度都要好於人工特徵的方法,一旦解決了這些問題,效能將具有非常大的上升空間。現在最新的目標檢測方法為SSD,先佔個坑,以後有時間再來寫一下SSD。完全針對定位精度的研究工作LocNet等。
References:
[1] https://en.wikipedia.org/wiki/Object_detection
[2] Felzenszwalb P, McAllester D,Ramanan D. A discriminatively trained, multiscale, deformable partmodel[C]//CVPR, 2008: 1-8.
[3] Felzenszwalb P F, Girshick R B,McAllester D, et al. Object detection with discriminatively trained part-basedmodels[J]. PAMI, 2010, 32(9): 1627-1645.
[4] Szegedy C, Toshev A, Erhan D.Deep neural networks for object detection[C]//NIPS. 2013: 2553-2561.
[5] Girshick R, Donahue J, DarrellT, et al. Rich feature hierarchies for accurate object detection and semanticsegmentation[C]//CVPR. 2014: 580-587.
[6] Girshick R. Fast r-cnn[C]//ICCV.2015: 1440-1448.
[7] Ren S, He K, Girshick R, et al.Faster R-CNN: Towards real-time object detection with region proposalnetworks[C]//NIPS. 2015: 91-99.
[8] He K, Zhang X, Ren S, et al.Spatial pyramid pooling in deep convolutional networks for visualrecognition[C]//ECCV, 2014: 346-361.
[9] Uijlings J R R, van de Sande KE A, Gevers T, et al. Selective search for object recognition[J]. IJCV, 2013,104(2): 154-171.
[10] Redmon J, Divvala S, GirshickR, et al. You only look once: Unified, real-time object detection. CVPR, 2016.
相關推薦
目標檢測演算法:RCNN、YOLO vs DPM
以下內容節選自我的研究報告。 1. 背景 目標檢測(object detection)簡單說就是框選出目標,並預測出類別的一個任務。它是一種基於目標幾何和統計特徵的影象分割,將目標的分割和識別合
常用目標檢測演算法:R-CNN、Fast R-CNN、Faster R-CNN、YOLO、SSD
一、目標檢測常見演算法 object detection,就是在給定的圖片中精確找到物體所在位置,並標註出物體的類別。所以,object detection要解決的問題就是物體在哪裡以及是什麼的整個流程問題。
基於深度學習的目標檢測演算法:Faster R-CNN
問題引入: R-CNN、SPP net、Fast R-CNN等目標檢測演算法,它們proposals都是事先通過selecetive search方法得到。然而,這一過程將耗費大量的時間,從而影響目標檢測系統的實時性。Faster R-CNN針對這一問題,提
目標檢測演算法另一分支的發展(one stage檢測演算法):YOLO、SSD、YOLOv2/YOLO 9000、YOLOv3
目標檢測可以理解為是物體識別和物體定位的綜合,不僅僅要識別出物體屬於哪個分類,更重要的是得到物體在圖片中的具體位置。 目前的目標檢測演算法分為兩類: 一類是two-stage,two-stage檢測演算法將檢測問題劃分為兩個階段,首先產生候選區域(region proposals),然後
目標檢測演算法的演進(two-stage檢測演算法):R-CNN、SPP-Net、Fast R-CNN、Faster R-CNN、Mask R-CNN
什麼是目標檢測(object detection): 目標檢測(object detection),就是在給定的一張圖片中精確找到物體所在的位置,並標註出物體的類別。所以,目標檢測要解決的問題就是物體在哪裡以及是什麼的整個流程問題。 但是,在實際照片中,物體的尺寸變化範圍很大,擺放物體的
目標檢測演算法圖解:一文看懂RCNN系列演算法
在生活中,經常會遇到這樣的一種情況,上班要出門的時候,突然找不到一件東西了,比如鑰匙、手機或者手錶等。這個時候一般在房間翻一遍各個角落來尋找不見的物品,最後突然一拍大腦,想到在某一個地方,在整個過程中有時候是很著急的,並且越著急越找不到,真是令人沮喪。但是,如果一個簡單的計算機演算法可以在幾毫秒
深度學習目標檢測系列:一文弄懂YOLO演算法|附Python原始碼
在之前的文章中,介紹了計算機視覺領域中目標檢測的相關方法——RCNN系列演算法原理,以及Faster RCNN的實現。這些演算法面臨的一個問題,不是端到端的模型,幾個構件拼湊在一起組成整個檢測系統,操作起來比較複雜,本文將介紹另外一個端到端的方法——YOLO演算法,該方法操作簡便且模擬速度快,效
深度學習中目標檢測演算法 RCNN、Fast RCNN、Faster RCNN 的基本思想
前言 影象分類,檢測及分割是計算機視覺領域的三大任務。即影象理解的三個層次: 分類(Classification),即是將影象結構化為某一類別的資訊,用事先確定好的類別(string)或例項ID來描述圖片。這一任務是最簡單、最基礎的影象理解任務,也是深度學習模型最先取得突
目標檢測學習總結之RCNN、SPP-net、Fast RCNN、Faster RCNN、YOLO、SSD的區別
在計算機視覺領域,“目標檢測”主要解決兩個問題:影象上多個目標物在哪裡(位置),是什麼(類別)。 圍繞這個問題,人們一般把其發展歷程分為3個階段: 1. 傳統的目標檢測方法 2. 以R-CNN為代表的結合region proposal和CNN分類的目標檢測框架(R-CNN,
YOLO系列之YOLO-Lite:實時執行在CPU上的目標檢測演算法
實時目標檢測一直是yolo系列的追求之一,從yolo v1開始,作者就在論文中強調real-time。在後期的v2和v3的發展過程中,慢慢在P&R(尤其是recall rate)上下不少功夫。同時,計算量的增大也犧牲了yolo的實時性。 tiny-yolo是輕量級的
目標檢測演算法綜述:R-CNN,faster R-CNN,yolo,SSD,yoloV2
1 引言 深度學習目前已經應用到了各個領域,應用場景大體分為三類:物體識別,目標檢測,自然語言處理。上文我們對物體識別領域的技術方案,也就是CNN進行了詳細的分析,對LeNet-5 AlexNet VGG Inception ResNet MobileNet等各種優秀的模型
目標檢測演算法理解:從R-CNN到Mask R-CNN
因為工作了以後時間比較瑣碎,所以更多的時候使用onenote記錄知識點,但是對於一些演算法層面的東西,個人的理解畢竟是有侷限的。我一直做的都是影象分類方向,最近開始接觸了目標檢測,也看了一些大牛的論文,雖然網上已經有很多相關的演算法講解,但是每個人對同一個問題的理解都不太一樣,本文主
目標檢測演算法-rcnn
RCNN區域卷積神經網路 前言 RCNN詳解 1.摘要 2.訓練過程 3.測試過程 參考 1.RCNN(regions with CNN features)論文 2.知識點1:邊框迴歸(bo
Yolo-lite:實時的適用於移動裝置的目標檢測演算法(比ssd和mobilenet更快)
YOLO-LITE: A Real-Time Object Detection Algorithm Optimized for Non-GPU Computers 論文:Yolo-lite paper 專案:Yolo-lite 摘要: 作者提出了一種可以應用於行動式裝置中執行的
基於DL的目標檢測技術:R-CNN、Fast R-CNN、Faster R-CNN
目標檢測:在給定的圖片中精確找到物體所在位置,並標註出物體的類別。 目標檢測=影象識別(CNN)+定位(迴歸問題/取影象視窗) 遇到多物體識別+定位多個物體? 用選擇性搜尋找出可能含有物體的框(候選框)判定得分。這些框之間是可以互相重疊互相包含的,從而避免暴力列舉的所有框了。 1.R
基於深度學習的目標檢測演算法綜述:演算法改進
想了解深度學習的小夥伴們,看一下! 以後自己學深度學習了,再來看此貼! 只能發一個連結了: https://mp.weixin.qq.com/s?__biz=MzU4Nzc0NDI1NA==&mid=2247483731&idx=1&sn=37667093807751
論文筆記:目標檢測演算法(R-CNN,Fast R-CNN,Faster R-CNN,YOLOv1-v3)
R-CNN(Region-based CNN) motivation:之前的視覺任務大多數考慮使用SIFT和HOG特徵,而近年來CNN和ImageNet的出現使得影象分類問題取得重大突破,那麼這方面的成功能否遷移到PASCAL VOC的目標檢測任務上呢?基於這個問題,論文提出了R-CNN。 基本步驟:如下圖
深度學習目標檢測系列:faster RCNN實現|附python原始碼
目標檢測一直是計算機視覺中比較熱門的研究領域,有一些常用且成熟的演算法得到業內公認水平,比如RCNN系列演算法、SSD以及YOLO等。如果你是從事這一行業的話,你會使用哪種演算法進行目標檢測任務呢?在我尋求在最短的時間內構建最精確的模型時,我嘗試了其中的R-CNN系列演算法,如果讀者們對這方面的
理解yolo系列目標檢測演算法
在計算機視覺任務中,如果說做的最成熟的是影象識別領域,那麼緊隨其後的應該就是目標檢測了。筆者接觸目標檢測也有一段時間了,用mobilenet_ssd演算法做過手機端的實時目標檢測,也用faster-rcnn做過伺服器端的二維碼檢測,儘管一直都知道yolo的效果也
【目標檢測】Faster RCNN演算法詳解
Ren, Shaoqing, et al. “Faster R-CNN: Towards real-time object detection with region proposal networks.” Advances in Neural Information P