
python3 scrapy框架crawl模版爬取京東產品並寫入mysql
crawl將自動對所有連結進行分析,將符合的連結資料爬取。官方文件
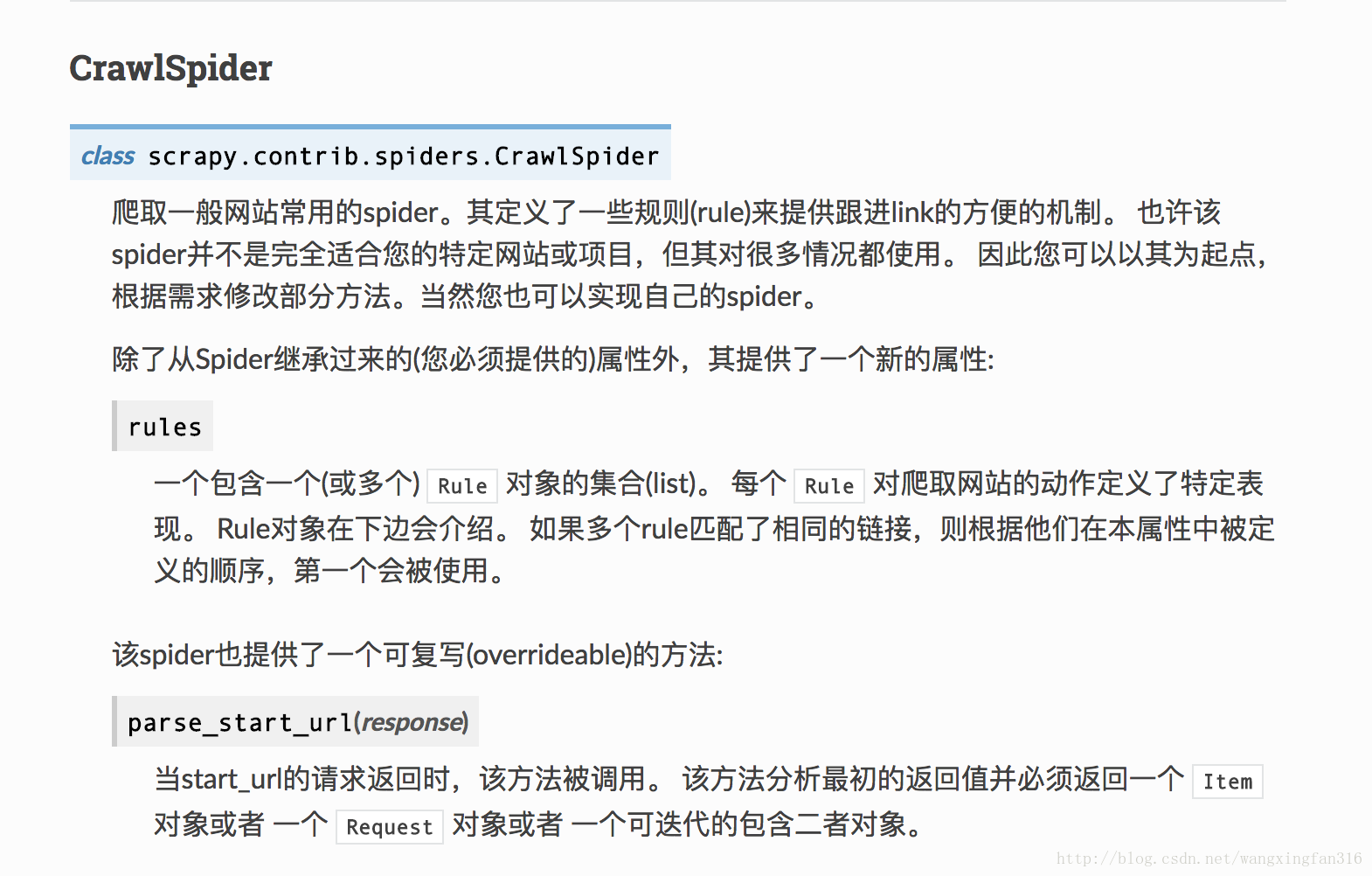
,其中價格,好評率需要用瀏覽器抓包分析真實地址,本文所用的基礎技術包括:sql語句,re表示式,xpath表示式,基本的網路知識和python基礎
jd.py
# -*- coding: utf-8 -*-
import scrapy
import urllib.request
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
import re
from jingdong.items import 嘗試執行

pipelines.py
# -*- coding: utf-8 -*-
import mysql.connector
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
class JingdongPipeline(object):
def process_item(self, item, spider):
db = mysql.connector.connect(host='localhost',
user='root',
passwd='123456',
db='python') # 連結資料庫
cur = db.cursor() # 獲取資料庫遊標
title = item['title']
link = item['link']
price = item['price']
goodRate = item['goodRate']
store = item['store']
print(title,link,price,goodRate,store)
cur.execute("insert into jingdong VALUES ('"+title+"','"+link+"','"+price+"','"+goodRate+"','"+store+"')") # 執行語句
db.commit() # 提交事務,沒有此句在資料庫中不能查詢到資料
cur.close() # 關閉遊標
db.close() # 關閉資料庫
相關推薦
python3 scrapy框架crawl模版爬取京東產品並寫入mysql
crawl將自動對所有連結進行分析,將符合的連結資料爬取。官方文件 ,其中價格,好評率需要用瀏覽器抓包分析真實地址,本文所用的基礎技術包括:sql語句,re表示式,xpath表示式,基本的網路知識和python基礎 jd.py # -*- codi
Python3爬蟲之五:爬取網站資料並寫入excel
本文主要講解如何將網頁上的資料寫入到excel表中,因為我比較喜歡看小說,我們就以筆趣閣的小說資料為例,來說明怎麼把筆趣閣的小說關鍵資訊統計出來,比如:小說名、字數、作者、網址等。 根據之前的幾次爬蟲例項分析筆趣網原始碼知道,小說名在唯一的標籤h1中,因此可以
scrapy框架 用post 爬取網站資料 的兩種方法區別
post請求,一定要重新呼叫父類的 start_requests(self)方法 方法1:(推薦) 重構start_requests def start_requests(self): data = { 'source': 'index_na
Scrapy框架的應用———爬取糗事百科檔案
專案主程式碼: 1 import scrapy 2 from qiushibaike.items import QiushibaikeItem 3 4 class QiubaiSpider(scrapy.Spider): 5 name = 'qiubai' 6
[爬蟲入門]Python中使用scrapy框架實現圖片爬取
轉載: https://www.jianshu.com/p/c1704b4dc04d 連結中作者寫的十分詳細,雖然示例中的網站已經無法訪問,但是零基礎效仿也能試著自己做! 真的很良心的文章,作為零基礎入門的小白可以靠看註釋和函式關係猜測出函式用法
利用scrapy框架遞迴爬取菜譜網站
介紹: 最近學習完scrapy框架後,對整個執行過程有了進一步的瞭解熟悉。於是想著利用該框架對食譜網站上的美食圖片進行抓取,並且分別按照各自的命名進行儲存。 1、網頁分析 爬取的網站是www.xinshipu.com,在爬取的過程中我發現使用xpath對網頁進行解析時總是找不到對應的標籤
Scrapy框架的學習(2.scrapy入門,簡單爬取頁面,並使用管道(pipelines)儲存資料)
上個部落格寫了: Scrapy的概念以及Scrapy的詳細工作流程 https://blog.csdn.net/wei18791957243/article/details/86154068 1.scrapy的安裝 pip install scrapy
【Python爬蟲】Scrapy框架運用1—爬取豆瓣電影top250的電影資訊(1)
一、Step step1: 建立工程專案 1.1建立Scrapy工程專案 E:\>scrapy startproject 工程專案 1.2使用Dos指令檢視工程資料夾結構 E:\>tree /f step2: 建立spid
Python爬蟲——實戰一:爬取京東產品價格(逆向工程方法)
在京東的單個產品頁面上,通過檢視原始碼檢查html,可以看到 <span class="p-price"><span>¥</span><span class="price J-p-1279836"></sp
爬蟲(進階),爬取網頁資訊並寫入json檔案
import requests # python HTTP客戶端庫,編寫爬蟲和測試伺服器響應資料會用到的類庫 import re import json from bs4 import BeautifulSoup import copy print('正在爬取網頁連結……'
python多執行緒抓取網頁內容並寫入MYSQL
自己的第一個多執行緒練習,中間踩了不少坑,程式寫的很渣,但是勉強能實現功能需求了 ,實際上抓取網頁是多執行緒在MYSQL寫入的時候是加了執行緒鎖的 ,實際上感覺就不是在多執行緒寫入了,不過作為第一個練習程式就這樣吧 ,後續部落格還會繼續更新優化版本。## htm
Scrapy框架基於crawl爬取京東商品資訊爬蟲
Items.py檔案 # -*- coding: utf-8 -*- # Define here the models for your scraped items # See documentation in: # https://doc.scrapy.org/en/latest/topics
Python3 Scrapy框架學習五:使用crawl模板爬取豆瓣Top250,並存入MySql、MongoDB
1.新建專案及使用crawl模板 2.頁面解析 rules = (Rule(LinkExtractor(allow=r'subject/\d+/',restrict_css = '.hd > a[class = ""]'), callback='parse_it
使用scrapy框架,用模擬瀏覽器的方法爬取京東上面膜資訊,並存入mysql,sqlite,mongodb資料庫
因為京東的頁面是由JavaScript動態載入的所以使用模擬瀏覽器的方法進行爬取,具體程式碼如下 : spider.py # -*- coding: utf-8 -*- import scrapy from scrapy import Request from jdpro.items
Python3 Scrapy框架學習一:爬取貓眼Top100榜
以下操作基於Windows平臺。 開啟CMD命令提示框: 輸入 如下命令: 開啟專案裡的items.py檔案,定義如下變數,用於儲存。 class MaoyanItem(scrapy.Item): # define the fields for your
Python3 Scrapy框架學習二:爬取豆瓣電影Top250
開啟專案裡的items.py檔案,定義如下變數, import scrapy from scrapy import Item,Field class DoubanItem(scrapy.Item): # define the fields for your it
Python3 Scrapy框架學習三:爬取煎蛋網加密妹子圖片(全爬)
以下操作基於Windows平臺。 開啟CMD命令提示框: 新建一個專案如下: 開啟專案裡的setting檔案,新增如下程式碼 IMAGES_STORE = './XXOO' #在當前目錄下新建一個XXOO資料夾 MAX_PAGE = 40 #定義爬取的總得頁數
Python3 Scrapy框架學習四:爬取的資料存入MongoDB
1. 新建一個scrapy專案: 2.使用PyCharm開啟該專案 3.在settings.py檔案中新增如下程式碼: #模擬瀏覽器,應對反爬 USER_AGENT = 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebK
scrapy框架爬取京東商城商品的評論
一、Scrapy介紹 Scrapy是一個為了爬取網站資料,提取結構性資料而編寫的應用框架。 可以應用在包括資料探勘,資訊處理或儲存歷史資料等一系列的程式中。 所謂網路爬蟲,就是一個在網上到處或定向抓取資料的程式,當然,這種說法不夠專業,更專業的描述就是,抓取特定網站網頁的H
用scrapy爬取京東商城的商品信息
keywords XML 1.5 rom toc ons lines open 3.6 軟件環境: 1 gevent (1.2.2) 2 greenlet (0.4.12) 3 lxml (4.1.1) 4 pymongo (3.6.0) 5 pyO