
postgresql 9.3 自定義聚合函式實現多行資料合併成一列
前言
常見的一種需求,如下圖(1):
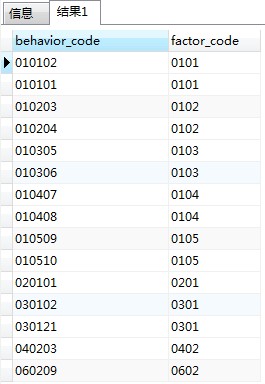
目前需要按右邊的factor_code進行分組,將左邊的behavior_code這一列通過指定分隔符連線起來,比如通過<br /> 來連線,理想的效果應當是如下圖(2)這樣:
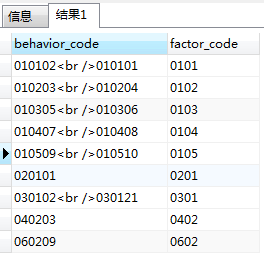
下面就來討論一下實現方式,假如在別的資料庫中來實現,例如MySQL或Oracle,好像沒有特別方便和直接的方式,同樣的在早期的Postgres中也是一件麻煩的事情,下面先看一下Postgres早期版本的解決方案~
postgres 8.x的解決方案
沒錯,同標題一樣,在postgres 8.x的版本中有幾種解決辦法,可以通過內建的陣列函式array_to_string
array_to_string
通過巢狀子查詢的方式來完成,缺點是寫法是略微麻煩,而且SQL層次不清晰,效率也不高,下面看一下SQL:
select array_to_string
(array(select behavior_code from t_evaluation_behavior t2 where t1.factor_code = t2.factor_code), '<br />') as behavior_code,
factor_code from t_evaluation_behavior t1 group 執行效果如圖(2)一致,接下來再看一下第二種解決方案,通過自定義function結合自定義聚合函式來實現。
建立自定義聚合函式(CREATE AGGREGATE)
這種方式使用簡便,就是第一次寫起來略微麻煩一點。思路和上一種一致,同樣是間接的利用了array_to_string函式,只不過是在一個自定義的function中去做了。關於自定義聚合函式,我們可以在官方文件中的CREATE ARRGREAGTE 章節中看到,在postgres 8.x和9.x中基本是一致的,僅有略微差別,如下圖(3)所示:

由於我本地的postgres是9.3,所以在此就著重演示一下9.3的CREATE AGGREGATE(關於實現多行資料合併成一列的最簡便方式不是這種,稍後在後面說)。
- name
要建立的聚集函式名(可以有模式修飾的)。
- base_type
本聚集函式要處理的基本資料型別。 對於不檢查輸入型別的聚集來說,這個引數可以宣告為”ANY”。 (比如 count(*))。
- sfunc
用於處理源資料列裡的每一個輸入資料的狀態轉換函式名稱。 它通常是一個雙引數的函式,第一個引數的型別是 state_data_type 而第二個引數的型別是 input_data_type. 另外,對於一個不檢查輸入資料的聚集,該函式只接受一個型別為 state_data_type 的引數。 不管是哪種情況,此函式必須返回一個型別為 state_data_type的值。 這個函式接受當前狀態值和當前輸入資料條目,而返回下個狀態值。
- state_data_type
聚集的狀態值的資料型別。
- ffunc
在轉換完所有輸入域/欄位後呼叫的最終處理函式。它計算聚集的結果。 此函式必須接受一個型別為 state_data_type 的引數。 聚集的輸出資料型別被定義為此函式的返回型別。 如果沒有宣告 ffunc 則使用聚集結果的狀態值作為聚集的結果,而輸出型別為 state_data_type
- initial_condition
狀態值的初始設定(值)。它必須是一個數據型別 state_data_type 可以接受的文字常量值。 如果沒有宣告,狀態值初始為 NULL。
- sort_operator
用於 MIN 或者 MAX 型別的聚集的相關的排序操作符。 這個只是一個操作符名(可以有模式修飾)。 這個操作符假設接受和聚集一樣的輸入資料型別。
OK,看完了所有的引數介紹,我們現在實現自己的聚合函式。
準備sfunc
這是第一步,sfunc需要我們自定義一個function,根據官方文件的描述,sfunc是一個狀態轉換函式,下面看一下文件中的這一段話:
PostgreSQL建立一個型別為stype的臨時變數。它儲存這個聚集的當前內部狀態。對於每個輸入資料條目,都呼叫狀態轉換函式計算內部狀態值的新數值。 在處理完所有資料後,呼叫一次最終處理函式以計算聚集的返回值。如果沒有最終處理函式, 則將最後的狀態值當做返回值。
OK,根據官方文件的描述需要兩個引數,一個是internal-state,一個是next-data-values。下面是sfunc的程式碼:
CREATE FUNCTION "public"."NewProc"(aa _text, s text)
RETURNS "pg_catalog"."_text" AS $BODY$
BEGIN
RETURN array_append(aa, s);
END;
$BODY$
LANGUAGE 'plpgsql' VOLATILE COST 100
;
ALTER FUNCTION "public"."NewProc"(aa _text, s text) OWNER TO "postgres";可以看到我們做的事情很簡單,就是將聚合的資料放到一個數組裡,當然也可以用一種更簡便的寫法來完成,即陣列操作符 ||,它可以直接將元素put到數組裡。
準備ffunc
完成了第一步之後,迴歸主題,我們要實現的是多行資料合併成一列,那麼很簡單,上面我們用過了array_to_string這個陣列函式,這裡我們同樣利用這個思路,將我們準備好的陣列通過指定的分隔符轉換成字串。下面是ffunc的程式碼:
CREATE FUNCTION "public"."NewProc"(aa _text)
RETURNS "pg_catalog"."text" AS $BODY$
BEGIN
RETURN array_to_string(aa, '<br />');
END;
$BODY$
LANGUAGE 'plpgsql' VOLATILE COST 100
;
ALTER FUNCTION "public"."NewProc"(aa _text) OWNER TO "postgres";很簡單,通過br分隔符將引數陣列轉換成字串並返回。
CREATE AGGREGATE
上面的兩個自定義函式都準備好之後,我們就可以建立我們自定義的聚合函數了,參考上面圖(3)的語法,寫出建立語句:
CREATE AGGREGATE ToOneRow(TEXT) (
SFUNC = SFUNC_ToOneRow,
STYPE = TEXT[],
FINALFUNC = FFUNC_ToOneRow
);這樣我們就建立完成了,趕緊嘗試執行一下是否可以使用:
select ToOneRow(behavior_code) as behavior_code,factor_code
from t_evaluation_behavior
group by factor_code order by factor_code;Congratulation!執行如上的SQL語句,依舊可以正確的得到和圖(2)一模一樣的結果。
最佳實踐(Best Practice)
如果是在8.x的版本中僅僅只能通過上述的方式解決問題了,但自從postgres 9之後,又新增了一批內建的聚合函式,其中就包含我們上面實現的那種方式,所以9.x的版本也就不需要我們再去自己建立了!下面看一下官方文件中提供的9.3版本的內建聚合函式表:
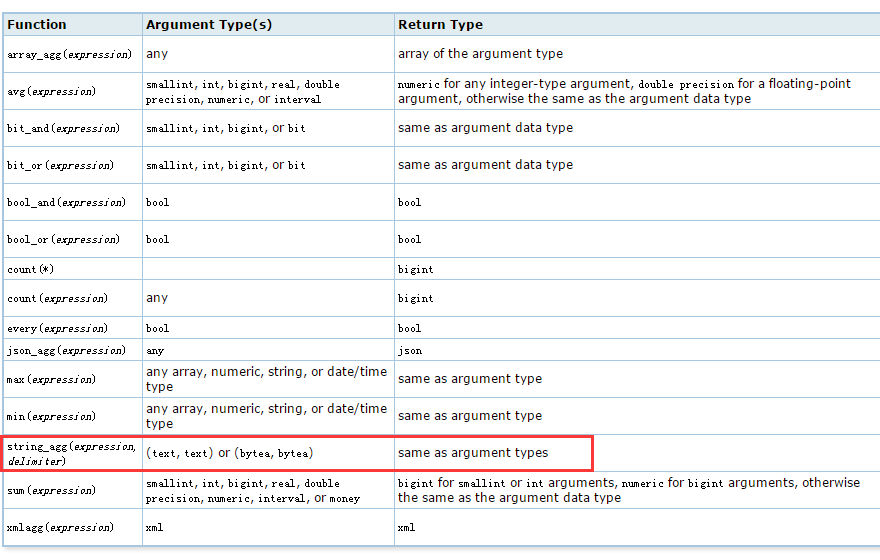
注意一下我用紅色標記出來的這個函式,是否有種豁然開朗的感覺呢?這裡不得不再次讚歎一下postgres確實很強大!趕緊測試一下是否有效:
select string_agg(behavior_code,'<br />') as behavior_code,factor_code
from t_evaluation_behavior
group by factor_code order by factor_code;Perfect!和圖(2)一模一樣!第一個引數是需要聚合的列名,第二個引數是分隔符,這樣就更加方便的完成了我們的需求~
總結
簡單記錄一下這種需求,以及postgres中自定義聚合函式的方法。如有錯誤的地方歡迎批評指正,The End。