
(Tensorflow Object Detection Api)ssd-mobilenet v1 演算法結構及程式碼介紹
通過前面三次分享,基本把Object Detection Api的入門使用方式就都陳列了出來。接下來計劃分享一下演算法的具體結構和程式碼的部分,以及相關的引數除錯方法。畢竟,真正拿來用的話,根據場景的不同,需要不同的效能和側重點。如下,僅對ssd-mobilenet-v1進行分享。
ssd原文 MobileNet V1論文
兩個月前剛開始搞物體檢測的專案的時候,我的想法是比較naive的,由於我要檢測的物體只有一類,我嘗試自己按照VGG-16的想法設計了簡單版的網路的結構,然後直接預測左上角和右下角座標。之所以這麼想,是因為覺得深度學習那麼強大,這麼簡單的功能應該很好實現想要的效果。可是,事與願違,
在之後研讀各種物體檢測演算法的過程中,發現其實神經網路並沒有強大到傻瓜式操作的境界,它還是需要精心的餵養,並且需要儘量多的提供給它各種維度的資訊,更加要考慮如何為它減負,而不是刁難它。
提供的資訊越多,神經網路的表現自然更好,比如在Reid中,有些人就嘗試在將原有資料集中的人的其他屬性,諸如衣服顏色,性別,年齡等加入到訓練中,這樣訓練出來的網路在Reid上的效果有很大提升,參見Improving Person Re-identification by Attribute and Identity Learning。
閒話太多了,開始講故事。RCNN系列的故事我這裡是不講的,這裡是按著YOLO和SSD的風格來講的。
到底該如何檢測圖片中的物體呢?看下面的圖吧。將原圖打散成7*7的格子,基於每個格子再預設2個不同長寬比的虛擬框,然後調整虛擬框的大小以使得虛擬框來擬合真實的物體邊框。大概的想法就是這樣的。模型不需要從整張圖片的角度來預測物體的位置,而是從區域性的角度來進行預測,為模型減負。而且,預設的不同長寬比的虛擬框,也是減輕模型負擔的一種方式,其實也給模型提供了更多的資訊。大概的思路就是如此。但是真正實施起來,各路大神開始各顯神通。我們先來說SSD。
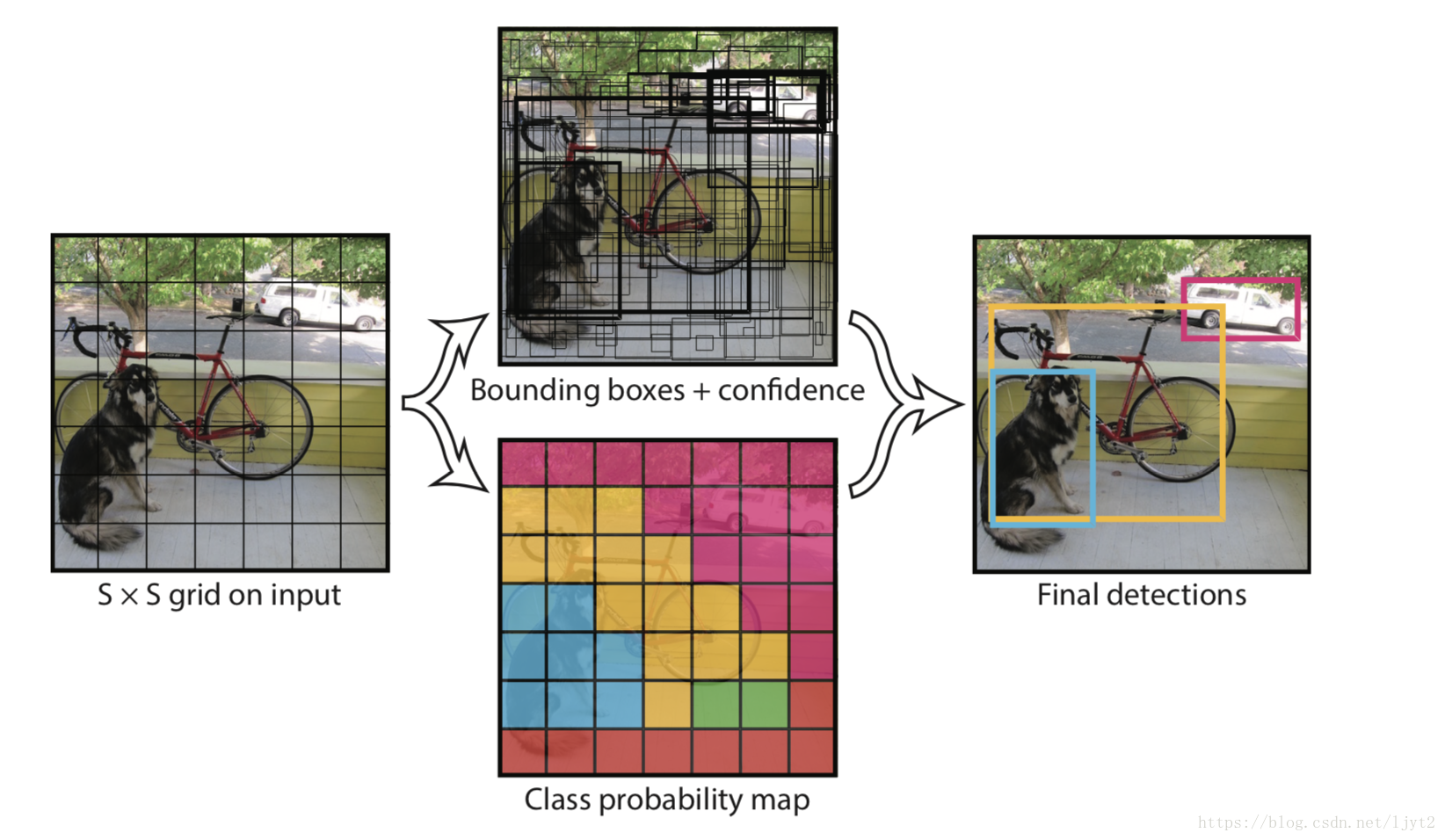
(一)先要說一些概念:見下圖

(二)剛才說過,將圖片打散成7*7的格子,然後針對每一個格子進行相應的預測。而神經網路的不同的部分的特徵圖其實就可以看作原影象打不同細緻程度的格子的結果,因為隨著網路深度增加,每個節點的感受野增大了,所以越往後的特徵圖打格子的程度越粗。反之越細緻。不同細緻程度的特徵圖正好可以用來檢測不同大小的物體,正如下圖所解釋的。
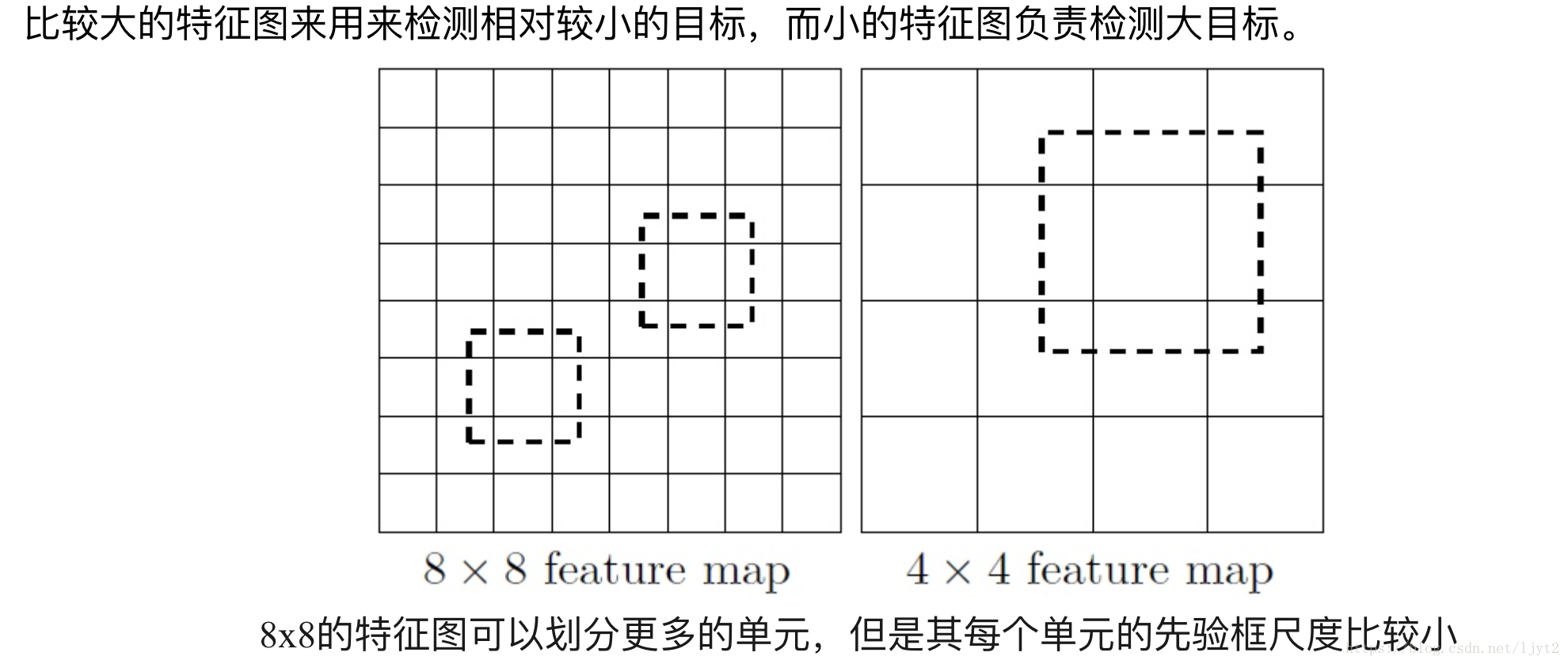
(三)理解到這裡之後,我們就可以看SSD-300的網路圖:
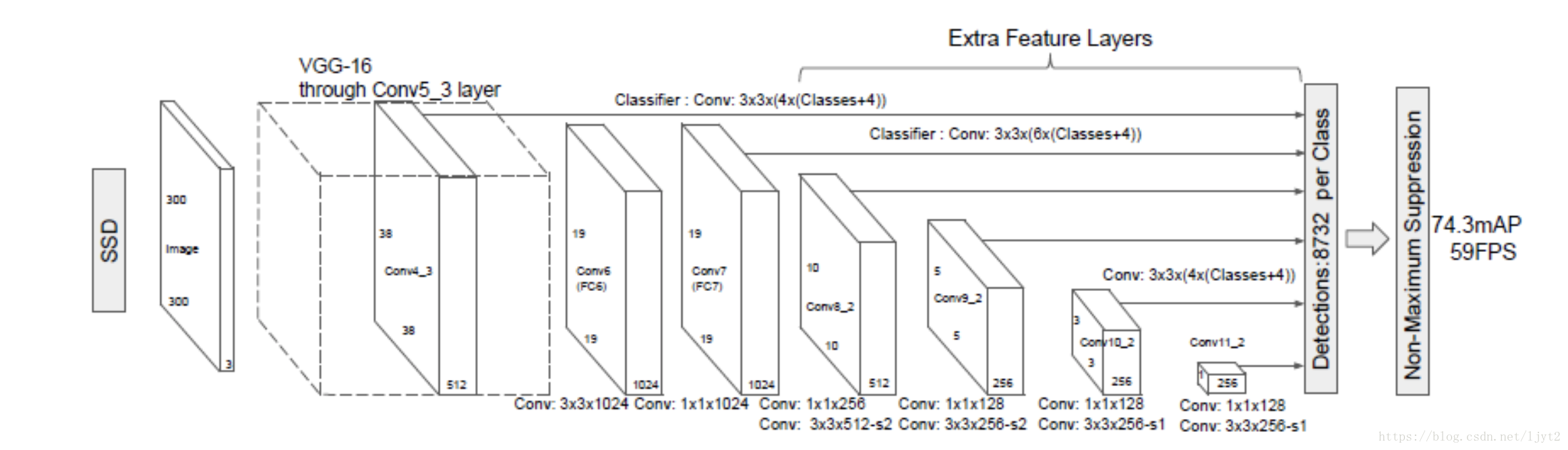
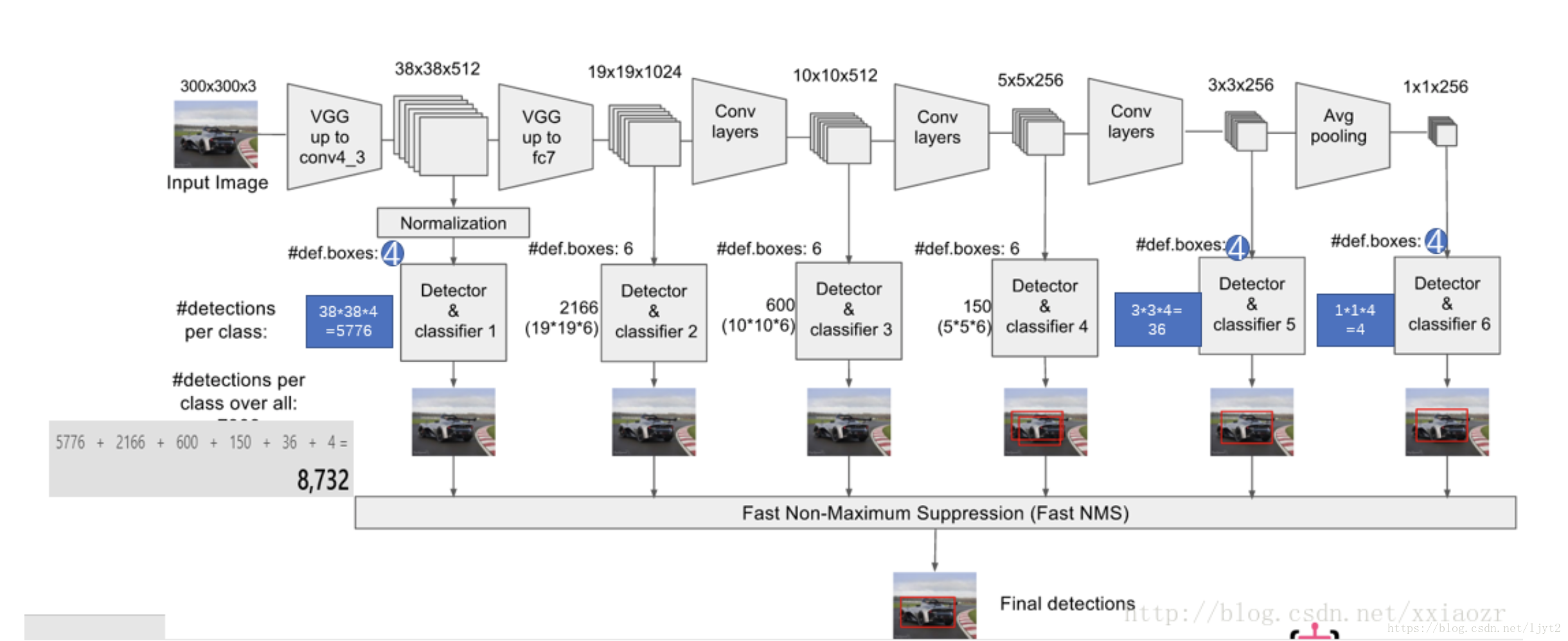

看到這裡應該也都不難理解,只是對不同的特徵圖進行預測。
(四)具體的邊框引數設定
剛才說了將圖片打成格子後,每個格子會相應有若干個不同長寬比的虛擬框,那麼這些虛擬框的大小到底是多大呢?不同特徵圖上的虛擬框的大小又有何區別?有一個前提,實現我們會將物體對應的真實邊框座標歸一化,也就是相應的除以原始圖片的長和寬。因此,下面說到的引數都是在0,1之間。
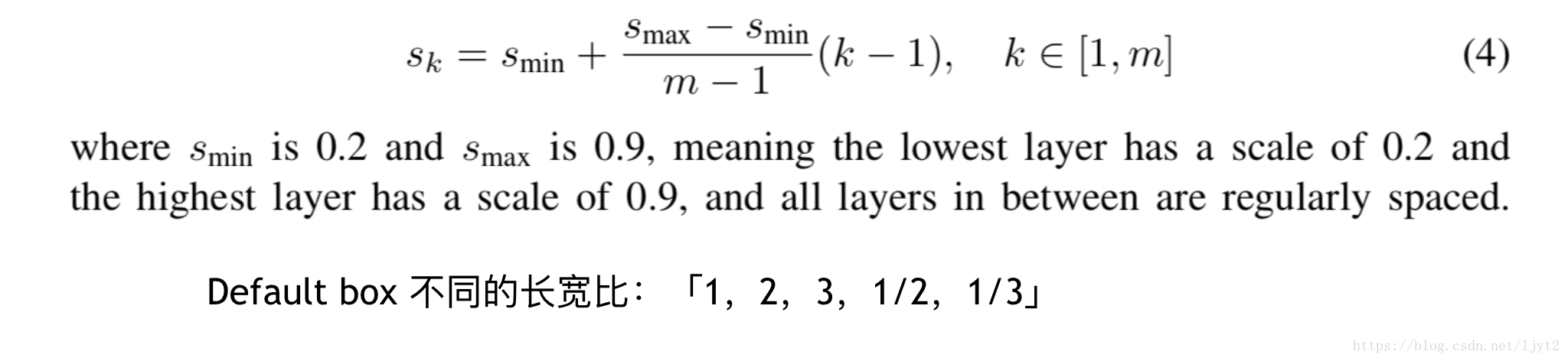

這是ssd的default box的大小的設定方式。
(五)到底是怎麼訓練啊?
如果只是看上面這些理論,估計很難搞懂。下面具體說一下,上面這些理論是怎麼具體串起來的。
1、資料歸一化
模型真正讀進去的資料是剛才說的歸一化之後的資料,也就是需要把標註的座標和得到的物體的長和寬除以原始圖片的長和寬。具體程式碼
注意:嚴格意義上講,這裡所標註的資料,並不是真正意義上的訓練資料,因為後面ssd自己有一套方法來根據default box來產生訓練資料。
2、訓練資料生成
按照前面的說法,ssd-300共有8732個預測框,但是前期訓練的時候,並不是每一張圖片輸進去,就基於所有的預測框給一個損失函式,然後反向傳播。而是在8732個預測框中有針對性的選擇一部分來作為訓練資料,包括正例(含有物體的框)和反例(背景框),反例(背景框)的選取還是有講究的,畢竟大部分框都是背景框,如果都拿來訓練,那麼會造成嚴重的類別不平衡。
我想上面的解釋還是不錯的,裡面的IOU稱為交併比,其實就是兩個框的交集的面積除以它們並集的面積,也稱為jaccard overlap 或者 jaccard 距離,以此來度量兩個框的相似度:

反例的產生—Hard example miner

注:背景框的定位損失預設為[0,0,0,0] 相關程式碼
config檔案中的hard_example_miner引數設定:
hard_example_miner {
num_hard_examples: 3000
iou_threshold: 0.99
loss_type: CLASSIFICATION
max_negatives_per_positive: 3
min_negatives_per_image:0
}1)0.99 相當於不進行NMS,只是單純的按損失排序。所以,這個引數儘量不要動,否則就違背了SSD模型的原意。
2)loss_type 是選擇排序所用的損失的型別:classification, localization, both,三種。相關程式碼連結在這裡。
3、損失函式
損失函式分為兩部分:定位損失和分類損失,對於反例預測框,其定位損失是零。

(六)mobileNet v1
原文在此,核心的想法是經典的卷積操作轉化為 深度可分離卷積
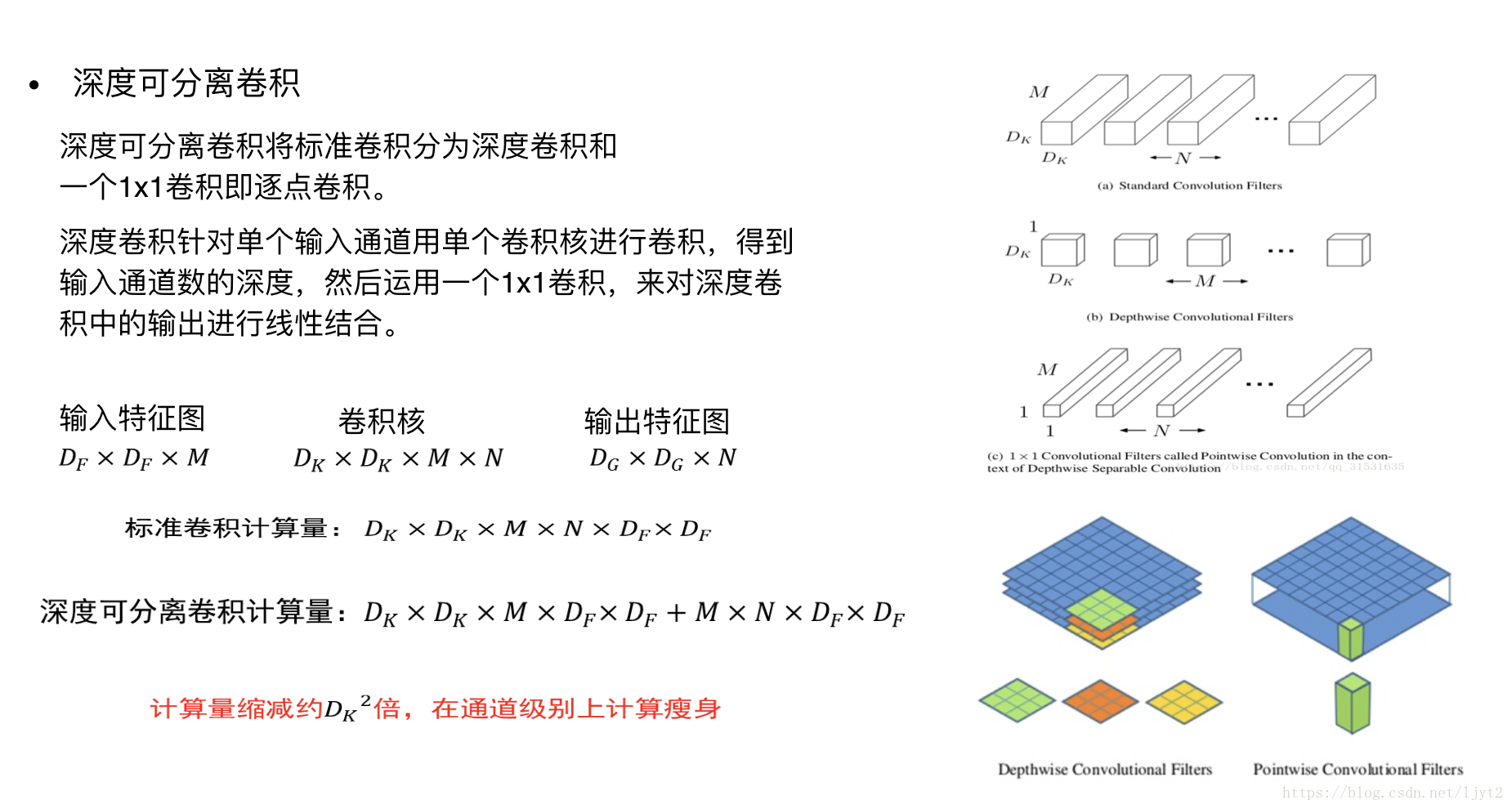
mobilenet v1 網路架構:
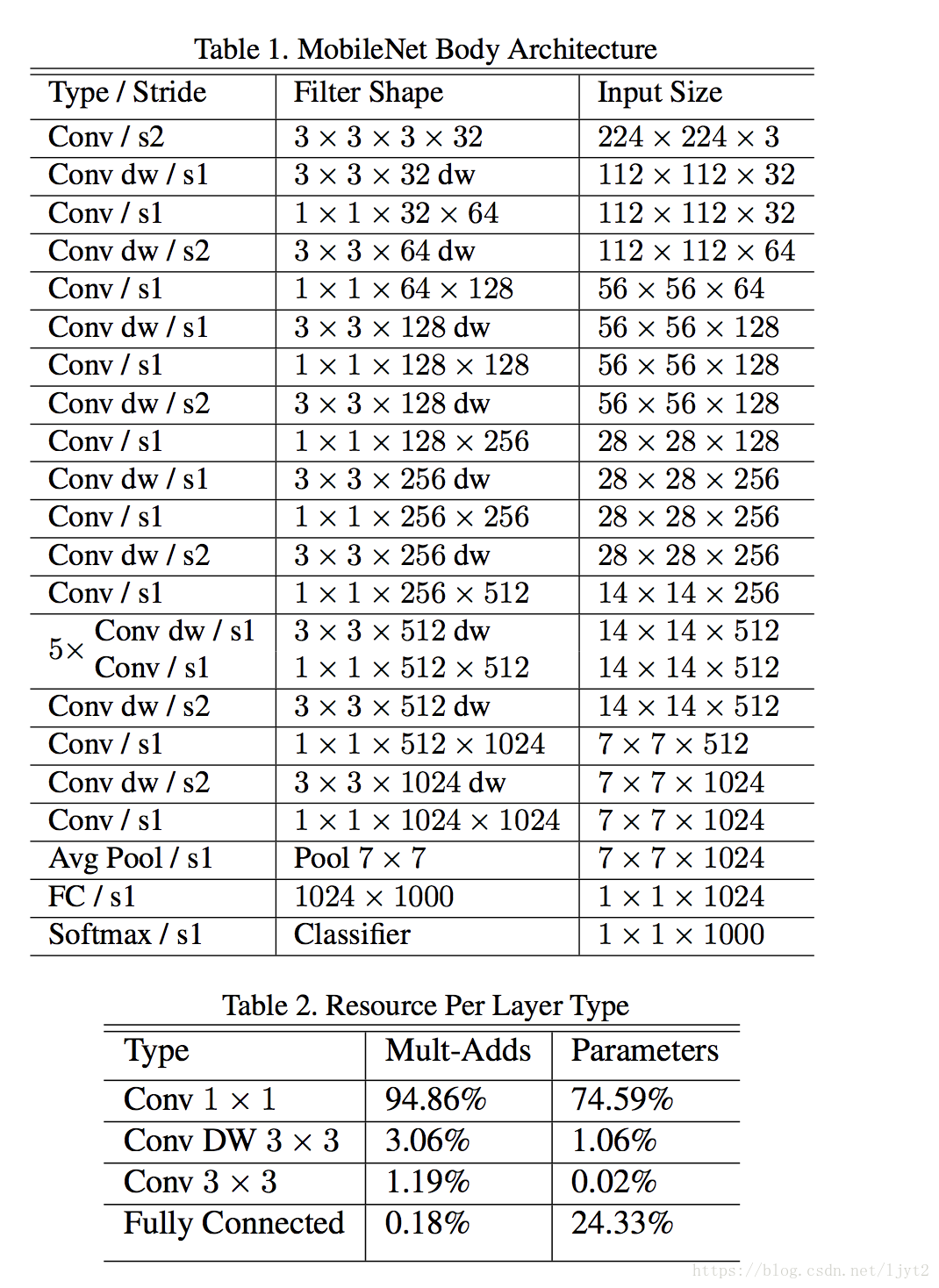
用此網路來替換前面ssd網路架構中的VGG16,所得到的模型即為ssd-mobilenet v1. 最終從此網路中選取兩個特徵圖,及後續再產生4個特徵圖,總共6個特徵圖來作為ssd用來進行檢測的特徵圖相關程式碼。