
HashMap Java 8 重點內容詳解
從原理和細節上搞定HashMap
宣告:網上講HashMap的帖子很多,各自有各自著重介紹的地方,個人把自己比較感興趣的內容和自己的一點點認識寫下了。
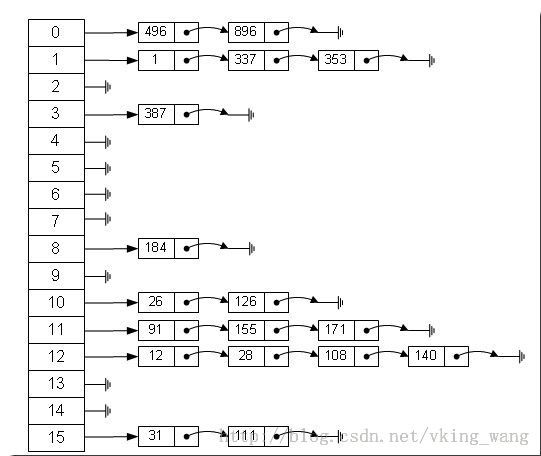
hashmap是由陣列和連結串列組成的,要插入的元素首先根據雜湊函式得到hash值,然後根據規則(取模),得到自己要插入的桶(所謂的桶就是圖中的0-15的陣列元素)的號。然後排在桶中元素的後面。而要取的時候也一樣,先拿到桶號,在沿著這個指標逐個往下找。比如上述雜湊表中,我們現在假設一個要插入的元素經過Hash函式後的值是44,44%16=12;所以這個元素要插入到桶號為12的桶中,接下來它一直往下找,最後排在了140後面。
話不多說,基本的原理我想大多數人應該也知道。不清楚的可以去有些部落格上看看,應該很快就明白。
然後我們來看看JAVA1.8中關於Hashmap的原始碼:
這裡有些不太常用的欄位和函式就不一一列舉了。
HashMap主要屬性:
public class HashMap<k,v> extends AbstractMap<k,v> implements Map<k,v>, Cloneable, Serializable { private static final long serialVersionUID = 362498820763181265L; static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // 預設桶的數量 static final int MAXIMUM_CAPACITY = 1 << 30;//最大容量 static final float DEFAULT_LOAD_FACTOR = 0.75f;//填充比 //當add一個元素到某個位桶,其連結串列長度達到8時將連結串列轉換為紅黑樹 static final int TREEIFY_THRESHOLD = 8; static final int UNTREEIFY_THRESHOLD = 6; static final int MIN_TREEIFY_CAPACITY = 64; transient Node<k,v>[] table;//儲存元素的陣列 transient Set<map.entry<k,v>> entrySet; transient int size;//存放元素的個數 transient int modCount;//被修改的次數fast-fail機制 int threshold;//臨界值 當實際大小(容量*填充比)超過臨界值時,會進行擴容 final float loadFactor;//填充比
而其中的負載因子loadFactor的理解為:HashMap中的資料量/HashMap的總容量(initialCapacity),當loadFactor達到指定值或者0.75時候,HashMap的總容量自動擴充套件一倍。
其中最常用的兩個函式實現大致如下:
// 儲存時:
int hash = key.hashCode();
int index = hash % Entry[].length;
Entry[index] = value;
// 取值時:
int hash = key.hashCode(); int index = hash % Entry[].length; return Entry[index];
接下來我覺得hash函式這點很重要。
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
這裡hashCode()通過物件得到一個int的編碼,不同的物件的函式不一樣,如String的hashCode()
就是將String轉化成char陣列,然後把這個陣列看做是一個32進位制的數。
public int hashCode() {
int h = hash;
if (h == 0 && value.length > 0) {
char val[] = value;
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
}
hash = h;
}
return h;
}
至於之後的h = key.hashCode()) ^ (h >>> 16)
開始有些不懂,後面去知乎上看了看。
這段程式碼,Java 7是這麼寫的
static int hash(int h) {
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
Java 8只做一次16位右位移異或混合,而不是四次,但原理是不變的。兩段程式碼的目的都是想讓雜湊函式對映得比較均勻鬆散。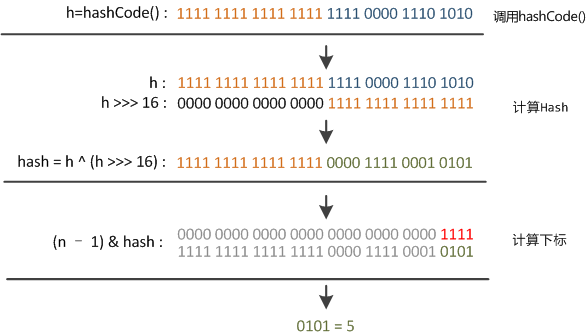
右唯一16位,正好32位的一半,自己的高半區和低半區做異或,就是為了混合原始雜湊碼的高位和低位,以此來加大低位的隨機性。而且混合後的低位摻雜了高位的部分特徵,這樣高位的資訊也被變相的保留下來。
後面還有個人認為比較重要的內容就是resize(),以及Java 8中的紅黑樹。
內容會在後面補充。
treefiybin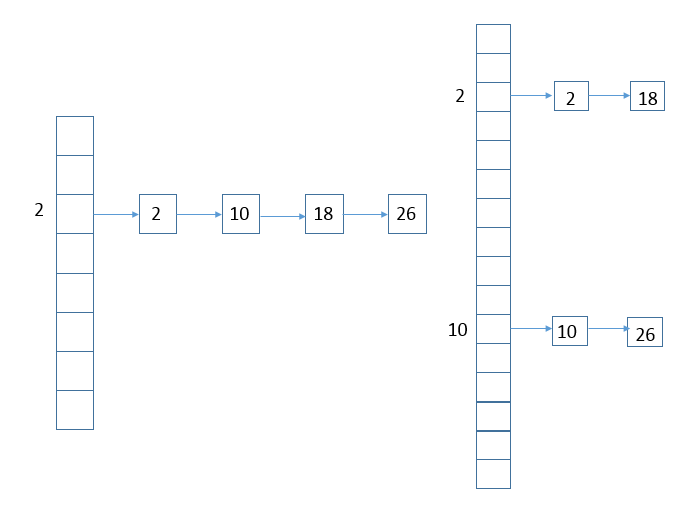
紅黑樹替代普通的連結串列
最後來看看java8 很大的一個改進resize 擴容
舉個例子
上邊圖中第0個下標有496和896, 假設它倆的hashcode(int型,佔4個位元組)是
resize前:
496的hashcode: 00000000 00000000 00000000 00000000
896的hashcode: 01010000 01100000 10000000 00100000
oldCap是16: 00000000 00000000 00000000 00010000
496和896對應的e.hash & (oldCap)的值為0, 即下標都是第0個。
resize後:
496的hashcode: 00000000 00000000 00000000 00*0*00000
896的hashcode: 01010000 01100000 10000000 00*1*00000
oldCap是32: 00000000 00000000 00000000 00**1**00000
程式碼中 if ((e.hash & oldCap) == 0)
496和896對應的e.hash & oldCap的值為0和1, 即下標是第0個和第16個。
它將原來的連結串列資料雜湊到2個下標位置, 概率分別是0.5。
因為hashcode的第n位是0/1的概率相同, 理論上鍊表的資料會均勻分佈到當前下標或高位陣列對應下標。
回顧JDK1.7的HashMap,在擴容時會rehash即每個entry的位置都要再計算一遍, 效能不好, 所以JDK1.8做了這個優化。
再回到文章最開始的問題, HashMap為什麼用&得到下標,而不是%? 如果使用了取模%, 那麼在容量變為2倍時, 需要rehash確定每個連結串列元素的位置。
本文好多地方都是在各位大神的部落格上摘抄和學習到的,只是自己整理歸納方便以後複習。
具體的引用就不寫了,忘各位博主見諒!