
整合學習法之bagging方法和boosting方法
一、整合學習法(Ensemble Learning)
首先,讓我們先來了解一下,什麼是整合學習法。
① 將多個分類方法聚集在一起,以提高分類的準確率。
(這些演算法可以是不同的演算法,也可以是相同的演算法。)
② 整合學習法由訓練資料構建一組基分類器,然後通過對每個基分類器的預測進行投票來進行分類
③ 嚴格來說,整合學習並不算是一種分類器,而是一種分類器結合的方法。
④ 通常一個整合分類器的分類效能會好於單個分類器
⑤ 如果把單個分類器比作一個決策者的話,整合學習的方法就相當於多個決策者共同進行一項決策。

(整合學習法圖解)
要掌握整合學習法,我們會提出以下兩個問題:
1)怎麼訓練每個演算法?
2)怎麼融合每個演算法?
因此,bagging方法和boosting方法應運而生
二、bagging(裝袋)方法
① Bagging又叫自助聚集,是一種根據均勻概率分佈從資料中重複抽樣(有放回)的技術。
② 每個抽樣生成的自助樣本集上,訓練一個基分類器;對訓練過的分類器進行投票,將測試樣本指派到得票最高的類中。
③ 每個自助樣本集都和原資料一樣大
④ 有放回抽樣,一些樣本可能在同一訓練集中出現多次,一些可能被忽略。
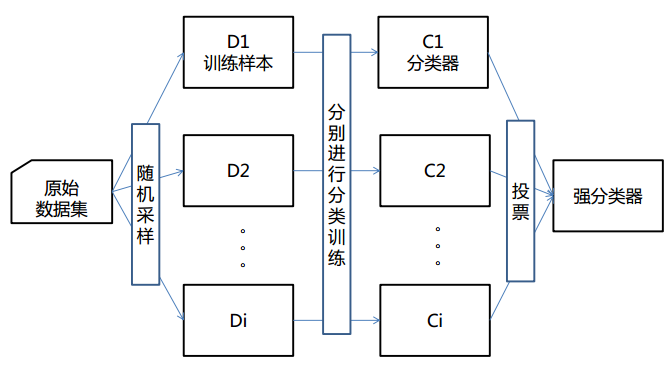
(bagging方法圖解)
為了讓大家更好地理解bagging方法,這裡提供一個例子。
X 表示一維屬性,Y 表示類標號(1或-1)測試條件:當x<=k時,y=?;當x>k時,y=?;k為最佳分裂點
下表為屬性x對應的唯一正確的y類別
現在進行5輪隨機抽樣,結果如下

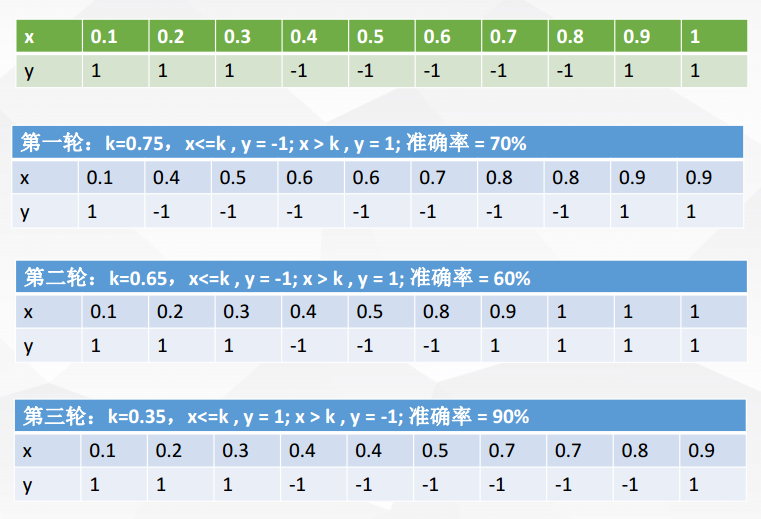
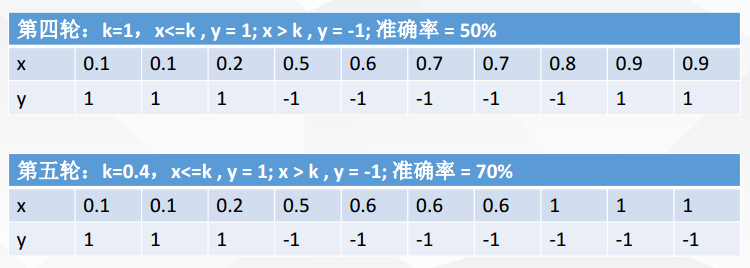
每一輪隨機抽樣後,都生成一個分類器
然後再將五輪分類融合
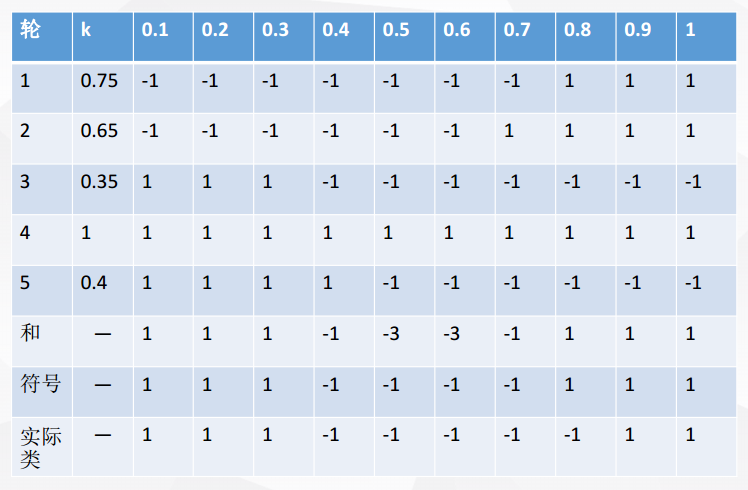
對比符號和實際類,我們可以發現:在該例子中,Bagging使得準確率可達90%
由此,總結一下bagging方法:
① Bagging通過降低基分類器的方差,改善了泛化誤差
② 其效能依賴於基分類器的穩定性;如果基分類器不穩定,bagging有助於降低訓練資料的隨機波動導致的誤差;如果穩定,則整合分類器的誤差主要由基分類器的偏倚引起
③ 由於每個樣本被選中的概率相同,因此bagging並不側重於訓練資料集中的任何特定例項
三、boosting(提升)方法
① boosting是一個迭代的過程,用於自適應地改變訓練樣本的分佈,使得基分類器聚焦在那些很難分的樣本上
② boosting會給每個訓練樣本賦予一個權值,而且可以再每輪提升過程結束時自動地調整權值。開始時,所有的樣本都賦予相同的權值1/N,從而使得它們被選作訓練的可能性都一樣。根據訓練樣本的抽樣分佈來抽取樣本,得到新的樣本集。然後,由該訓練集歸納一個分類器,並用它對原資料集中的所有樣本進行分類。每輪提升結束時,更新訓練集樣本的權值。增加被錯誤分類的樣本的權值,減小被正確分類的樣本的權值,這使得分類器在隨後的迭代中關注那些很難分類的樣本。
四、由此我們可以對比Bagging和Boosting
① bagging的訓練集是隨機的,各訓練集是獨立的;而boosting訓練集的選擇不是獨立的,每一次選擇的訓練集都依賴於上一次學習的結果
② bagging的每個預測函式都沒有權重;而boosting根據每一次訓練的訓練誤差得到該次預測函式的權重
③ bagging的各個預測函式可以並行生成;而boosting只能順序生成。(對於神經網路這樣極為耗時的學習方法,bagging可通過並行訓練節省大量時間開銷)
然而,Bagging和Boosting都可以視為比較傳統的整合學習思路。 現在常用的Random Forest,GBDT(迭代決策樹),GBRank其實都是更加精細化,效果更好的方法。