深度學習---mobilenet網路的理解
有tensorflow的實現: https://github.com/tensorflow/models/blob/master/slim/nets/mobilenet_v1.md
caffe也有人實現: https://github.com/shicai/MobileNet-Caffe,
前言
這篇論文是Google針對手機等嵌入式裝置提出的一種輕量級的深層神經網路,取名為MobileNets。個人感覺論文所做工作偏向於模型壓縮方面,核心思想就是卷積核的巧妙分解,可以有效減少網路引數。可能由於剛釋出,谷歌還沒有放出官方程式碼(Tensorflow),谷歌官方已經開源了這部分程式碼(2017.6.15),具體參見文中地址。另外,在Github上搜索“MolileNets”,可發現一些個人實現的程式碼,部分會提供訓練好的模型。博主跑過其中的caffe模型,發現inference速度並沒有怎麼提升,看網上討論,應該是caffe框架的問題,要想大幅提升速度,應該只能依賴Tensorflow框架了。
摘要
我們提供一類稱為MobileNets的高效模型,用於移動和嵌入式視覺應用。 MobileNets是基於一個流線型的架構,它使用深度可分離的卷積來構建輕量級的深層神經網路。我們引入兩個簡單的全域性超引數,在延遲度和準確度之間有效地進行平衡。這兩個超引數允許模型構建者根據問題的約束條件,為其應用選擇合適大小的模型。我們進行了資源和精度權衡的廣泛實驗,與ImageNet分類上的其他流行的網路模型相比,MobileNets表現出很強的效能。最後,我們展示了MobileNets在廣泛的應用場景中的有效性,包括物體檢測,細粒度分類,人臉屬性和大規模地理定位。
引言和背景介紹
這部分是說,隨著深度學習的發展,卷積神經網路變得越來越普遍。當前發展的總體趨勢是,通過更深和更復雜的網路來得到更高的精度,但是這種網路往往在模型大小和執行速度上沒多大優勢。一些嵌入式平臺上的應用比如機器人和自動駕駛,它們的硬體資源有限,就十分需要一種輕量級、低延遲(同時精度尚可接受)的網路模型,這就是本文的主要工作。
在建立小型和有效的神經網路上,已經有了一些工作,比如SqueezeNet,Google Inception,Flattened network等等。大概分為壓縮預訓練模型和直接訓練小型網路兩種。MobileNets主要關注優化延遲,同時兼顧模型大小,不像有些模型雖然引數少,但是也慢的可以。
MobileNets模型結構
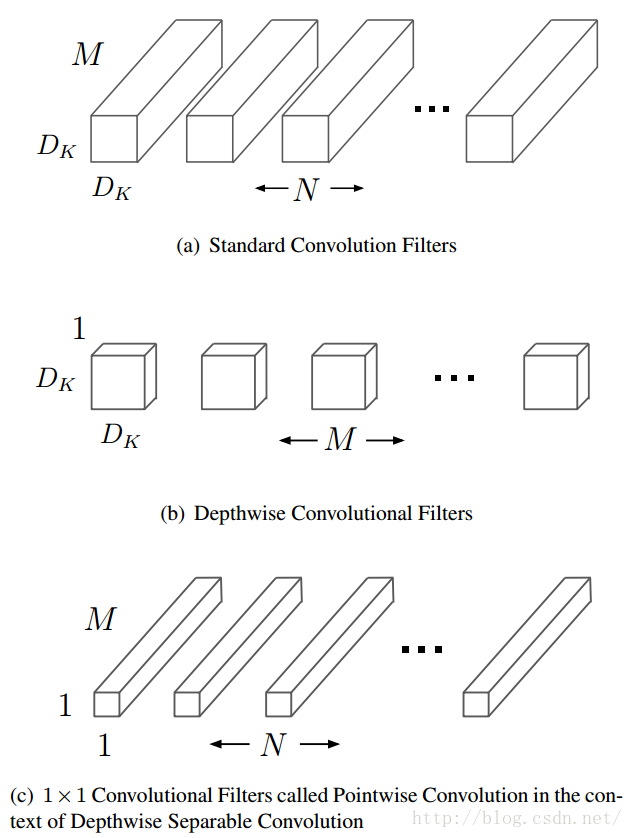
深度可分解卷積
MobileNets模型基於深度可分解的卷積,它可以將標準卷積分解成一個深度卷積和一個點卷積(1 × 1卷積核)。深度卷積將每個卷積核應用到每一個通道,而1 × 1卷積用來組合通道卷積的輸出。後文證明,這種分解可以有效減少計算量,降低模型大小。圖2說明了標準卷積是如何進行分解的。
直觀上來看,這種分解在效果上確實是等價的。比如,把上圖的代號化為實際的數字,輸入圖片維度是11 × 11 × 3,標準卷積為3 × 3 × 3 ×16(假設stride為2,padding為1),那麼可以得到輸出為6 × 6 × 16的輸出結果。現在輸入圖片不變,先通過一個維度是3 × 3 × 1 × 3的深度卷積(輸入是3通道,這裡有3個卷積核,對應著進行計算,理解成for迴圈),得到6 × 6 × 3的中間輸出,然後再通過一個維度是1 × 1 × 3 ×16的1 ×1卷積,同樣得到輸出為6 × 6 × 16。以上解析還可以藉助一幅經典的GIF圖來理解,先放這裡了。
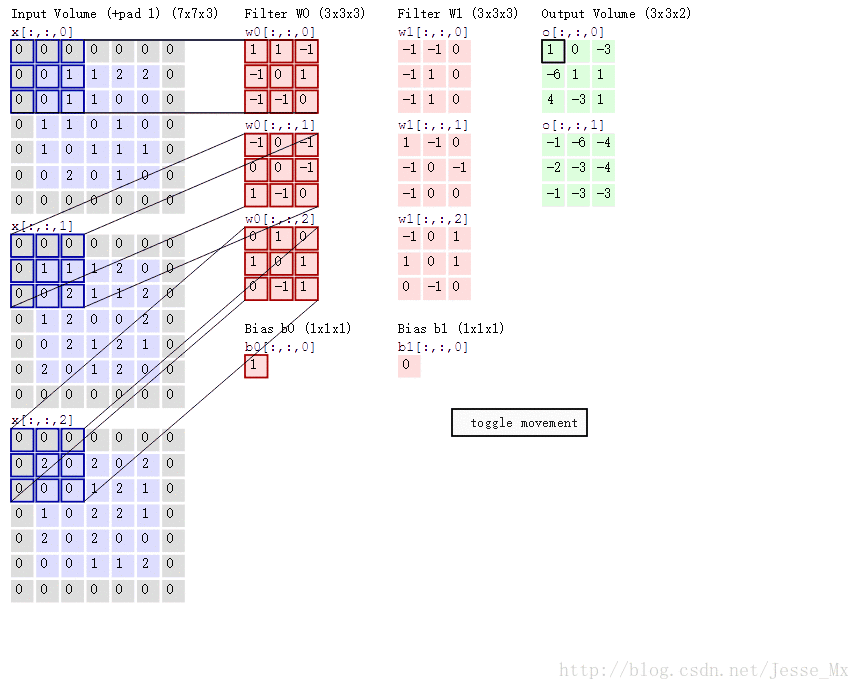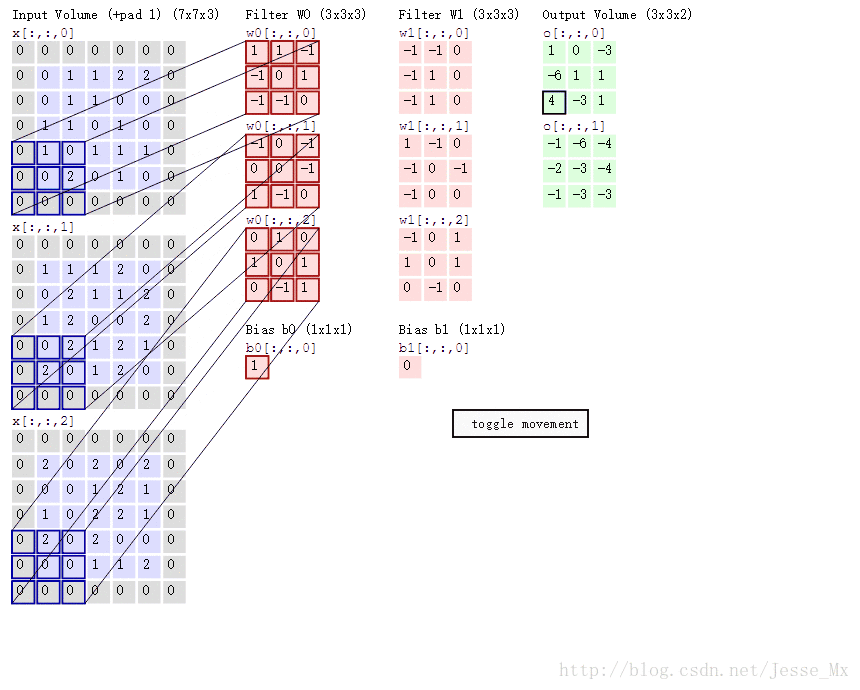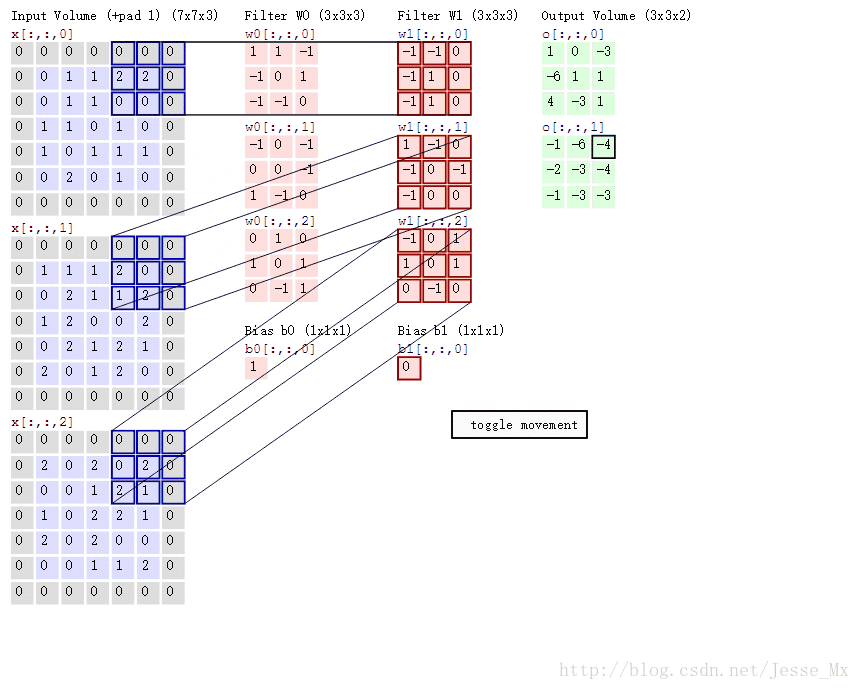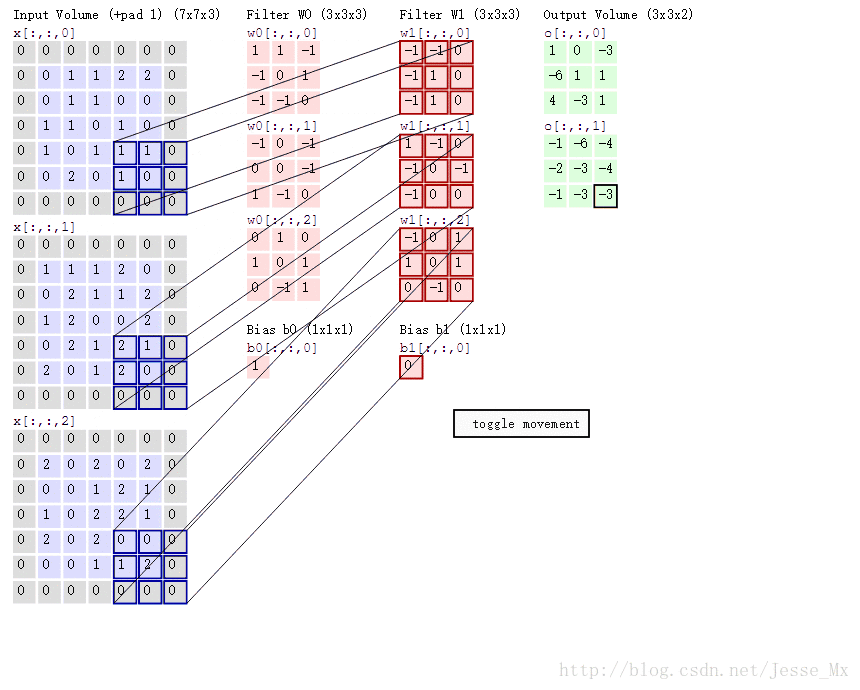
接下來作者計算了這種分解可以多大程度上減少引數量。這裡首先指出論文中存在的一處筆誤,下圖標註部分寫錯了,正確應為 。

首先是標準卷積,假定輸入F的維度是 ,經過標準卷積核K得到輸出G的維度 ,卷積核引數量表示為 。如果計算代價也用數量表示,應該為 。
現在將卷積核進行分解,那麼按照上述計算公式,可得深度卷積的計算代價為 ,點卷積的計算代價為 。
將二者進行比較,可得:
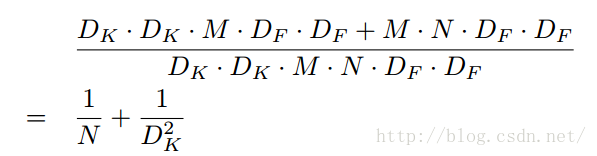
MobileNets使用了大量的3 × 3的卷積核,極大地減少了計算量(1/8到1/9之間),同時準確率下降的很少,相比其他的方法確有優勢。
模型結構和訓練
MobileNets結構建立在上述深度可分解卷積中(只有第一層是標準卷積)。該網路允許我們探索網路拓撲,找到一個適合的良好網路。其具體架構在表1說明。除了最後的全連線層,所有層後面跟了batchnorm和ReLU,最終輸入到softmax進行分類。圖3對比了標準卷積和分解卷積的結構,二者都附帶了BN和ReLU層。按照作者的計算方法,MobileNets總共28層(1 + 2 × 13 + 1 = 28)。
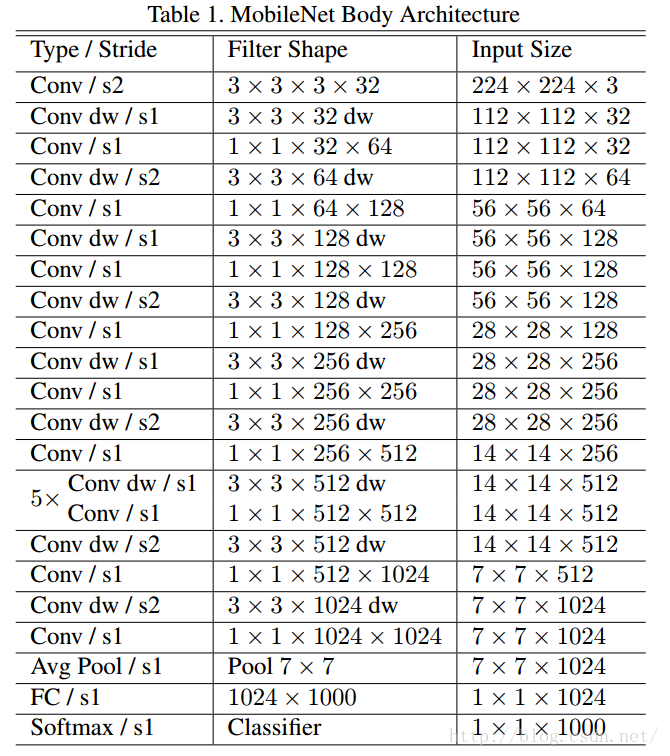

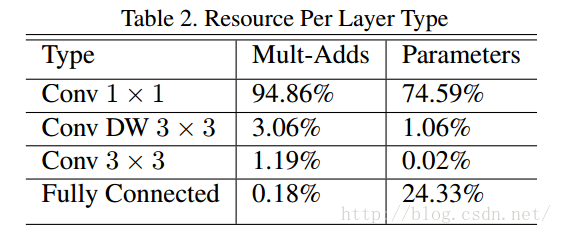
MobileNet將95%的計算時間用於有75%的引數的1×1卷積,作者採用tensorflow框架進行訓練,因為過擬合不太容易,所以資料增強和規則化用的不多。
寬度乘數
這裡介紹模型的第一個超引數,即寬度乘數 。為了構建更小和更少計算量的網路,作者引入了寬度乘數 ,作用是改變輸入輸出通道數,減少特徵圖數量,讓網路變瘦。在 引數作用下,MobileNets某一層的計算量為:
其中, 取值是0~1,應用寬度乘數可以進一步減少計算量,大約有 的優化空間。
解析度乘數
第二個超引數是解析度乘數 ,解析度乘數用來改變輸入資料層的解析度,同樣也能減少引數。在 和 共同作用下,MobileNets某一層的計算量為:
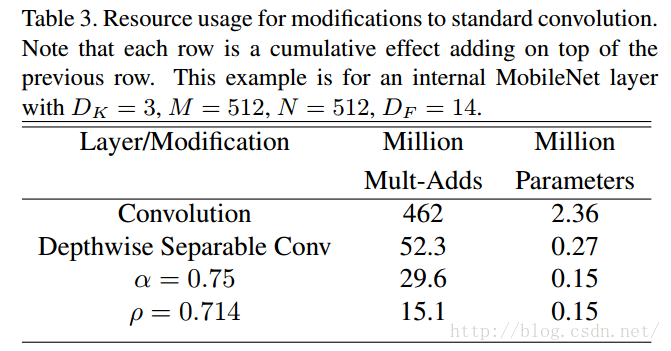
其中, 是隱式引數, 如果為{1,6/7,5/7,4/7},則對應輸入解析度為{224,192,160,128}, 引數的優化空間同樣是 左右。 表3可以看出兩個超引數在減少網路引數的上的作用。
實驗分析
模型選擇
表4中,同樣是MobileNets的架構,使用可分離卷積,精度值下降1%,而引數僅為1/7。

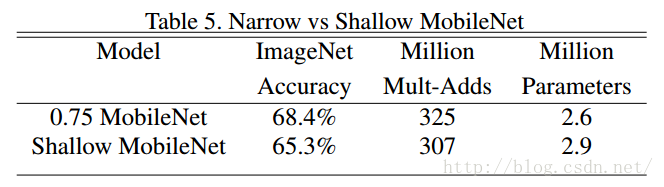
表5中,深且瘦的網路比淺且胖的網路準確率高3%。
模型收縮超引數
表6中, 超引數減小的時候,模型準確率隨著模型的變瘦而下降。
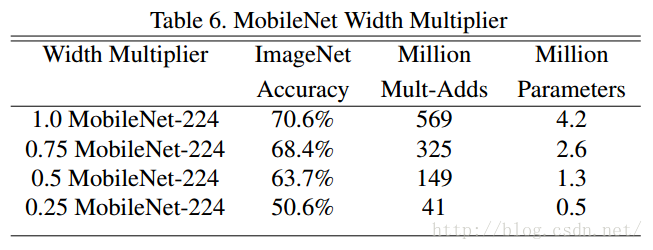
表7中, 超引數減小的時候,模型準確率隨著模型的解析度下降而下降。
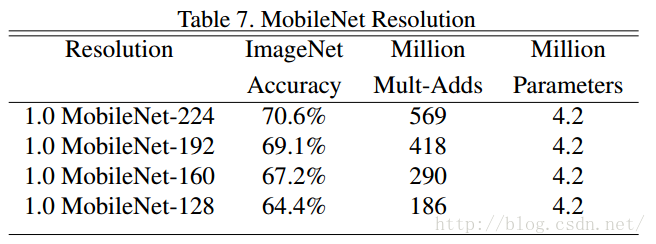
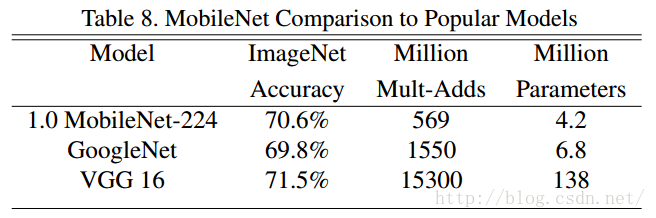
表8中,在ImageNet資料集上,將MobileNets和VGG與GoogleNet做了對比。
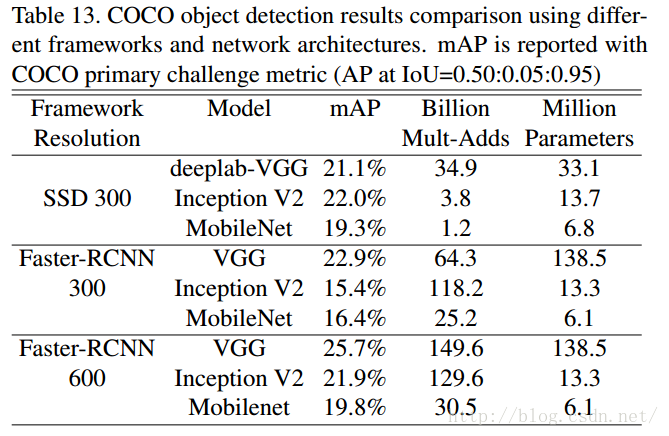
目標檢測
這裡的實驗主要是將MobileNets作為目標檢測網路Faster R-CNN和SSD的基底(base network),和其他模型在COCO資料集上進行了對比。(為什麼不在VOC PASCAL上進行對比,應該更直觀吧?也不給一個幀率,不知道速度怎麼樣)