
用python寫一個搶票小程式(無驗證碼)
準備工作:
利用到的庫: requests、time、re、threading、wx
利用chrome抓包模擬校園網登入的python指令碼:
開啟瀏覽器的開發者工具,在network中找到 所有場館頁面資訊的url 和 傳送訂票請求的url。
我在這次用到的有:url、requests_headers、form_data和cookies
1.1 在python中學習用requests建立會話並且傳送http請求(僅用到get和post):
在整個檢視和搶票過程中全程需要用到cookies引數,但是又不想重複輸入,於是建立一個會話讓我減少這些重複操作。
import requests cookie1 = cookie #這裡的cookie是從瀏覽器中複製出來的,以字典的形式儲存 s = requests.session() #建立會話 cookie1 = requests.utils.cookiejar_from_dict(cookie1, cookiejar=None, overwrite=True) #將字典形式轉換成cookiejar形式 s.cookies = cookie1 #將cookies資訊放入會話中
場館資訊的頁面我放在url_all中,獲取html需要在帶上cookie的資訊的情況下用get方法傳送請求,結果我用print輸出。
get = s.get(url_all)
print(get.text)在上述得到的html中如果得到最終傳送訂票資訊的url(假設為url_ticket),接下來用post傳送相應表單進行訂票,可以用status_code來檢視狀態碼。
post = s.post(url_ticket,data = form_data)
print(post.status_code)1.2 在python中學習用re寫正則表示式:
因為在門票刷出來之前沒辦法知道其id(各類體育場館之間的id無序排列),所以當得到返回的html的時候需要用正則表示式去找到符合要求的場館(需要找到特定時間的特定場館),並且獲得其id(這裡獲得的id用於後面傳送訂票表單的url中)
來一個簡單的re的使用方法:
import re
r = re.compile('sub="(www.*com)"')
result = r.findall('abcd_sub="www.baidu.com"') 上述程式碼會在findall()裡面新增的字串裡面尋找conpile()裡面寫的字元段(假設為A),並且將匹配到的括號內的結果賦給result。當然逐個匹配的功能在這裡是不夠用的,因此要藉助在字元段A中輸入一些特殊字元來進行模糊查詢:
一些正則表示式中特殊字元的補充:(參考https://www.cnblogs.com/xieshengsen/p/6727064.html)
其中上面程式碼中用到的特殊字元是:“.*?”和“()”。前者匹配所有的字元;後者出現在正則表示式中的時候,該表示式返回的是括號中間匹配到的字元。
1.3 建立圖形使用者介面(用wxPython)
用這個庫可以讓小程式用起來更方便。
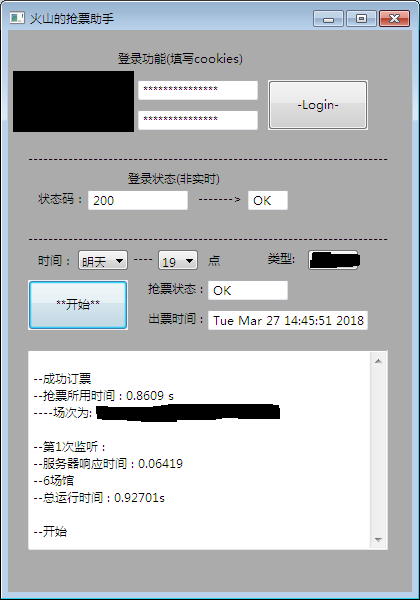
2.一些錯誤:
2.1 指令碼中設定每隔0.5秒鐘就向場館資訊頁面傳送一個get請求檢視是否有場館門票放出,但是跑了差不多100次就報錯了,報錯資訊如下:
“requests.exceptions.ConnectionError: ('Connection aborted.', ConnectionAbortedError(10053, '您的主機中的軟體中止了一個已建立的連線。', None, 10053, None))”
把這個錯誤資訊輸到搜尋引擎上面去,各路大神對這種報錯的解決方法都不一樣,但是沒一個符合我這種情況的。最後做了一個小小的實驗:一樣的程式,只是把學校的網址改成了'http://www.baidu.com',然後依然是0.5s傳送一次。讓它跑到200次也沒報錯。於是推斷跟本機沒關係,可能是伺服器那邊因為訪問頻率過高所以斷開了連線,也就不深究了(唉還是太菜了)
2.2 在“監聽”過程中,一開始由於其中一個觸發事件進入了死迴圈,所以整個圖形介面都卡住了,本來應該在圖形介面介面顯示的狀態資訊也都沒有顯示,後來把那個有迴圈的觸發事件寫進一個執行緒裡面去才解決這個問題。