
JVM效能監控和調優
1. JVM效能監控
1、定位系統問題
- 依據
- GC日誌
- 堆轉儲快照(heapdump/hprof檔案)
- 執行緒快照(threaddump/javacore檔案)
- 執行日誌
- 異常堆疊
- 分析依據的工具
- jps:顯示指定系統內的所有JVM程序
- jstat:收集JVM各方面的執行資料
- jinfo:顯示JVM配置資訊
- jmap:形成堆轉儲快照(heapdump檔案)
- jhat:分析heapdump檔案
- jstack:顯示JVM的執行緒快照
- jconsole
- visualVM
說明:後邊兩種是具有圖形化介面的。
2、jps(是其他所有命令的基礎)
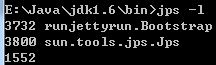
作用:列出所有的JVM虛擬機器程序。
格式:jps -l
3、jstat(是沒有GUI介面的情況下,在執行期定位JVM效能問題的首選)
作用:檢視gc資料和類載入解除安裝資料
格式:jstat option PID interval count
意義:每隔interval毫秒做一次option,一共做count次

說明:S0(from區)使用了41.74%;S1(to區)使用了0;E(Eden區)使用了54.35%;O(Old,年老代)使用了62.41%;P(Perment,永久代)使用了99.63%;YGC(Young GC)了32次,YGCT(Young GC Time)花銷0.132秒;FGC(Full GC)了1次,FGCT(Full GC Time)花銷0.102秒;GCT(GC Time)總花銷0.234秒。
分析:其實上邊這個查詢結果可以直接看出,我們需要加大P(永久代大小)

說明:載入了3683個類,總共佔有4355.3位元組;解除安裝了0個類,解除安裝的類的位元組數為0,類的載入與解除安裝共花銷3.16秒
4、jinfo
作用:檢視和執行期修改JVM的配置引數
格式:jinfo -flag parameter PID

說明:檢視3732程序下的MaxTenuringThreshold引數值。

說明:修改3732程序下的MaxTenuringThreshold引數值,但是windows下失敗。
5、jmap
作用:生成堆轉儲快照和檢視最佔記憶體的元素,用於分析記憶體洩露問題
格式(生成堆轉儲快照):jmap -dump:format=b,file=檔名 PID

說明:生成了3732程序的堆轉儲檔案myfile
格式(檢視最佔記憶體的元素):jmap -histo PID

說明:結果自己去看,太多了
6、jhat
作用:分析堆轉儲快照(與jmap配合)
格式:jhat 檔名
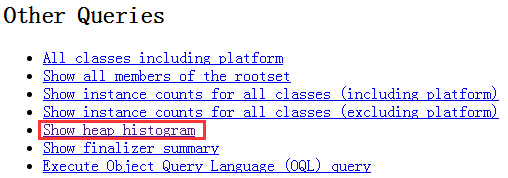
說明:執行上述命令後,開啟localhost:7000,找到如下紅框部分開啟,這裡才是我們最關注的東西。
注意:該工具是萬不得已才用的。
推出命令使用"ctrl+c"
7、jstack
作用:生成執行緒快照,定位執行緒長時間卡頓的原因(執行緒間死鎖、死迴圈、請求外部資源導致的長時間等待)
格式:jstack -l PID

說明:檢視3732程序中的所有執行緒的堆疊資訊
《深入理解Java虛擬機器》的作者提供了一個工具jsp頁面,使得我們可以在程式執行時,隨時執行該jsp頁面,來檢視執行緒堆疊資訊,程式碼如下:


1 <%@ page language="java" contentType="text/html; charset=UTF-8" 2 pageEncoding="UTF-8" import="java.util.Map"%> 3 <!DOCTYPE html> 4 <html> 5 <head> 6 <meta http-equiv="Content-Type" content="text/html; charset=UTF-8"> 7 <title>jstack</title> 8 </head> 9 <body> 10 <% 11 for(Map.Entry<Thread, StackTraceElement[]> stackTrace : Thread.getAllStackTraces().entrySet()){ 12 Thread thread = (Thread)stackTrace.getKey(); 13 StackTraceElement[] elements = (StackTraceElement[])stackTrace.getValue(); 14 15 /* if(thread.equals(Thread.currentThread())){ 16 continue; 17 } */ 18 out.println("\n執行緒:"+thread.getName()+"\n"); 19 for(StackTraceElement ele : elements){ 20 out.println("\t"+ele+"\n"); 21 } 22 } 23 %> 24 </body> 25 </html>
注意:程式碼中我註釋掉一段,是因為想也查出當前執行緒的堆疊資訊,作者並沒有這個註釋。
總結:
- JVM效能相關的6個常用的JDK命令
- jps:查詢JVM中的所有程序,找出將要操作的PID,是所有命令的基礎
- jstat:檢視相應JVM程序的gc、類載入解除安裝資訊,是沒有GUI介面檢視JVM執行資料的首選
- jinfo:檢視和在執行期動態修改JVM配置引數
- jmap:生成堆轉儲快照和比較佔記憶體的物件
- jhat:配合jmap分析堆轉儲日誌,除非沒有其他工具可做這個事兒,否則就不用該工具
- jstack:生成執行緒快照,定位執行緒長時間卡頓的原因(執行緒間死鎖、死迴圈、請求外部資源導致的長時間等待)
- 輸出gc資訊到控制檯
- -XX:+PrintGCDetails:輸出GC的詳細資訊
- -XX:+PrintGCTimeStamps:輸出GC的時間資訊
- -XX:+PrintGCApplicatonStoppedTime:GC造成的應用暫停的時間
- -XX:+PrintGCDetails:輸出GC的詳細資訊
- 輸出gc資訊到檔案
- 以上三個引數在這裡依舊適用
- -Xloggc:檔案路徑/gc.log:輸出到檔案
圖形化的JVM效能監控
1、影象化的故障處理工具
- Jconsole
- visualVM
2、Jconsole
進入"E:\Java\jdk1.6\bin",雙擊"jconsole.exe",彈出如下框:
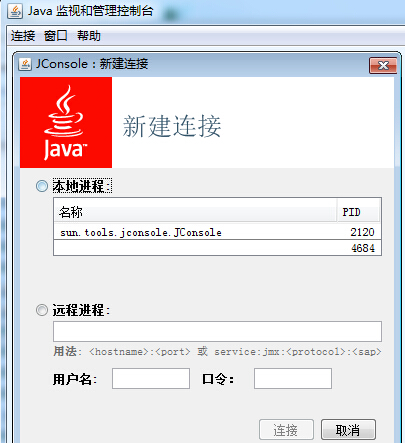
說明:這裡列出了所有的JVM程序,一個Jconsole程序,一個eclipse(PID:4684),這相當於jps命令。
選中其中一個PID,假設選中了eclipse,雙擊,出現下圖:(注:之後的各個葉籤,都是每4秒重新整理一次)
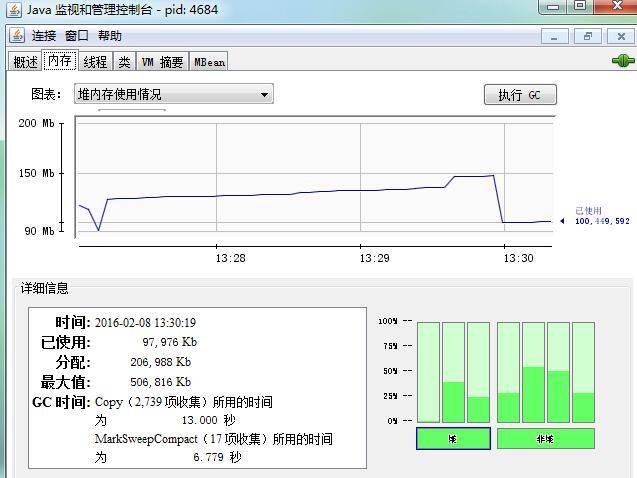
"記憶體":相當於jstat -gc,在上圖中的詳細資訊部分,該部分對應的資訊就是頭部圖表部分所寫的引數(這裡是"整個堆"的情況),同時對應的也是右下角部分柱狀圖所選中的柱子(這裡是"堆"),對於"非堆"指的就是"方法區"(或者稱為"永久代")。當然,這裡也可以選擇時間範圍來檢視相應的資訊。
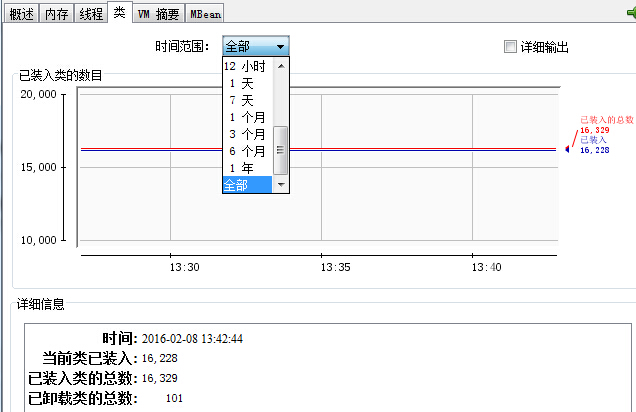
"類":相當於jstat -class,列出了裝載類和解除安裝類的相關資訊。
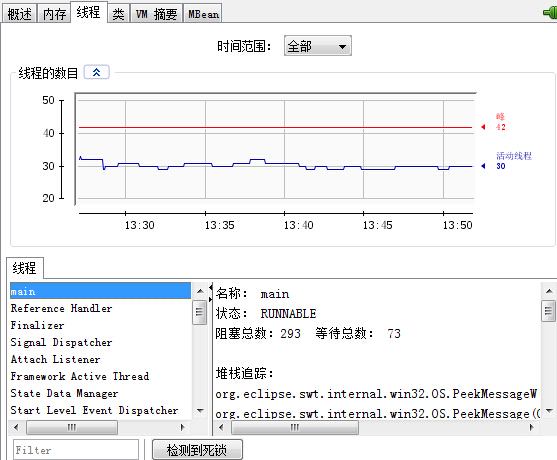
"執行緒":相當於jstack,折線圖顯示了執行緒數目的變化情況,包括峰值執行緒數量、活動執行緒數量;左下角展示了所有執行緒名稱。雙擊相應的執行緒名稱
"VM摘要":相當於jinfo

最後,測試一下執行緒死鎖的現象。程式碼如下:
 View
Code
View
Code
執行main()方法,之後去檢視"執行緒"標籤,點選"檢測死鎖",如下:


發現執行緒Thread-95和Thread-106死鎖(彼此擁有對方想要的鎖)
分析:
1)Integer快取機制
Integer.valueOf(int xxx),該方法為了減少物件的建立,節省記憶體,會將xxx轉化成的Integer物件快取起來,之後只要是相同的xxx,那麼這個方法都會直接從快取中取出物件來。假設程式碼中的Integer.valueOf(1)生成的物件是[email protected],而Integer.valueOf(2)生成的物件是[email protected],那麼之後無論呼叫多少次Integer.valueOf(1),也無論是哪一個執行緒去呼叫該方法,返回的都只是同一個物件[email protected]。也就是說上邊的這段程式碼中的Integer.valueOf(i)只會生成兩個不同的物件,就是[email protected]和[email protected],而這兩個物件也就是我們的鎖物件。
2)死鎖發生的時機
假設執行緒"Thread-95"執行到其第一個synchronized塊中時(假設剛剛獲取了鎖物件[email protected]),這時候CPU時間片切換給了執行緒"Thread-106",而"Thread-106"執行其第一個synchronized塊(獲取了鎖物件[email protected]),之後"Thread-106"要執行第二個synchronized塊兒來獲取鎖物件[email protected],這時候就獲取不到了,因為這個鎖物件正被"Thread-95"所持有,於是"Thread-106"就阻塞在[email protected]這個鎖物件上,這時,假設CPU時間片又切換給了"Thread-95",該執行緒要執行第二個synchronized塊來獲取[email protected],就獲取不到了,因為該鎖物件已被"Thread-106"所持有
3)結果
"Thread-95"持有鎖物件[email protected],阻塞在鎖物件[email protected];
"Thread-106"持有鎖物件[email protected],阻塞在鎖物件[email protected]
3、visualVM
是一塊更加全面的GUI監視工具,包含很多外掛(需要自己下載),具體的見《深入理解Java虛擬機器(第二版)》
JVM調優
1、JVM的調優主要是記憶體的調優,主要調兩個方面:
- 各個代的大小
- 垃圾收集器選擇
2、各個代的大小
- 常用的調節引數
- -Xmx
- -Xms
- -Xmn
- -XX:SurvivorRatio
- -XX:MaxTenuringThreshold
- -XX:PermSize
- -XX:MaxPermSize
- 原則
- -Xmx==-Xms:防止堆記憶體頻繁進行調整,調整的時機見《第一章 JVM記憶體結構》
- -Xmn:通常設為-Xmx/4(這是我在企業中實習時的設定方式,系統執行正常、平穩、速度也快),林昊推薦的是-Xmx/3,所以-Xmn==-Xmx/4~-Xmx/3
- 調節時機:minor GC太頻繁
- -Xmn過小:minor GC太頻繁;小物件可能也會直接進入年老代,提前導致Full GC
- -Xmn過大:年輕代大了,minor GC的時間變長了;年老代變小了,Full GC會頻繁
- 調節策略:若-Xmx可調大,則調大,且保持-Xmn==-Xmx/4~-Xmx/3;若-Xmx不可調大,在保持-Xmn==-Xmx/4~-Xmx/3的範圍內增大-Xmn,若-Xmn也不可調了,則試著調大-XX:SurvivorRatio來看看情況
- -XX:SurvivorRatio:預設8
- -XX:SurvivorRatio過大:Eden變大,Survivor變小,minor GC可能減少,但是由於suvivor減小了,所以如果minor GC存活下來的物件大於suvivor,則會直接進入年老代
- -XX:SurvivorRatio過小:Eden變小,Survivor變大,minor GC可能增多,但是由於suvivor變大了,能夠儲存更多存活下來的物件,進入年老代的物件可能會減少
- -XX:MaxTenuringThreshold:預設為15
- -XX:SurvivorRatio過大:物件在年輕代的存活時間變長,可能在年輕代就被回收掉而不必進入年老代,但是相應的複製的時候survivor區就會被佔用更多的空間。
- -XX:SurvivorRatio過大:物件在年輕代的存活時間變短,可能會早早進入年老代而失去在年輕代被回收的機會,但是相應的複製的時候survivor區也就有更多記憶體了,這樣可能會避免部分大物件直接進入年老代
- -XX:MaxPermSize==-XX:PermSize
- 在實際開發中,前臺不要使用jsp,使用velocity等模板引擎技術
- 不要引入無關的jar
3、垃圾收集器選擇
企業中最常用的兩個組合:(這裡由於大部分大型企業用的還是JDK1.6,所以G1不說)
- Parallel Scavenge/Parallel Old
- 注重吞吐量(吞吐量越大,說明CPU利用率越高)
- 主要用於處理很多的CPU計算任務而使用者互動任務較少的情況
- 也用於讓JVM自動調優而我們袖手旁觀的情況(-XX:+UseParallelOldGC,-XX:GCTimeRatio,-Xmx,-XX:+UseAdaptiveSizePolicy)
- -XX:+UseParallelOldGC:指定使用該組合
- ParNew/CMS
- 注重STW的縮短(該時間越短,使用者體驗越好,而且會減少部分請求的請求超時問題)
- -XX:+UseConcMarkSweepGC:指定使用該組合
- -XX:CMSInitiatingOccupancyFraction:來指定當年老代空間滿了多少後(百分比)進行垃圾回收
- 關於上邊兩種組合的說明
- 一般而言,在企業中,機器的CPU數量都比較多,且CPU的計算能力也不會成為瓶頸,所以對於CMS的併發標記與併發清除階段,會佔用CPU資源的問題,其實不是大事兒;而對於Parallel的注重吞吐量的問題也就不是什麼大事兒了,畢竟CPU是強大的
- 所以,ParNew/CMS是首選(在G1不能用的情況下),Parallel Scavenge/Parallel Old只在想讓JVM自動管理記憶體的情況下使用
注意:在實際調優過程中,可以使用jstat、jconsole、visualVM或GC日誌的檢測資料來調,具體的示例見《深入理解java虛擬機器(第二版)》p142對eclipse執行速度的調優。
關於GC日誌的引數含義與每一種垃圾收集器的GC日誌的格式,檢視《深入理解Java虛擬機器(第二版)》的P89和《深入分析java web技術內幕(修訂版)》的P224