
NO.16——Pathon爬取楊超越新浪微博資料做詞雲分析
看到網上充斥著很多詞雲分析的資料,今天心血來潮,也嘗試下詞雲分析。最近熱火的《創造101》,楊超越小姐姐一直在風口浪尖,因此這裡借用小姐姐的微博資料做分析。
一、準備工具
作詞雲分析主要用到兩個工具:
jieba,俗稱結巴,中文分詞工具;
wordcloud,詞雲生成工具。可以先用pip安裝這兩個庫。
二、分析
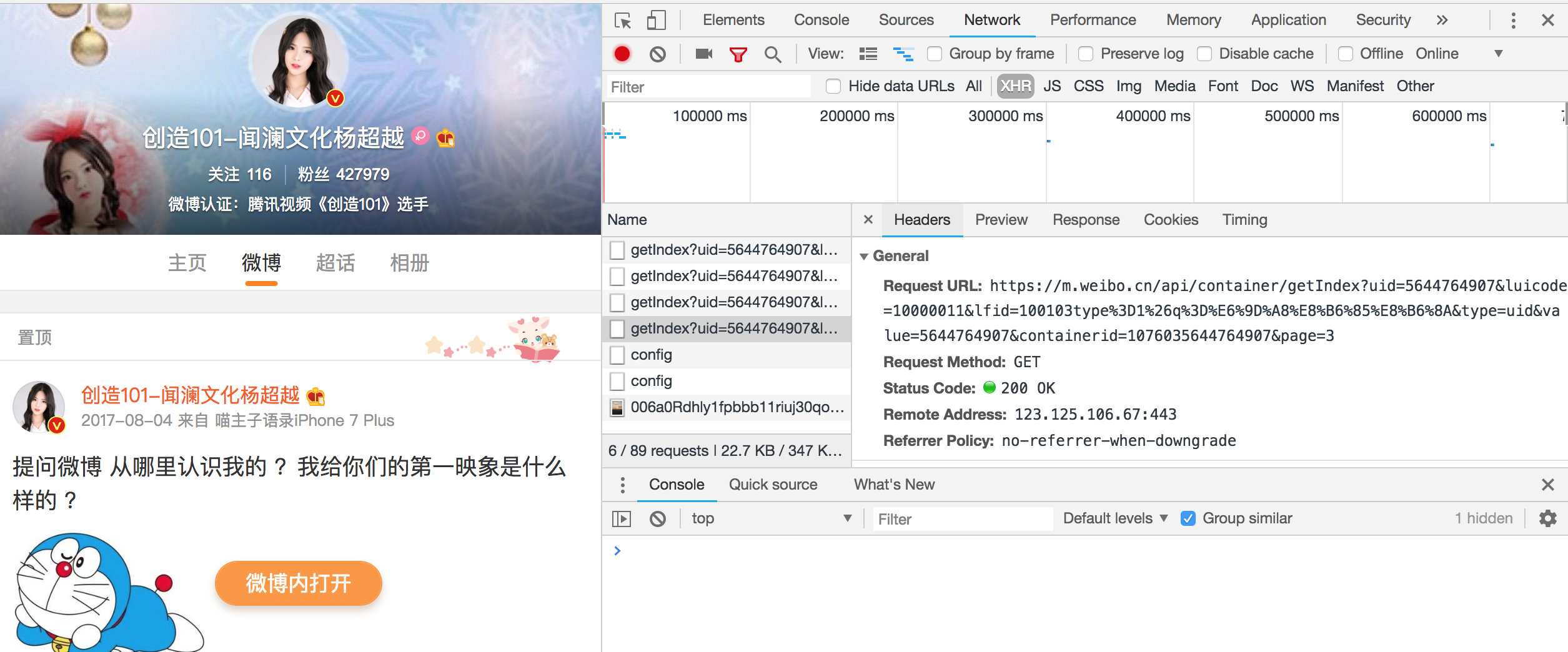
新浪微博應用的是Ajax渲染方式,因此若要準確分析資料需要提取出Ajax請求,Ajax的請求型別為XHR,如圖getIndex字首的都是Ajax請求,檢視其Request URL, 觀察到獲取微博資料的的介面是 https://m.weibo.cn/api/container/getIndex

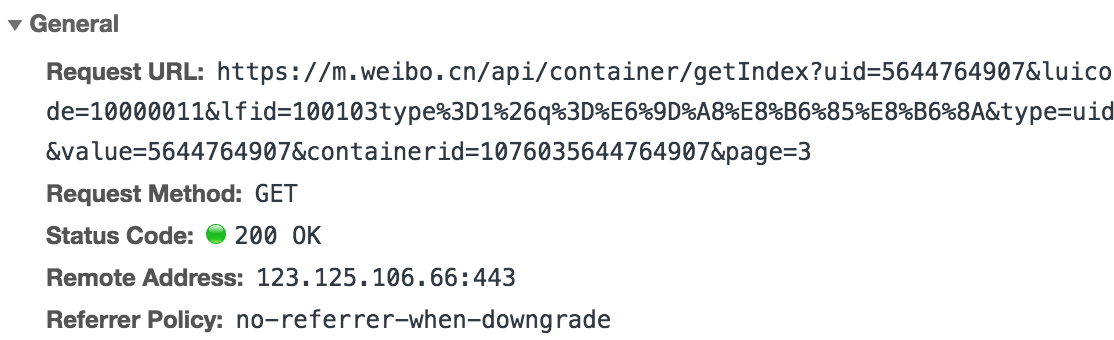
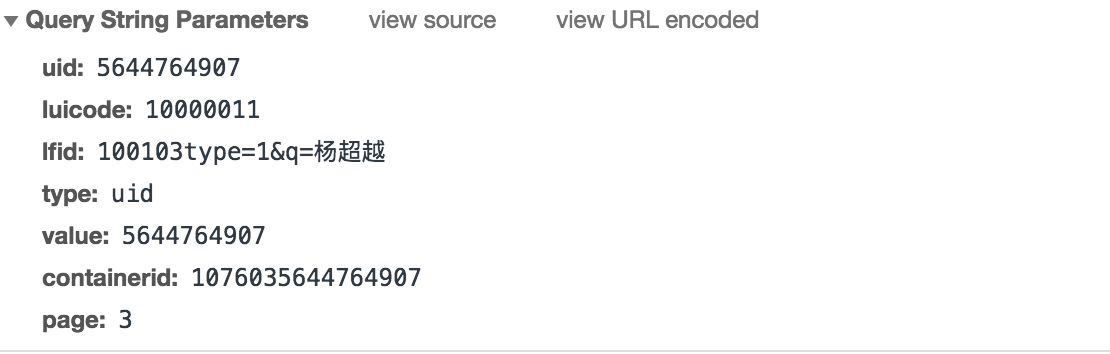
發現其中有一些固定引數在不同請求中是恆定不變的,同時也有一些加密引數,page是翻頁引數。在response選項卡中檢視這個藉口返回的資料,發現是JSON字典型別,在JSON.cn中進行線上轉化:
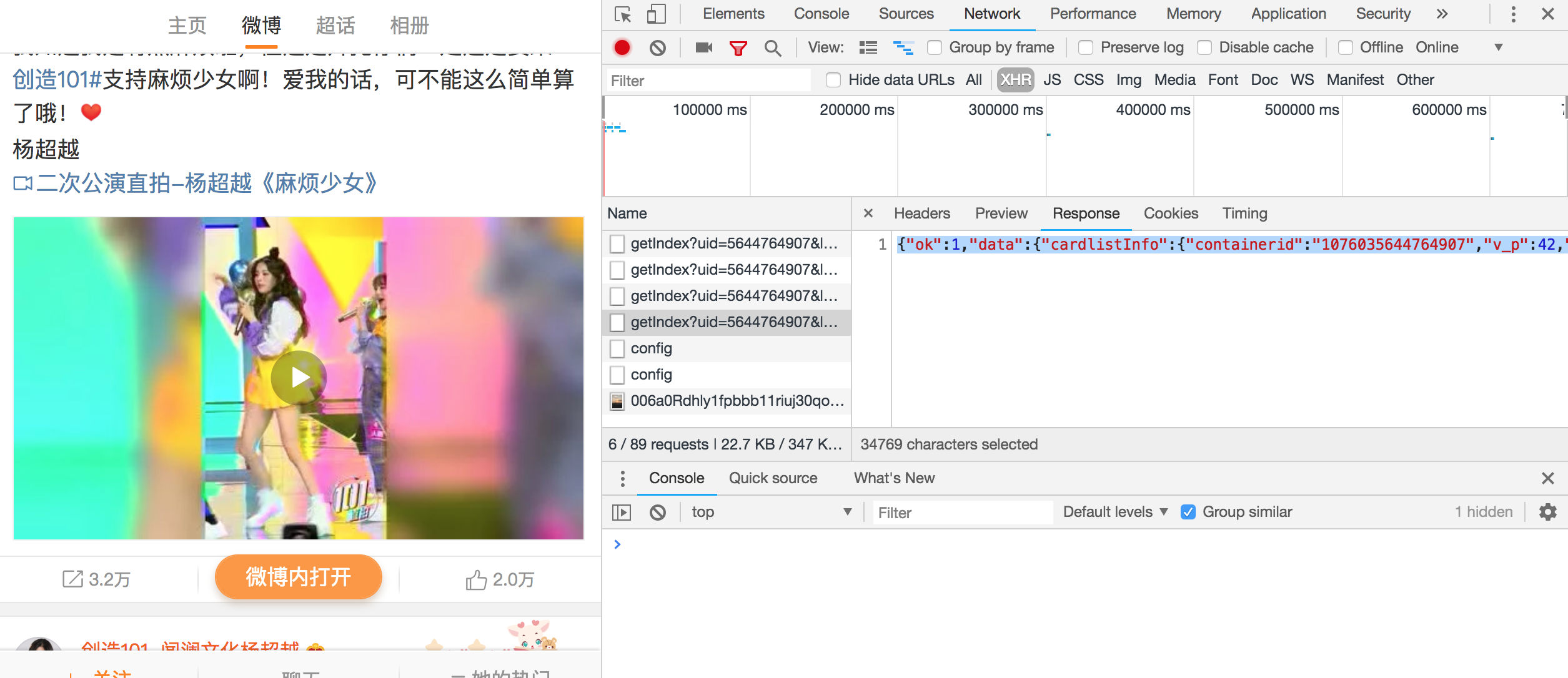
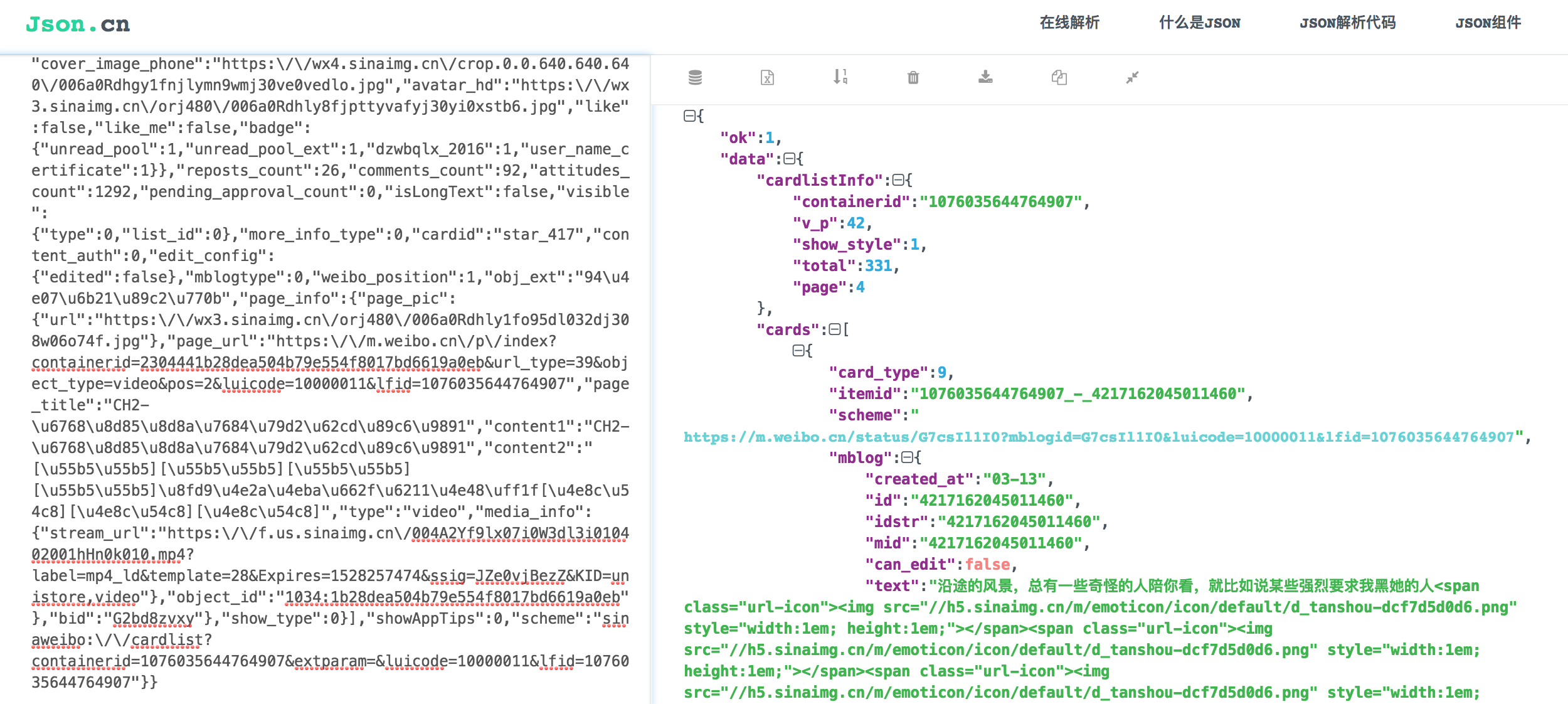
total是微博總條數,page是頁數,每10條微博為一頁,每一條微博都被封裝在cards陣列中,具體內容在text標籤裡。
三、構造請求頭
分析完網頁,我們用requests模擬瀏覽器來獲取資料,因為不需要登陸就可以檢視小姐姐的微博,因此這裡不需要準備cookies。應用以上分析得到的引數構建請求頭:
headers = { "Host": "m.weibo.cn", "Referer": "https://m.weibo.cn/u/5644764907", "User-Agent": "Mozilla/5.0 (iPhone; CPU iPhone OS 9_1 like Mac OS X) AppleWebKit/601.1.46 (KHTML, like Gecko) " "Version/9.0 Mobile/13B143 Safari/601.1", }
url = "https://m.weibo.cn/api/container/getIndex"
params = {"uid": "{uid}",
"luicode": "10000011",
"type": "uid",
"value": "5644764907",
"containerid": "{containerid}",
"page": "{page}"}四、構造簡單爬蟲
通過返回的資料能查詢到總微博條數 total,爬取資料直接利用 requests 提供的方法把 json 資料轉換成 Python 字典物件,從中提取出所有的 text 欄位的值並放到 blogs 列表中,提取文字之前進行簡單過濾,去掉無用資訊。順便把資料寫入檔案,方便下次轉換時不再重複爬取。
同時,在這裡準備一個由常見連線片語成的“結巴關鍵語錄”,裡邊存放“你、我、他、雖然、但是”等連線詞,用這個語錄對微博語句進行斷句。
同時,準備好詞雲背景圖,這個背景圖除了圖案背景最好是白色。
通過hsl函式來決定生成詞雲的顏色。
def grey_color_func(word, font_size, position, orientation, random_state=None,
**kwargs):
s = "hsl(10, %d%%, %d%%)" % (random.randint(200, 255),random.randint(10, 55)) #色相、飽和度、明度
print(s)
return s五、效果圖

哈哈哈,結果出來了,是不是很開心!發現小姐姐提到較多的關鍵字是好看、超越、抖音......
六、原始程式碼
# -*- coding:utf-8 -*-
import codecs
import re
import random
import imageio
import jieba.analyse
import matplotlib.pyplot as plt
import requests
from wordcloud import WordCloud
__author__ = 'Slash'
headers = {
"Host": "m.weibo.cn",
"Referer": "https://m.weibo.cn/u/5644764907",
"User-Agent": "Mozilla/5.0 (iPhone; CPU iPhone OS 9_1 like Mac OS X) AppleWebKit/601.1.46 (KHTML, like Gecko) "
"Version/9.0 Mobile/13B143 Safari/601.1",
}
def clean_html(raw_html):
pattern = re.compile(r'<.*?>|轉發微博|//:|Repost|,|?|。|、|分享圖片|回覆@.*?:|//@.*')
text = re.sub(pattern, '', raw_html)
return text
url = "https://m.weibo.cn/api/container/getIndex"
params = {"uid": "{uid}",
"luicode": "10000011",
"type": "uid",
"value": "5644764907",
"containerid": "{containerid}",
"page": "{page}"}
def fetch_data(uid=None, container_id=None):
"""
抓取資料,並儲存到CSV檔案中
:return:
"""
page = 0
total = 331
blogs = []
for i in range(0, total // 10):
params['uid'] = uid
params['page'] = str(page)
params['containerid'] = container_id
res = requests.get(url, params=params, headers=headers)
cards = res.json().get("data").get("cards")
for card in cards:
# 每條微博的正文內容
if card.get("card_type") == 9:
text = card.get("mblog").get("text")
text = clean_html(text)
blogs.append(text)
page += 1
print("抓取第{page}頁,目前總共抓取了 {count} 條微博".format(page=page, count=len(blogs)))
with codecs.open('weibo.txt', 'a', encoding='utf-8') as f:
f.write("\n".join(blogs))
def grey_color_func(word, font_size, position, orientation, random_state=None,
**kwargs):
s = "hsl(10, %d%%, %d%%)" % (random.randint(200, 255),random.randint(10, 55)) #色相、飽和度、明度
print(s)
return s
def generate_image():
data = []
jieba.analyse.set_stop_words("./stopwords.txt")
with codecs.open("weibo.txt", 'r', encoding="utf-8") as f:
for text in f.readlines():
data.extend(jieba.analyse.extract_tags(text, topK=20))
data = " ".join(data)
mask_img = imageio.imread('./bg.jpg')
wordcloud = WordCloud(
font_path='./WenQuanZhengHei-1.ttf',
background_color='white',
mask=mask_img
).generate(data)
plt.title('Yangchaoyue',fontsize='large')
plt.imshow(wordcloud.recolor(color_func=grey_color_func, random_state=3),
interpolation="bilinear") #雙線性差值
plt.imshow(wordcloud, interpolation="bilinear")
plt.axis('off')
plt.savefig('./yang.jpg', dpi=1600)
if __name__ == '__main__':
fetch_data("5644764907", "1076035644764907")
generate_image()