
利用騰訊AI開放平臺進行情感分析
騰訊AI開放平臺提供了三大功能:自然語言處理、計算機視覺和智慧語音。
情感分析是自然語言處理下的一大分支,騰訊AI的情感分析介面如下:
這裡介紹一下如何利用python來使用騰訊的情感分析API介面服務以便進行大量資料的情感分析。
步驟簡介
1、首先你需要利用QQ號登陸該平臺,進入到控制檯。
2、建立應用,選擇你需要使用的介面(這裡以情感分析為例)。
3、進入應用詳情、你就會看到你的AppID和AppKey。

4、參考情感分析的技術文件,利用python進行接入。
具體實施
1、簽名演算法
首先我們在呼叫API時要搞定介面鑑權,即簽名演算法。
根據介面鑑權的技術文件,可知簽名演算法採用MD5摘要方式實現,且演算法的實現步驟技術文件裡面很詳細,剛好python裡面有相應的包,直接import hashlib即可,我這裡就直接貼程式碼了。
# -*- coding: utf-8 -*-
"""
-------------------------------------------------
File Name: md5sign
Description :
Author : YOUQING
date: 2017/11/20
-------------------------------------------------
Change Activity:
2017/11/20:
-------------------------------------------------
""" 注意事項
1、app_id、app_key替換成自己應用詳情裡的相應內容
2、plus_item是你要輸入的文字內容
3、檔名:md5sign
2、介面呼叫
上一段程式碼得到的是請求引數,這裡我們需要將API地址和請求引數拼接起來,然後採用請求方法GET,並用BeautifulSoup去解析(簡單的爬蟲知識)。
由於響應格式是JSON格式,我們採用json.loads來轉換為字典,以便獲取我們想要的內容(情感傾向、極性與文字內容)
程式碼如下:
# -*- coding: utf-8 -*-
"""
-------------------------------------------------
File Name: tencent_api
Description :
Author : YOUQING
date: 2017/11/20
-------------------------------------------------
Change Activity:
2017/11/20:
-------------------------------------------------
"""
import requests
import md5sign
from bs4 import BeautifulSoup
import json
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
def get_content(plus_item):
url = "https://api.ai.qq.com/fcgi-bin/nlp/nlp_textpolar" # API地址
params = md5sign.get_params(plus_item)#獲取請求引數
url=url+'?'+params#請求地址拼接
try:
r = requests.get(url)
soup = BeautifulSoup(r.text, 'lxml')
allcontents=soup.select('body')[0].text.strip()
allcontents_json=json.loads(allcontents)#str轉成dict
return allcontents_json["data"]["polar"],allcontents_json["data"]["confd"],allcontents_json["data"]["text"]
except Exception, e:
print 'a', str(e)
return 0,0,0
if __name__ == '__main__':
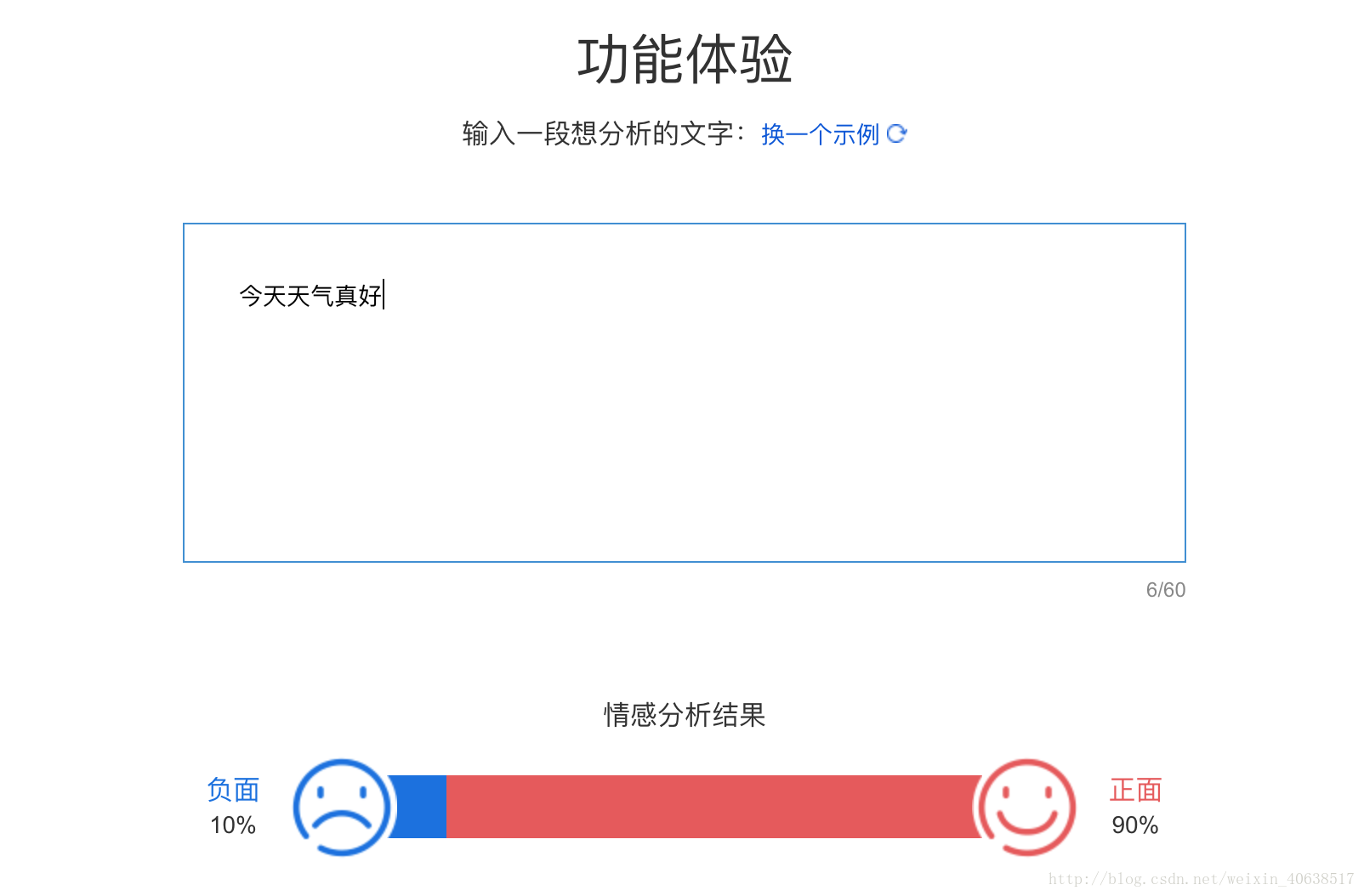
polar,confd,text=get_content('今天天氣真好')
print '情感傾向:'+str(polar)+'\n'+'程度:'+str(confd)+'\n'+'文字:'+text執行結果
極性:1
程度:0.90936
文字:今天天氣真好
(注:1代表正面情感;0代表中性;-1代表負面情感)
小結
騰訊的情感分析號稱是依託於騰訊千億級社交語料的支撐,但我認為在使用過程中的準確性還是要看使用的場景,反正我用來分析酒店評論時並不是很滿意得到的結果(可能需要專門的酒店語料庫才能更加準確)。且text的長度上限200位元組,這就造成了使用時較大的限制。