
Netty學習之旅------原始碼分析Netty執行緒本地分配機制與PooledByteBuf執行緒級物件池原理分析
阿新 • • 發佈:2019-01-08
在方法前,已經對構造方法的入參加了說明,關注如下兩個方法。 程式碼@1,建立createNormalCaches 。 由於PoolThreadCache的設計理念與PoolArena一樣,本身並不涉及到具體記憶體的儲存,PoolThreadCache內部維護MemoryRegionCache[] tinySubpageHeapCaches,MemoryRegionCache[] smallSubpageHeapCaches,其陣列長度與PoolArena相同,MemoryRegionCaches[] normalHeapCaches,快取的是noraml記憶體,Netty把大於pageSize小於chunkSize的空間成為normal記憶體。normalHeapCaches[1] 是normalHeapCaches[0] 的2倍, 先重點關注final PoolArena<byte[]> heapArena; //使用輪叫輪詢機制,每個執行緒從heapArena[]中獲取一個,用於記憶體分配。 final PoolArena<ByteBuffer> directArena; //同上 // Hold the caches for the different size classes, which are tiny, small and normal. //針對不同大小,執行緒快取的記憶體 private final MemoryRegionCache<byte[]>[] tinySubPageHeapCaches; private final MemoryRegionCache<byte[]>[] smallSubPageHeapCaches; private final MemoryRegionCache<ByteBuffer>[] tinySubPageDirectCaches; private final MemoryRegionCache<ByteBuffer>[] smallSubPageDirectCaches; private final MemoryRegionCache<byte[]>[] normalHeapCaches; private final MemoryRegionCache<ByteBuffer>[] normalDirectCaches; // Used for bitshifting when calculate the index of normal caches later private final int numShiftsNormalDirect; private final int numShiftsNormalHeap; private final int freeSweepAllocationThreshold; private int allocations; private final Thread thread = Thread.currentThread(); //當前執行緒 private final Runnable freeTask = new Runnable() { //執行緒消亡後,釋放資源,下文會重點講解。 @Override public void run() { free0(); } }; // TODO: Test if adding padding helps under contention //private long pad0, pad1, pad2, pad3, pad4, pad5, pad6, pad7; /* * @param heapArena 執行緒使用的PoolArena.HeapArena * @param directArena 執行緒使用的PoolArena.DirectArena * @param tinyCacheSize, tiny記憶體快取的個數。預設為512 * @param smallCacheSize small記憶體快取的個數,預設為256個 * @param normalCacheSize normalCacheSize快取的個數,預設為64 * @param maxCacheBufferCapacity * normalHeapCaches中單個快取區域的最大大小,預設為32k 也就是normalHeapCaches[length-1]中快取的最大記憶體空間 * @param freeSweepAllocationThreshold 在本地執行緒每分配freeSweepAllocationThreshold 次記憶體後,檢測一下是否需要釋放記憶體。 */ PoolThreadCache(PoolArena<byte[]> heapArena, PoolArena<ByteBuffer> directArena, int tinyCacheSize, int smallCacheSize, int normalCacheSize, int maxCachedBufferCapacity, int freeSweepAllocationThreshold) { if (maxCachedBufferCapacity < 0) { throw new IllegalArgumentException("maxCachedBufferCapacity: " + maxCachedBufferCapacity + " (expected: >= 0)"); } if (freeSweepAllocationThreshold < 1) { throw new IllegalArgumentException("freeSweepAllocationThreshold: " + maxCachedBufferCapacity + " (expected: > 0)"); } this.freeSweepAllocationThreshold = freeSweepAllocationThreshold; this.heapArena = heapArena; this.directArena = directArena; if (directArena != null) { tinySubPageDirectCaches = createSubPageCaches(tinyCacheSize, PoolArena.numTinySubpagePools); smallSubPageDirectCaches = createSubPageCaches(smallCacheSize, directArena.numSmallSubpagePools); numShiftsNormalDirect = log2(directArena.pageSize); normalDirectCaches = createNormalCaches( normalCacheSize, maxCachedBufferCapacity, directArena); } else { // No directArea is configured so just null out all caches tinySubPageDirectCaches = null; smallSubPageDirectCaches = null; normalDirectCaches = null; numShiftsNormalDirect = -1; } if (heapArena != null) { // Create the caches for the heap allocations tinySubPageHeapCaches = createSubPageCaches(tinyCacheSize, PoolArena.numTinySubpagePools); smallSubPageHeapCaches = createSubPageCaches(smallCacheSize, heapArena.numSmallSubpagePools); numShiftsNormalHeap = log2(heapArena.pageSize); normalHeapCaches = createNormalCaches( normalCacheSize, maxCachedBufferCapacity, heapArena); //@1 } else { // No heapArea is configured so just null out all caches tinySubPageHeapCaches = null; smallSubPageHeapCaches = null; normalHeapCaches = null; numShiftsNormalHeap = -1; } // The thread-local cache will keep a list of pooled buffers which must be returned to // the pool when the thread is not alive anymore. ThreadDeathWatcher.watch(thread, freeTask); }
引數 numCaches,為SubPageMemoryRegionCache[]陣列的長度,而cacheSize,為每一個SubPageMemoryRegionCache中快取的記憶體個數,也就是SubPageMemoryRegionCache中entries[]的長度。這裡的cacheSize,就是PooledByteBufAllocator DEFAULT_TINY_CACHE_SIZE=512,DEFAULT_SMALL_CACHE_SIZE=256,DEFAULT_NORMAL_SIZE=64,其實這裡的取名為DEFAULT_TINY_CACHE_LENGTH更加貼切。 程式碼@1,其實應該不需要與area.chunkSize做比較,因為如果超過chunkSize的記憶體,netty不會重複使用,直接在整個堆空間或堆外空間申請並釋放。這裡可能是出於程式碼的自我保護,得到normalHeapCaches中單個 Entry所持有的記憶體不超過該值。 程式碼@2,計算normalHeapCaches陣列的長度,這裡有優化的空間,用位運算:int arraySize = Math.max(1, max >> numShiftsNormalHeap ),其中numShiftsNormalHeap為 log2(pageSize)。這樣做的原因,也就是normalHeapCaches 陣列中的元素的大小,是以2的冪倍pageSize遞增的。cacheSize預設為64,引數值來源於PooledByteBufAllocator。接下來關注PoolThreadCache的allocateTiny方法: 1.2 PoolThreadCache allocateTiny方法private static <T> NormalMemoryRegionCache<T>[] createNormalCaches( int cacheSize, int maxCachedBufferCapacity, PoolArena<T> area) { if (cacheSize > 0) { int max = Math.min(area.chunkSize, maxCachedBufferCapacity); //@1 int arraySize = Math.max(1, max / area.pageSize); //@2 @SuppressWarnings("unchecked") NormalMemoryRegionCache<T>[] cache = new NormalMemoryRegionCache[arraySize]; for (int i = 0; i < cache.length; i++) { cache[i] = new NormalMemoryRegionCache<T>(cacheSize); } return cache; } else { return null; } }
/**
* Try to allocate a tiny buffer out of the cache. Returns {@code true} if successful {@code false} otherwise
*/
boolean allocateTiny(PoolArena<?> area, PooledByteBuf<?> buf, int reqCapacity, int normCapacity) {
return allocate(cacheForTiny(area, normCapacity), buf, reqCapacity);
}
private MemoryRegionCache<?> cacheForTiny(PoolArena<?> area, int normCapacity) {
int idx = PoolArena.tinyIdx(normCapacity);
if (area.isDirect()) {
return cache(tinySubPageDirectCaches, idx);
}
return cache(tinySubPageHeapCaches, idx);
}
/**
* Try to allocate a small buffer out of the cache. Returns {@code true} if successful {@code false} otherwise
*/
boolean allocateNormal(PoolArena<?> area, PooledByteBuf<?> buf, int reqCapacity, int normCapacity) {
return allocate(cacheForNormal(area, normCapacity), buf, reqCapacity);
}
private MemoryRegionCache<?> cacheForNormal(PoolArena<?> area, int normCapacity) {
if (area.isDirect()) {
int idx = log2(normCapacity >> numShiftsNormalDirect);
return cache(normalDirectCaches, idx);
}
int idx = log2(normCapacity >> numShiftsNormalHeap); //@1
return cache(normalHeapCaches, idx);
}
private boolean allocate(MemoryRegionCache<?> cache, PooledByteBuf buf, int reqCapacity) {
if (cache == null) {
// no cache found so just return false here
return false;
}
boolean allocated = cache.allocate(buf, reqCapacity); //@2
if (++ allocations >= freeSweepAllocationThreshold) {
allocations = 0;
trim(); //@3
}
return allocated;
}private final Entry<T>[] entries; //MemoryRegionCache真正持有記憶體的地方
/*
private static final class Entry<T> {
PoolChunk<T> chunk; //具體的PoolChunk
long handle; //記憶體持有偏移量,高32位儲存的是bitmaIdx,低32位儲存的是memoryMapIdx
}
*/
private final int maxUnusedCached; //表示允許的最大的沒有使用的記憶體數量(已經被快取),預設為size的一半。
private int head; // 作用類似於ByteBuf的readerIndex,從該位置獲取一個快取的Entiry。
private int tail; // 作用類似於ByteBuf的writerIndex,從該位置增加一個加入一個新的Entity
private int maxEntriesInUse; // 在使用中最大的entry數量
private int entriesInUse; // 目前使用中的entry數量
@SuppressWarnings("unchecked")
MemoryRegionCache(int size) { // size 預設的大小為 512, 256, 64
entries = new Entry[powerOfTwo(size)];
for (int i = 0; i < entries.length; i++) {
entries[i] = new Entry<T>();
}
maxUnusedCached = size / 2; //允許被快取,但沒有使用的最大數量,超過該值,則會觸發記憶體釋放操作。
}maxUnusedCached : 256,128,32,為size的一半;head:0 ;tail:0 ; maxEntriesInUse : 0; entriesInUse : 0 2)MemoryRegionCache的allocate方法詳解
/**
* Allocate something out of the cache if possible and remove the entry from the cache.
*/
public boolean allocate(PooledByteBuf<T> buf, int reqCapacity) {
Entry<T> entry = entries[head]; //@1
if (entry.chunk == null) { //@2
return false;
}
entriesInUse ++; //@3
if (maxEntriesInUse < entriesInUse) {
maxEntriesInUse = entriesInUse;
}
initBuf(entry.chunk, entry.handle, buf, reqCapacity); //@4
// only null out the chunk as we only use the chunk to check if the buffer is full or not.
entry.chunk = null; //@5
head = nextIdx(head); //@6
return true;
}void trim() {
trim(tinySubPageDirectCaches);
trim(smallSubPageDirectCaches);
trim(normalDirectCaches);
trim(tinySubPageHeapCaches);
trim(smallSubPageHeapCaches);
trim(normalHeapCaches);
}
private static void trim(MemoryRegionCache<?>[] caches) {
if (caches == null) {
return;
}
for (MemoryRegionCache<?> c: caches) {
trim(c);
}
}
private static void trim(MemoryRegionCache<?> cache) {
if (cache == null) {
return;
}
cache.trim();
}
trim的具體實現是MemoryRegionCache,現在進入到MemoryRegionCache詳解:
/**
* Free up cached {@link PoolChunk}s if not allocated frequently enough.
*/
private void trim() {
int free = size() - maxEntriesInUse; //@1
entriesInUse = 0;
maxEntriesInUse = 0; //@2
if (free <= maxUnusedCached) { //@3
return;
}
int i = head;
for (; free > 0; free--) {
if (!freeEntry(entries[i])) {
// all freed
break;
}
i = nextIdx(i);
}
// Update head to point to te correct entry
// See https://github.com/netty/netty/issues/2924
head = i;
}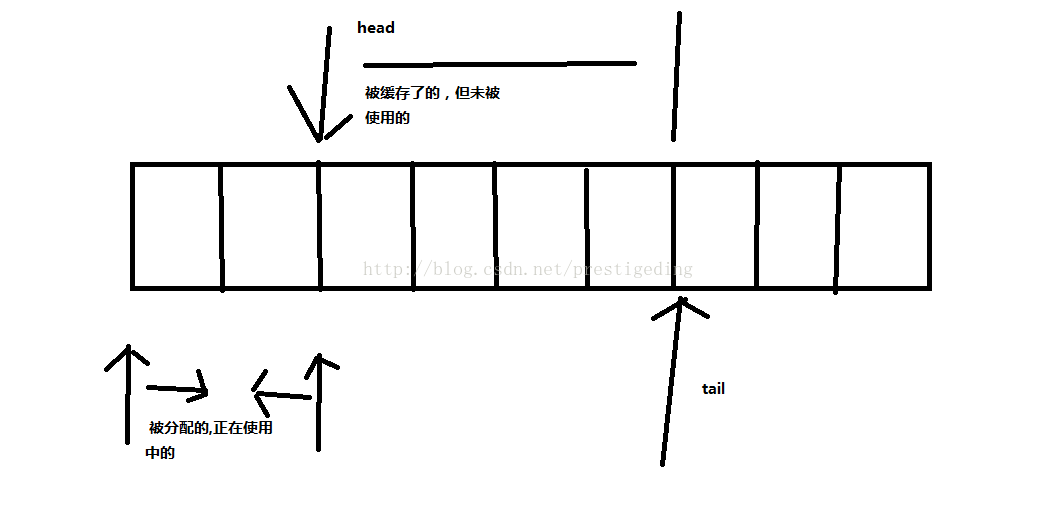
程式碼@1,size()方法返回的是 (tail-head) & (length-1),表示當前快取了但未被使用的個數。maxEntriesInUse的值,其實就是entiryesInUse的值。 程式碼@2,程式碼@3,如果快取的並且未使用的個數如果小於允許的值(maxUnusedCached)值是放棄本次記憶體釋放,否則,需要將head到tail這部分的記憶體全部釋放,返回給全域性記憶體分配池。這裡我可能沒有理解透徹,如果是我實現的話,entriesInUse該值不會設定為空,而是直接釋放掉 tail-head這部分的記憶體就好,釋放演算法在記憶體分配與釋放篇已經做過詳細解讀,這裡不重複講解:
@SuppressWarnings({ "unchecked", "rawtypes" })
private static boolean freeEntry(Entry entry) {
PoolChunk chunk = entry.chunk;
if (chunk == null) {
return false;
}
// need to synchronize on the area from which it was allocated before.
synchronized (chunk.arena) {
chunk.parent.free(chunk, entry.handle);
}
entry.chunk = null;
return true;
}