
自然語言處理之:c++中文分詞(附原始碼)
githup地址:https://github.com/jbymy
一、簡介
中文分詞是地然語言處理中的最基礎的環節,到目前為止已經有不少優秀的分詞工具的出現,如“中科院分詞”,“結巴分詞”等。個人認為在中文分詞領域在演算法層面上雖層出不窮,但歸其根本仍然是大同小異,基於統計的分詞演算法在根本上並無太大差別,因此我寫的這個分詞演算法在保證高準確性的情況下以實用性,靈活性為主打方向。
二、wordseg分詞演算法
借鑑結巴分詞的思想,採用基於詞典的有向無環圖演算法結合HMM隱馬爾科夫模型分詞。關於結巴分詞已經有非常成熟的版本了,本分詞工具中的基礎詞典也是結巴分詞的詞典加上自己整理的新詞。wordseg分詞工具基本思路如下:
- 用TRIE樹儲存詞典
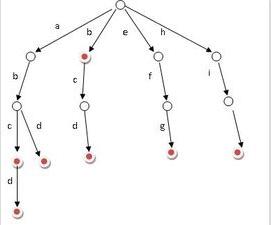
Trie樹的詳細描述詳見維基百科,這裡有一張百科截圖
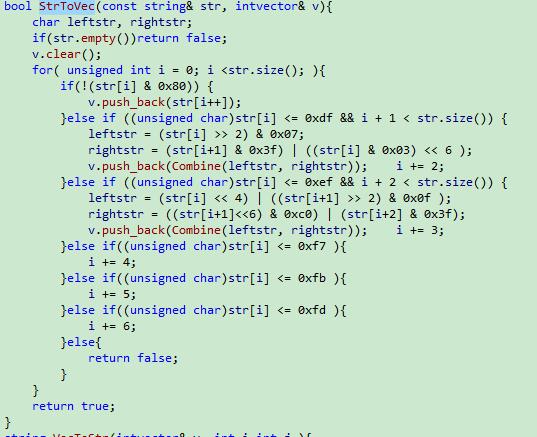
上圖顯示的是英文詞典的Trie樹,中文詞典構成Trie數也和上圖類似,只不過每一個節點儲存的是每個中文漢字的編碼(在linux下一般是UTF-8編碼,每一個漢字用一個INT型變量表示,具體的轉碼方式參見UTF-8編碼)或者我程式碼中的func.cpp中的如下程式碼
該函式實現的功能是將漢字字串轉為 int16 的 vector
Trie樹的每一個節點儲存從根節點到該節點是否成詞語、詞頻、詞性等資訊。 - 按分割符切割文字
按照分割符號進行首輪切割,文字處理中一般講一篇文章處理成一行,因此首輪切割以trie樹根節點中未出現的字元進行切割:標點符號,其他字元等,可利用自定義詞典制定規則。 - 對短句進行切分
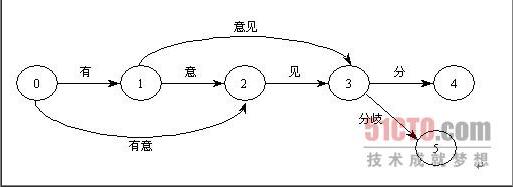
1:有向無環圖分詞
一個句子的分詞路徑會形成一個有向無環圖,從網上找到的示意圖如下:
一個句子的分詞概率可以看做是每個詞語形成的聯合概率,每個詞語的概率為 :詞頻/詞典總詞頻
因此問題轉為一個最短路徑問題,可參照經典的最短路徑演算法解決,具體可見seg.cpp。
2:人名識別模組
人名識別模組是命名實體識別中的一部分,根據需求就單獨提了出來,可以用經典的HMM進行識別。本演算法中我是用了400萬中文人名訓練得到詞典。
3:HMM補充分詞
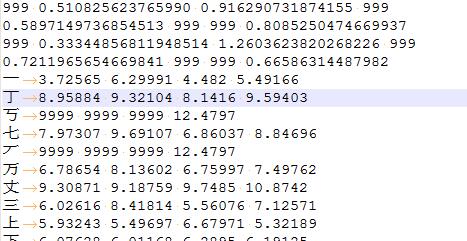
HMM分詞是對語句進行序列標註的過程。給定一個字的序列,找出最可能的標籤序列。利用BMES標籤來分詞的,B(開頭),M(中間),E(結尾),S(獨立成詞)。HMM分詞的詞典如下:
這裡只顯示了前面幾行,前四行是狀態轉移矩陣:BEMS四種狀態的轉移矩陣,下面是發射矩陣:是BEMS四種狀態下發射到當前觀測值(漢字)的條件概率(詞典為了後續計算方便儲存的是中間計算用值而非原始概率)。
兩個矩陣的計算:通過統計已標註訓練語料統計字的序列標註情況和狀態的二元轉移即可得到。
句子的狀態系列可以用維特比演算法實現。本分詞工具中採用HMM作為詞典分詞的補充,為了召回未登入命名實體詞:如“知春路”等。

三、HMM模型和基於詞典分詞的異同點
相同點
都是採用統計的方法:基於詞典的DAG分詞利用了詞頻作為每個詞的概率,最後計算整句的聯合概率;從另一個角度看HMM,也是統計了詞語概率分佈情況,例如“中國”這個詞,P(B)*P(中|B)*P(E)*P(國|E) 就是該詞的概率,只不過採用了另外的形式用轉移矩陣和發射矩陣來計算。採用同一份訓練語料可以同時生成分詞詞典和HMM矩陣。
消歧演算法:詞典分詞采用了最短路徑演算法,HMM分詞采用了維特比演算法,仔細研究這兩種演算法不難發現這兩種演算法是很類似的。不同點
詞典分詞基於的是自定義詞典,會更加準確但是對未登入詞無法識別,不在詞典中的詞的概率為零,而HMM則相對模糊,任意兩個字之間都能轉移概率,像“XX路”這種詞語,由於“路”作為“E”的概率很大,很容易被識別為實體詞,這對於命名實體識別別具效果。
四、當前分詞領域的難點
中文分詞發展到今天,就演算法層面上來看,各大演算法雖別具一格但都殊途同歸,各有利弊,對於常規詞語效果相差無幾。中文分詞的瓶頸在於未登入詞,放眼到實際業務中,真正對業務效果有影響的是垂直領域類的未登入詞,市面上的各種開源分詞工具都無法做到,這在業界也是一難題。在具體的業務中往往要通過一些實體詞挖掘,新詞挖掘方法來補充詞典,對於不同的業務,詞語的粒度都不一樣,因此還需要具體問題具體解決。
五、wordseg分詞工具的使用
直接使用程式:下載githup程式碼,commom, dict, wordseg 放在同一目錄下,在wordseg目錄下執行make生成可執行檔案seg 即可。
./seg 0 ../dict/seg/ inputfile(輸入檔案) outputfile(輸出檔案)
分詞函式使用示例見 main.cpp
