
【JAVA實現】樸素貝葉斯分類演算法
之前部落格提到的KNN演算法以及決策樹演算法都是要求分類器給出“該資料例項屬於哪一類”這類問題的明確答案,正因為如此,才出現了使用決策樹分類時,有時無法判定某一測試例項屬於哪一類別。使用樸素貝葉斯演算法則可以避免這個問題,它給出了這個例項屬於某一類別的概率值,然後通過比較概率值,可以找到該例項最有可能屬於哪一類別。
該演算法可以用如下形式表示:

直接求解概率值很困難,因此我們可以通過下列式子進行變化。
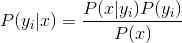
因為分母對於所有類別都是固定值,所以我們只要求能使得分子最大化的類別即可。又因為樸素貝葉斯假設各特徵屬性條件獨立,所以有:

樸素貝葉斯分類器通常有兩種實現方式:一種基於貝努利模型實現,一種基於多項式模型實現。貝努利實現方式也稱“詞集模型”,其不考慮詞在文件中出現的次數,只考慮出不出現,因此在這個意義上相當於假設詞是等權重的。而多項式模型也稱“詞袋模型”,它考慮詞在文件中的出現次數。本文采用的是多項式模型。
這次的案例使用的是使用樸素貝葉斯過濾垃圾郵件。訓練集如下所示:

第一個資料夾下放的是25篇正常的純文字郵件,第二個資料夾放的是25篇純文字垃圾郵件。
首先是郵件內容的封裝。
第一個欄位為每封郵件分好詞的集合,第二個欄位表示這封郵件是否是垃圾郵件。package naivebayesian; import java.util.List; public class Email { private List<String> wordList; private int flag; public int getFlag() { return flag; } public void setFlag(int flag) { this.flag = flag; } public List<String> getWordList() { return wordList; } public void setWordList(List<String> wordList) { this.wordList = wordList; } }
可能比較亂,我把所有的模組寫在了一起。首先是從兩個資料夾中讀取郵件,建立資料集。讀取同時,會對郵件的內容進行分詞,這裡的分詞規則比較簡單,分隔符為非文字字元,可以根據自己規則定義。package naivebayesian; import java.io.BufferedReader; import java.io.FileInputStream; import java.io.IOException; import java.io.InputStreamReader; import java.util.ArrayList; import java.util.LinkedHashSet; import java.util.List; import java.util.Random; import java.util.Set; public class NaiveBayesian { private List<Double> p0Vec = null; //垃圾郵件中每個詞出現的概率 private List<Double> p1Vec = null; //垃圾郵件出現的概率 private double pSpamRatio; /** * 初始化資料集 * * @return */ public List<Email> initDataSet() { List<Email> dataSet = new ArrayList<Email>(); BufferedReader bufferedReader1 = null; BufferedReader bufferedReader2 = null; try { for (int i = 1; i < 26; i++) { bufferedReader1 = new BufferedReader(new InputStreamReader( new FileInputStream( "/home/shenchao/Desktop/MLSourceCode/machinelearninginaction/Ch04/email/ham/" + i + ".txt"))); StringBuilder sb1 = new StringBuilder(); String string = null; while ((string = bufferedReader1.readLine()) != null) { sb1.append(string); } Email hamEmail = new Email(); hamEmail.setWordList(textParse(sb1.toString())); hamEmail.setFlag(0); bufferedReader2 = new BufferedReader(new InputStreamReader( new FileInputStream( "/home/shenchao/Desktop/MLSourceCode/machinelearninginaction/Ch04/email/spam/" + i + ".txt"))); StringBuilder sb2 = new StringBuilder(); while ((string = bufferedReader2.readLine()) != null) { sb2.append(string); } Email spamEmail = new Email(); spamEmail.setWordList(textParse(sb2.toString())); spamEmail.setFlag(1); dataSet.add(hamEmail); dataSet.add(spamEmail); } return dataSet; } catch (Exception e) { e.printStackTrace(); throw new RuntimeException(); } finally { try { bufferedReader1.close(); bufferedReader2.close(); } catch (IOException e) { e.printStackTrace(); } } } /** * 分詞,英文的分詞相比中文的分詞要簡單很多,這裡使用的分隔符為除單詞、數字外的任意字串 * 如果使用中文,則可以使用中科院的一套分詞系統,分詞效果還算不錯 * * @param originalString * @return * @return */ private List<String> textParse(String originalString) { String[] s = originalString.split("\\W"); List<String> wordList = new ArrayList<String>(); for (String string : s) { if (string.contains(" ")) { continue; } if (string.length() > 2) { wordList.add(string.toLowerCase()); } } return wordList; } /** * 構建單詞集,此長度等於向量長度 * * @return */ public Set<String> createVocabList(List<Email> dataSet) { Set<String> set = new LinkedHashSet<String>(); for (Email email : dataSet) { for (String string : email.getWordList()) { set.add(string); } } return set; } /** * 將郵件轉換為向量 * * @param vocabSet * @param inputSet * @return */ public List<Integer> setOfWords2Vec(Set<String> vocabSet, Email email) { List<Integer> returnVec = new ArrayList<Integer>(); for (String word : vocabSet) { returnVec.add(calWordFreq(word, email)); } return returnVec; } /** * 計算一個詞在某個集合中的出現次數 * * @return */ private int calWordFreq(String word, Email email) { int num = 0; for (String string : email.getWordList()) { if (string.equals(word)) { ++num; } } return num; } public void trainNB(Set<String> vocabSet, List<Email> dataSet) { // 訓練文字的數量 int numTrainDocs = dataSet.size(); // 訓練集中垃圾郵件的概率 pSpamRatio = (double) calSpamNum(dataSet) / numTrainDocs; // 記錄每個類別下每個詞的出現次數 List<Integer> p0Num = new ArrayList<Integer>(); List<Integer> p1Num = new ArrayList<Integer>(); // 記錄每個類別下一共出現了多少詞,為防止分母為0,所以在此預設值為2 double p0Denom = 2.0, p1Denom = 2.0; for (Email email : dataSet) { List<Integer> list = setOfWords2Vec(vocabSet, email); // 如果是垃圾郵件 if (email.getFlag() == 1) { p1Num = vecAddVec(p1Num, list); //計算該類別下出現的所有單詞數目 p1Denom += calTotalWordNum(list); }else { p0Num = vecAddVec(p0Num, list); p0Denom += calTotalWordNum(list); } } p0Vec = calWordRatio(p0Num, p0Denom); p1Vec = calWordRatio(p1Num, p1Denom); } /** * 兩個向量相加 * * @param vec1 * @param vec2 * @return */ private List<Integer> vecAddVec(List<Integer> vec1, List<Integer> vec2) { if (vec1.size() == 0) { return vec2; } List<Integer> list = new ArrayList<Integer>(); for (int i = 0; i < vec1.size(); i++) { list.add(vec1.get(i) + vec2.get(i)); } return list; } /** * 計算垃圾郵件的數量 * * @param dataSet * @return */ private int calSpamNum(List<Email> dataSet) { int time = 0; for (Email email : dataSet) { time += email.getFlag(); } return time; } /** * 統計出現的所有單詞數 * @param list * @return */ private int calTotalWordNum(List<Integer> list) { int num = 0; for (Integer integer : list) { num += integer; } return num; } /** * 計算每個單詞在該類別下的出現概率,為防止分子為0,導致樸素貝葉斯公式為0,設定分子的預設值為1 * @param list * @param wordNum * @return */ private List<Double> calWordRatio(List<Integer> list, double wordNum) { List<Double> vec = new ArrayList<Double>(); for (Integer i : list) { vec.add(Math.log((double)(i+1) / wordNum)); } return vec; } /** * 比較不同類別 p(w0,w1,w2...wn | ci)*p(ci) 的大小 <br> * p(w0,w1,w2...wn | ci) = p(w0|ci)*p(w1|ci)*p(w2|ci)... <br> * 由於防止下溢,對中間計算值都取了對數,因此上述公式化為log(p(w0,w1,w2...wn | ci)) + log(p(ci)),即 * 化為多個式子相加得到結果 * * @param email * @return 返回概率最大值 */ public int classifyNB(List<Integer> emailVec) { double p0 = calProbabilityByClass(p0Vec, emailVec) + Math.log(1 - pSpamRatio); double p1 = calProbabilityByClass(p1Vec, emailVec) + Math.log(pSpamRatio); if (p0 > p1) { return 0; }else { return 1; } } private double calProbabilityByClass(List<Double> vec,List<Integer> emailVec) { double sum = 0.0; for (int i = 0; i < vec.size(); i++) { sum += (vec.get(i) * emailVec.get(i)); } return sum; } public double testingNB() { List<Email> dataSet = initDataSet(); List<Email> testSet = new ArrayList<Email>(); //隨機取前10作為測試樣本 for (int i = 0; i < 10; i++) { Random random = new Random(); int n = random.nextInt(50-i); testSet.add(dataSet.get(n)); //從訓練樣本中刪除這10條測試樣本 dataSet.remove(n); } Set<String> vocabSet = createVocabList(dataSet); //訓練樣本 trainNB(vocabSet, dataSet); int errorCount = 0; for (Email email : testSet) { if (classifyNB(setOfWords2Vec(vocabSet, email)) != email.getFlag()) { ++errorCount; } } // System.out.println("the error rate is: " + (double) errorCount / testSet.size()); return (double) errorCount / testSet.size(); } public static void main(String[] args) { NaiveBayesian bayesian = new NaiveBayesian(); double d = 0; for (int i = 0; i < 50; i++) { d +=bayesian.testingNB(); } System.out.println("total error rate is: " + d / 50); } }
利用貝葉斯分類器對文件進行分類時,要計算多個概率的乘積以獲得文件屬於某個類別的概率,如果其中一個概率值為0,那麼最後乘積也為0,因此為降低這種影響,可以將所有詞的出現次數初始化為1,將分母初始化為2。另一個問題是下溢,這是由於太多很小的數相乘造成的,導致最後四捨五入會得到0.解決辦法是對乘積取自然對數。
最後,從訓練樣本中隨機選取10條作為測試集,進行錯誤率計算,重複十次,取平均數得到最後的錯誤率為4%。發現結果還是不錯的。
通過特徵之間的條件獨立性假設,可以降低對資料量的需求。但是獨立性假設是指一個詞的出現概率並不依賴於文件中的其他詞,可見這個假設過於簡單,可能會影響最後的準確率。
如有什麼問題,歡迎大家和我一起學習探討。