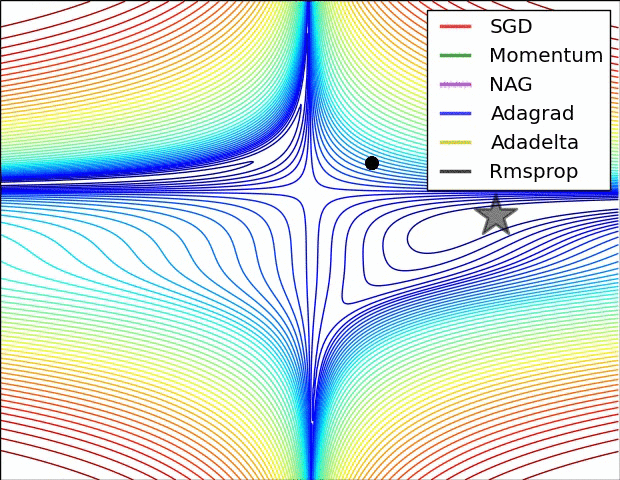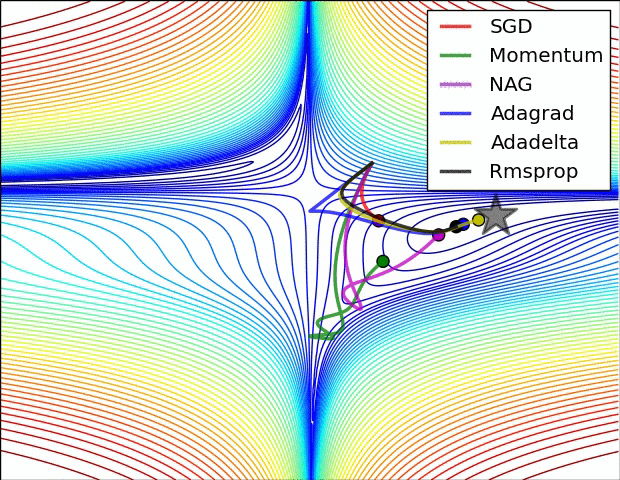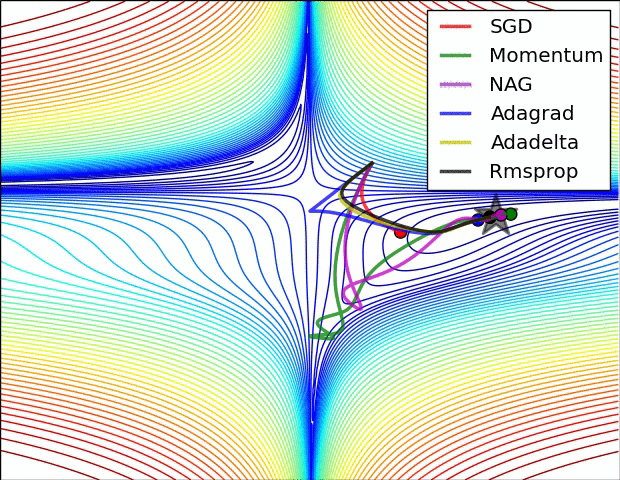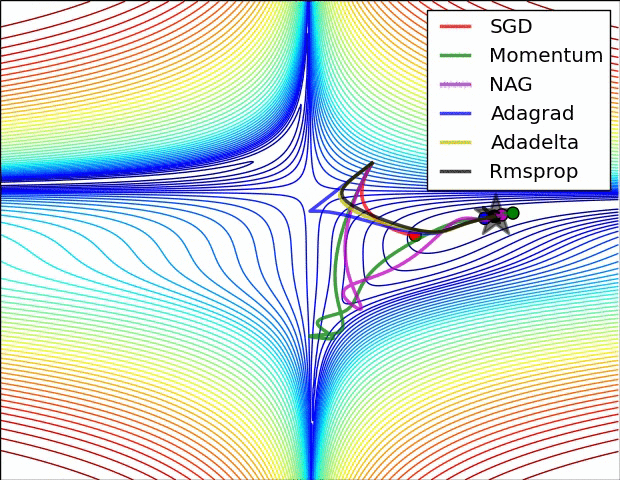
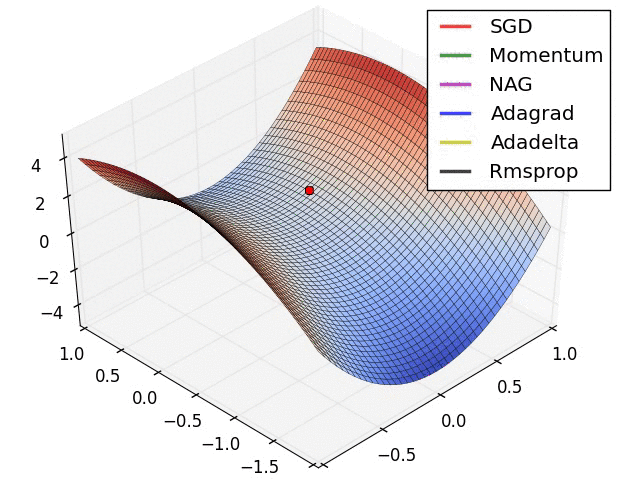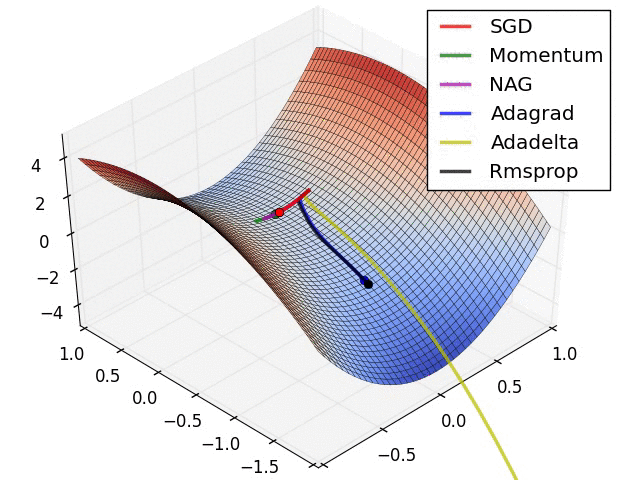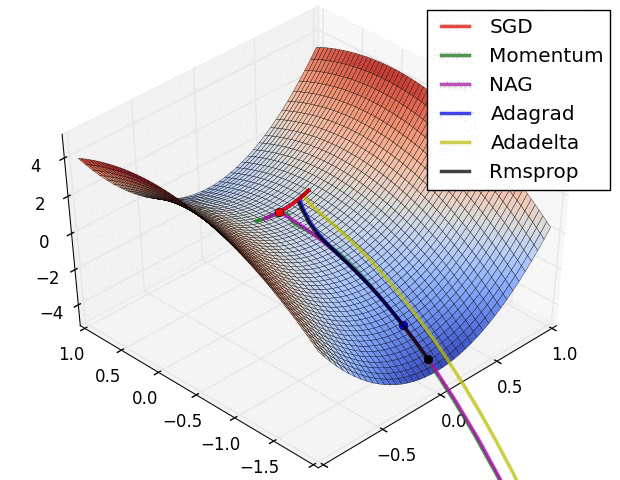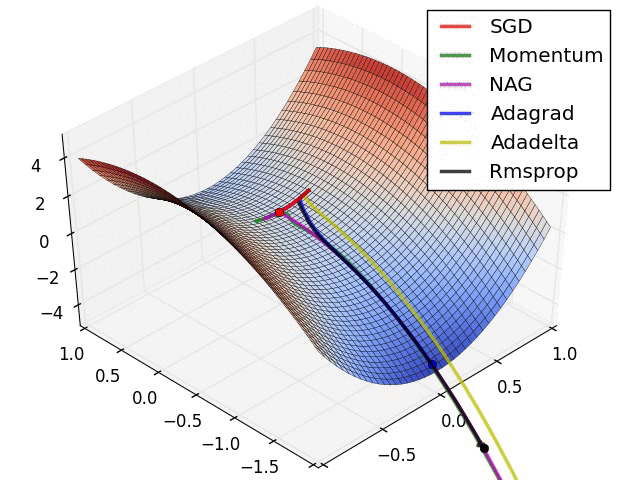
深度學習總結(一)各種優化演算法
一.優化演算法介紹
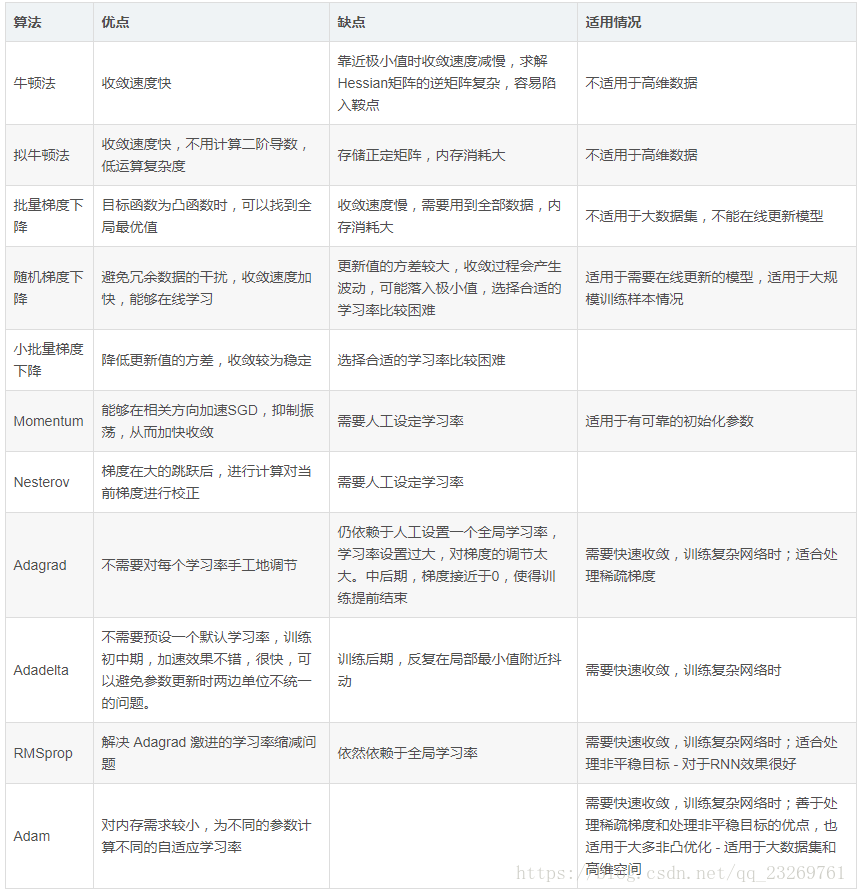
1.批量梯度下降(Batch gradient descent,BGD)
θ=θ−η⋅∇θJ(θ)
每迭代一步,都要用到訓練集的所有資料,每次計算出來的梯度求平均
η代表學習率LR
2.隨機梯度下降(Stochastic Gradient Descent,SGD)
θ=θ−η⋅∇θJ(θ;x(i);y(i))
通過每個樣本來迭代更新一次,以損失很小的一部分精確度和增加一定數量的迭代次數為代價,換取了總體的優化效率的提升。增加的迭代次數遠遠小於樣本的數量。
缺點:
對於引數比較敏感,需要注意引數的初始化
容易陷入區域性極小值
當資料較多時,訓練時間長
每迭代一步,都要用到訓練集所有的資料。
3. 小批量梯度下降(Mini Batch Gradient Descent,MBGD)
θ=θ−η⋅∇θJ(θ;x(i:i+n);y(i:i+n))
為了避免SGD和標準梯度下降中存在的問題,對每個批次中的n個訓練樣本,這種方法只執行一次更新。【每次更新全部梯度的平均值】
4.指數加權平均的概念
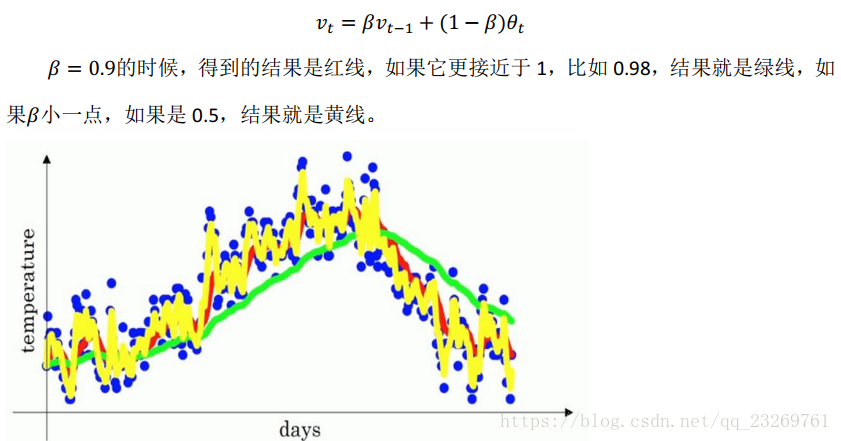

從這裡我們就可已看出指數加權平均的名稱由來,第100個數據其實是前99個數據加權和,而前面每一個數的權重呈現指數衰減,即越靠前的資料對當前結果的影響較小
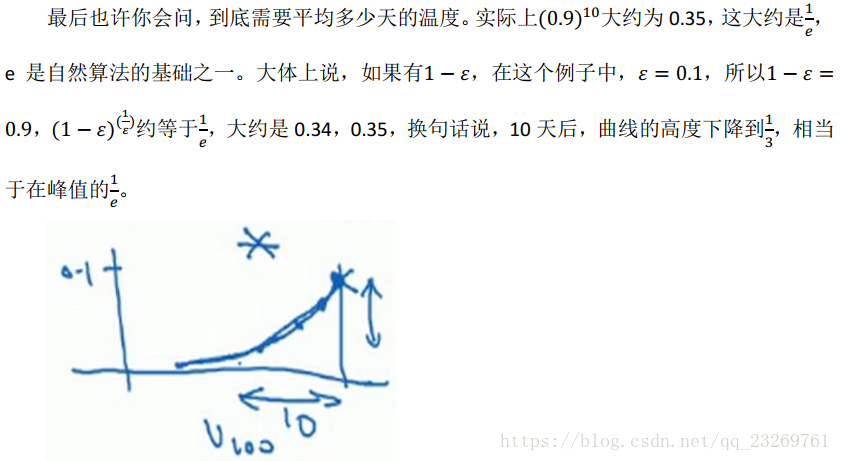
缺點:存在開始資料的過低問題,可以通過偏差修正,但是在深度學習的優化演算法中一般會忽略這個問題
當t不斷增大時,分母逐漸接近1,影響就會逐漸減小了
優點:【相較於滑動視窗平均】
1.佔用記憶體小,每次覆蓋即可
2.運算簡單
5.Momentum(動量梯度下降法)
momentum是模擬物理裡動量的概念,積累之前的動量來替代真正的梯度。公式如下:

然而網上更多的是另外一種版本,即去掉(1-β)
相當於上一版本上本次梯度的影響權值*1/(1-β)
兩者效果相當,只不過會影響一些最優學習率的選取
優點
- 下降初期時,使用上一次引數更新,下降方向一致,乘上較大的μ能夠進行很好的加速
- 下降中後期時,在區域性最小值來回震盪的時候,gradient→0,β得更新幅度增大,跳出陷阱
- 在梯度改變方向的時候,μ能夠減少更新
即在正確梯度方向上加速,並且抑制波動方向張的波動大小,在後期本次計算出來的梯度會很小,以至於無法跳出區域性極值,Momentum方法也可以幫助跳出區域性極值
引數設定
β的常用值為0.9,即可以一定意義上理解為平均了前10/9次的梯度。
至於LR學習率的設定,後面所有方法一起總結吧
6.Nesterov accelerated gradient (NAG)

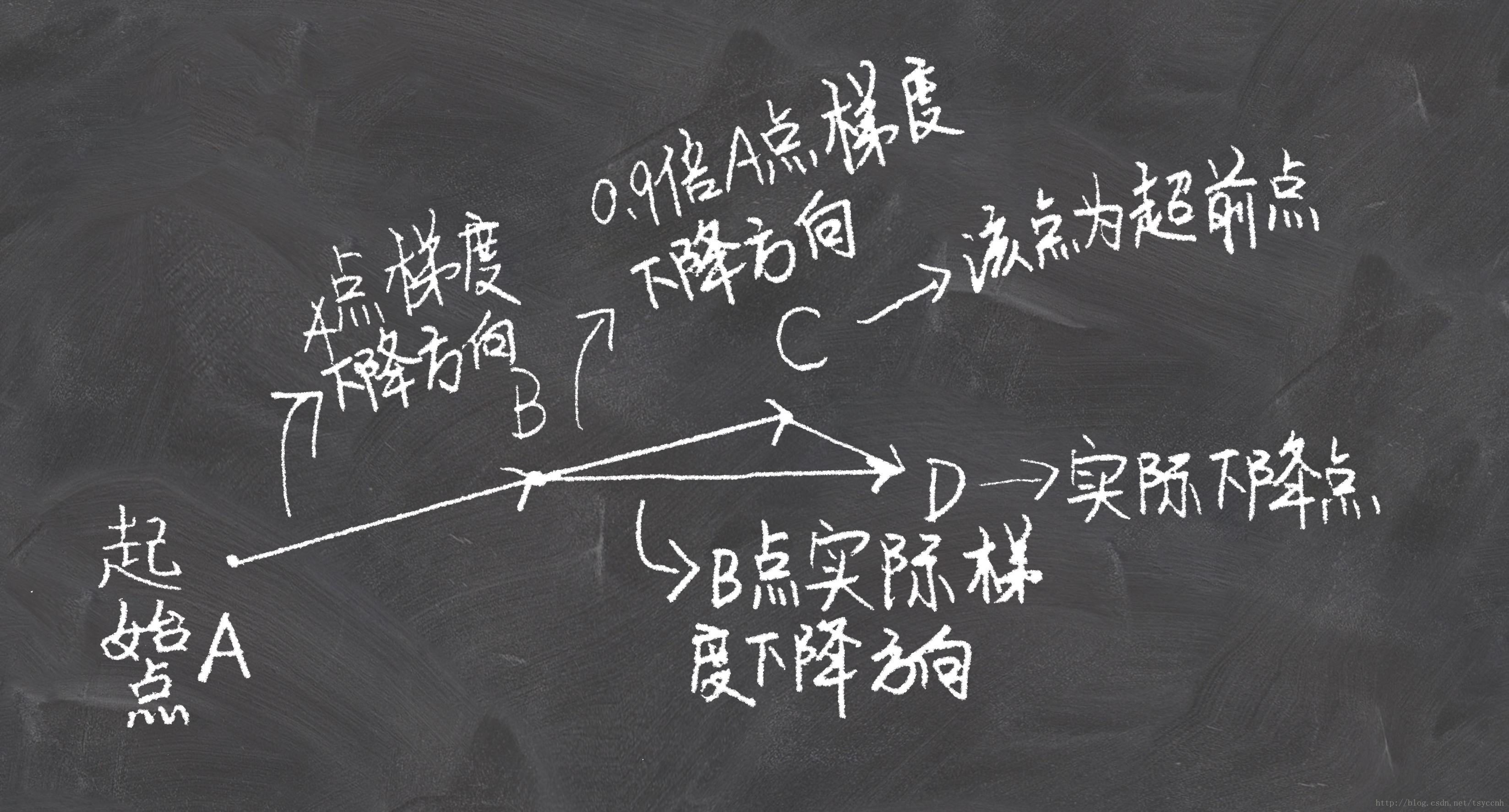

優點:
這種基於預測的更新方法,使我們避免過快地前進,並提高了演算法地響應能力,大大改進了 RNN 在一些任務上的表現【為什麼對RNN好呢,不懂啊】
沒有對比就沒有傷害,NAG方法收斂速度明顯加快。波動也小了很多。實際上NAG方法用到了二階資訊,所以才會有這麼好的結果。先按照原來的梯度走一步的時候已經求了一次梯度,後面再修正的時候又求了一次梯度,所以是二階資訊。
引數設定:
同Momentum
其實,momentum項和nesterov項都是為了使梯度更新更加靈活,對不同情況有針對性。但是,人工設定一些學習率總還是有些生硬,接下來介紹幾種自適應學習率的方法
7.Adagrad
前面的一系列優化演算法有一個共同的特點,就是對於每一個引數都用相同的學習率進行更新。但是在實際應用中各個引數的重要性肯定是不一樣的,所以我們對於不同的引數要動態的採取不同的學習率,讓目標函式更快的收斂。
adagrad方法是將每一個引數的每一次迭代的梯度取平方累加再開方,用基礎學習率除以這個數,來做學習率的動態更新。【這樣每一個引數的學習率就與他們的梯度有關係了,那麼每一個引數的學習率就不一樣了!也就是所謂的自適應學習率】

優點:
- 前期Gt較小的時候, regularizer較大,能夠放大梯度
- 後期Gt較大的時候,regularizer較小,能夠約束梯度
- 適合處理稀疏梯度:相當於為每一維引數設定了不同的學習率:壓制常常變化的引數,突出稀缺的更新。能夠更有效地利用少量有意義樣本
引數設定:
只需要設定初始學習率,後面學習率會自我調整,越來越小
缺點:
Adagrad的一大優勢時可以避免手動調節學習率,比如設定初始的預設學習率為0.01,然後就不管它,另其在學習的過程中自己變化。當然它也有缺點,就是它計算時要在分母上計算梯度平方的和,由於所有的引數平方【上述公式推導中並沒有寫出來是梯度的平方,感覺應該是上文的公式推導忘了寫】必為正數,這樣就造成在訓練的過程中,分母累積的和會越來越大。這樣學習到後來的階段,網路的更新能力會越來越弱,能學到的更多知識的能力也越來越弱,因為學習率會變得極其小【就會提前停止學習】,為了解決這樣的問題又提出了Adadelta演算法。
8.Adadelta
Adagrad會累加之前所有的梯度平方,而Adadelta只累加固定大小的項【其實就是相當於指數滑動平均,只用了前多少步的梯度平方平均值】,並且也不直接儲存這些項,僅僅是近似計算對應的平均值【這也就是指數滑動平均的優點】

優點:
不用依賴於全域性學習率了
訓練初中期,加速效果不錯,很快
避免參數更新時兩邊單位不統一的問題
缺點:
訓練後期,反覆在區域性最小值附近抖動
9.RMSprop

特點:
- 其實RMSprop依然依賴於全域性學習率
- RMSprop算是Adagrad的一種發展,和Adadelta的變體,效果趨於二者之間
- 適合處理非平穩目標(也就是與時間有關的)
- 對於RNN效果很好,因為RMSprop的更新只依賴於上一時刻的更新,所以適合。???
10.Adam
Adam = Adaptive + Momentum,顧名思義Adam集成了SGD的一階動量和RMSProp的二階動量。

特點:
- 結合了Adagrad善於處理稀疏梯度和RMSprop善於處理非平穩目標的優點
- 對記憶體需求較小
- 為不同的引數計算不同的自適應學習率
- 也適用於大多非凸優化
- 適用於大資料集和高維空間
11.Adamax

12.Nadam

13.總結
提速可以歸納為以下幾個方面:
- 使用momentum來保持前進方向(velocity);
- 為每一維引數設定不同的學習率:在梯度連續性強的方向上加速前進;
- 用歷史迭代的平均值歸一化學習率:突出稀有的梯度;
Keras中的預設引數
optimizers.SGD(lr=0.001,momentum=0.9)
optimizers.Adagrad(lr=0.01,epsilon=1e-8)
optimizers.Adadelta(lr=0.01,rho=0.95,epsilon=1e-8)
optimizers.RMSprop(lr=0.001,rho=0.9,epsilon=1e-8)
optimizers.Adam(lr=0.001,beta_1=0.9,beta_2=0.999,epsilon=1e-8)14.牛頓法——二階優化方法【待補充】
二.相關注意問題
1.關於批量梯度下降的batch_size選擇問題
訓練集較小【<2000】:直接使用batch梯度下降,每次用全部的樣本進行梯度更新
訓練集較大:batch_size一般設定為[64,512]之間,設定為2的n次方更符合電腦記憶體設定,程式碼會執行快一些
此外還要考慮GPU和CPU的儲存空間和訓練過程的波動問題
batch_size越小,梯度的波動越大,正則化的效果也越強,自然訓練速度也會變慢,實驗時應該多選擇幾個batch_size進行實驗,以挑選出最優的模型。
2.關於批量梯度下降的weight_decay【似乎與L2正則有關係,待補充】
3.關於優化演算法選擇的經驗之談
- Adam在實際應用中效果良好,超過了其他的自適應技術。
- 如果輸入資料集比較稀疏,SGD、NAG和動量項等方法可能效果不好。因此對於稀疏資料集,應該使用某種自適應學習率的方法,且另一好處為不需要人為調整學習率,使用預設引數就可能獲得最優值。
- 如果想使訓練深層網路模型快速收斂或所構建的神經網路較為複雜,則應該使用Adam或其他自適應學習速率的方法,因為這些方法的實際效果更優。
- SGD通常訓練時間更長,但是在好的初始化和學習率排程方案的情況下,結果更可靠。
- Adadelta,RMSprop,Adam是比較相近的演算法,在相似的情況下表現差不多。在想使用帶動量的RMSprop,或者Adam的地方,大多可以使用Nadam取得更好的效果
4.訓練優化器的目的
加速收斂 2. 防止過擬合 3. 防止區域性最優
5.選用優化器的目的
在構建神經網路模型時,選擇出最佳的優化器,以便快速收斂並正確學習,同時調整內部引數,最大程度地最小化損失函式。
6.為什麼神經網路的訓練不採用二階優化方法 (如Newton, Quasi Newton)?

7. 優化SGD的其他手段