
時間序列 R 讀書筆記 Forecasting: principles and practice 06 迴歸概述
1 簡單迴歸
1.1 線性迴歸殘差性質
線性迴歸想必大家都比較熟悉了, 其迴歸方程是
殘差是:
殘差有以下性質:
其殘差為白噪聲且與自變數沒有關係
1.2 迴歸與相關性
迴歸與相關性有較大的關係,設相關係數為
可以看出線性迴歸將相關性聯絡起來
1.3 迴歸模型的評估
1.3.1 殘差圖繪製
繪製殘差圖能夠清晰地看到那一段擬合的比較好,也能夠看到異常點
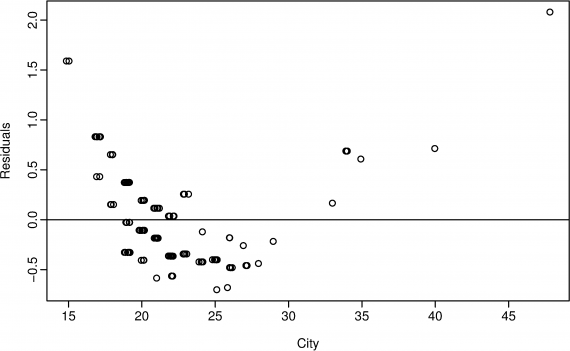
上圖中可以看出 在開始小於20 大於35的地方擬合的不好
1.3.2 異常值觀測
異常的檢測方法很多,有監督,半監督,無監督等方法,有機會可以好好看下,本書中沒有詳細介紹。
1.3.3 擬合情況評價
評價線性擬合的擬合情況可以用決定係數
其中觀測值是y,帶帽子的y是預測值
它的值越接近1越好,在0-1之間,。
但是:
並不是總是越大越好,如上面的圖,在某一段會有擬合不充分的地方
簡單的線性迴歸中
判定係數只是說明列入模型的所有解釋變數對因變數的聯合的影響程度,不說明模型中單個解釋變數的影響程度。
對時間序列資料,判定係數達到0.9以上是很平常的;但是,對截面資料而言,能夠有0.5就不錯了
還有一種方法叫做殘差標準差,也叫Standard error of the regression迴歸標準差
主要到,這裡除了n-2,而不是n-1,這是因為我們擬合了兩個引數(斜率和截距)
1.4 預測
注意預測不單單是一個值,應該是一個區間,即數值+置信區間的波動範圍
1.5 統計推斷
可以使用假設檢驗來識別判斷擬合的引數的正確性。
這裡使用P值來表明在原假設成立時,發生的概率
統計學根據顯著性檢驗方法所得到的P 值,一般以P < 0.05 為顯著, P <0.01 為非常顯著,其含義是樣本間的差異由抽樣誤差所致的概率小於0.05 或0.01。實際上,P 值不能賦予資料任何重要性,只能說明某事件發生的機率。
若X 服從正態分佈和t 分佈,其分佈曲線是關於縱軸對稱的,故其P 值可表示為P = P{| X| > C} 。
計算出P 值後,將給定的顯著性水平α與P 值比較,就可作出檢驗的結論:如果α > P 值,則在顯著性水平α下拒絕原假設。如果α ≤ P 值,則在顯著性水平α下接受原假設。在實踐中,當α = P 值時,也即統計量的值C 剛好等於臨界值,為慎重起見,可增加樣本容量,重新進行抽樣檢驗。
具體推導公式本書未包含。可以查詢其他資料學習。
1.6 非線性擬合
線性擬合不好的情況可以用非線性擬合,適當的將變數進行數值變化之後可以用線性變化的理論來擬合非線性的問題,如選用log-log模型
1.7 時間序列迴歸
時間序列可以用前面講到的判斷法,但是往往效果不好,這裡介紹了簡單的時間序列的迴歸
它以時間t為自變數,當然迴歸之後還需要計算殘差和ACF,如果ACF顯示不是白噪聲,說明有內在的聯絡為挖掘,它的預測精度可能不夠。
偽迴歸
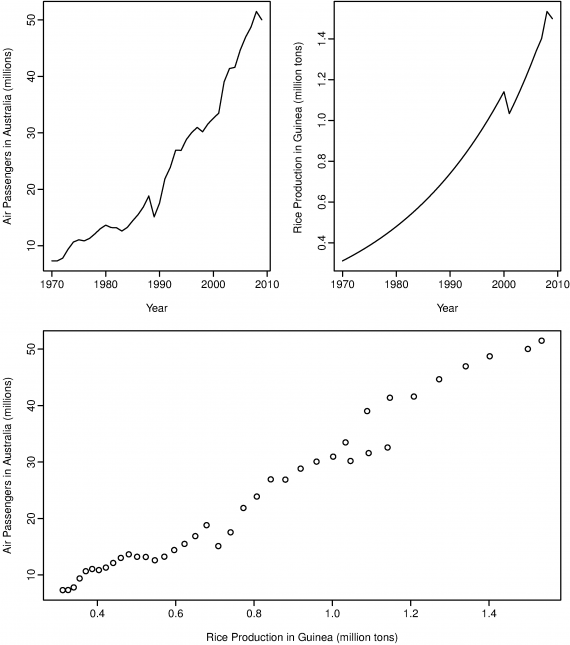
如圖,幾內亞的大米產量和澳大利亞的乘客數量看起來有相同的趨勢,但實際上是沒有關係的。如果直接用這樣的資料來判斷他們的關係久可能會造成偽迴歸。這常常是因為時間序列不穩定造成的。
2 多元迴歸
2.1 多元線性迴歸簡介
他的一般公式如下:
相關推薦
時間序列 R 讀書筆記 Forecasting: principles and practice 06 迴歸概述
1 簡單迴歸 1.1 線性迴歸殘差性質 線性迴歸想必大家都比較熟悉了, 其迴歸方程是y^i=β^0+β^1xi 殘差是:ei=yi−y^i=yi−β^0−β^1xi. 殘差有以下性質: ∑i=1Nei=0and∑i=1Nxiei=0. 其殘差為白噪聲
暗時間的一些讀書筆記
簡潔 重要 關於 效率 相關 決定性 歷史 競爭 註釋 ###### 軟件相關但不僅限於軟件領域 -如果你有一把錘子,所有東西看上去都像釘子。 -商業軟件要折中 , 教學與科學 則需要精益求精。 -寫註釋的原則 : 要小心的地方,難以理解的地方 -保證進度,代碼接口簡潔。
時間序列方面的筆記
#下面這一段用一個txt來儲存input的資訊來模擬input.最後提交程式碼時候刪除這一段即可. def input(): a9999=open('1.txt','r')#把這行寫函式裡面,可以防止變數汙染. return a9999.readline().rstri
《python資料分析和資料探勘》——時間序列分析學習筆記
時間序列分析 給定一個已被觀測了的時間序列,預測該序列的的未來值。 重點介紹AR模型、MA模型、ARMA模型和ARIMA模型 1、時間序列的預處理 拿到一個觀察值序列後,首先要對它的純隨機性和平穩性進行檢驗,稱之為預處理。在此區別純隨機序列、平穩非白噪聲序列、非平穩序列。 純隨機序
【Python】《Python編程之美 最佳時間指南》讀書筆記
命名 format 寫上 擴展 字典 ctr 數組 people {0} 草草的看了一遍,有些設計代碼講解地方因為我的層次不及,尚不能理解。 基本 留白勝於緊湊 |> 一行只寫一條語句 明確勝於隱晦 |> 判斷代碼寫的是否優雅的一個規則是:其他開發者是否只閱
R讀書筆記之特徵工程(一)空值處理
在特徵處理中,會有空值的刪除或者填充。 一:刪除 1一般刪除是最簡單的,用na.omit(data)就搞定,但是太粗暴了。 2若是有的觀測量空缺值太多的話,確實需要刪除,因為用別的方法填充反而會導致模型偏差。 那麼腫麼統計觀測量的空值的個數捏?可以參
時間序列 R 09 ARIMA
1.1 穩定性與差分 1.1.1 穩定性 stationarity 穩定性是指時間序列的屬性不在隨時間變化。因此有趨勢和季節性的時間序列不是穩定的序列。但是有一些具有周期性cyclic的時間序列因為其週期時間不一定,所以也是穩定性序列。 1.1.2
Operating Systems Principles and Practice 2nd 2Ch Exercises
ted esp att verify integer gist stat double con Preface: Most of the answers below are written by myself --- only instructors are given
Computer Graphics Principles And Practice
1 Introduction 2 Introduction to 2D Graphics Using WPF 3 An Ancient Renderer Made Modern 4 A 2D Graphics Test Bed 5 An Introduction to Human Visual Per
時間序列分析及應用 R語言 讀書筆記 02
第二章 基本概念 Yt代表時間序列t時刻的值 自協方差函式γt,s γt,s=cov(Yt,Ys)=E[(Yt−μt)(Ys−μs)]=E(YtYs)−μtμs 自相關函式 ρt,s=corr(YtYs)=cov(YtYs)Var(Yt)Var(Ys)
時間序列分析及應用 R語言 讀書筆記 03
第三章 趨勢 Trends 3.1 隨機趨勢與確定性趨勢 上節中的隨機漫步序列(random walk)雖然呈現出來整體線性增長的趨勢,但是這是因為每個e的隨機取值造成的,如果重新生成一遍,其趨勢不一定還是這樣,所以,這樣的不確定的趨勢稱為隨機趨勢。 有些
R語言學習筆記(十三):時間序列
abs 以及 stat max 時間 aic air ror imp #生成時間序列對象 sales<-c(18,33,41,7,34,35,24,25,24,21,25,20,22,31,40,29,25,21,22,54,31,25,26,35) tsal
R語言學習筆記:時間序列分析
1.生成時間序列 ts() ts(data = NA, start = 1, end = numeric(), frequency = 1, deltat = 1, ts.eps = getOption("ts.eps"), class =, names = )data是數
R語言與時間序列學習筆記(1)
今天分享的是R語言中時間序列的有關內容。主要有:時間序列的建立,ARMA模型的建立與自相關和偏自相關函式。 一、 時間序列的建立 時間序列的建立函式為:ts().函式的引數列表如下: ts(data = NA, start = 1, end
有關時間序列的完整教程——R and Python
首先先放上用R的實現的時間序列的完整教程(需要用谷歌瀏覽器開啟翻譯著看,很全^_^):https://www.analyticsvidhya.com/blog/2015/12/complete-tutorial-time-series-modeling/ 然後是python
R語言與時間序列學習筆記(2)
ARMA模型的引數估計方法 ARMA引數估計和前面我們介紹的點估計內容相似,也介紹矩估計與最小二乘估計兩種方法。 和上一次的點估計一樣,這一次我分享的內容主要有:矩估計,最小二乘估計,一個應用例題 關
《時間序列分析及應用.R語言》第十一章閱讀筆記
arima reg poi 11.2 樣本 誤差 == 兩種 class 第11章 11.1幹預分析 library(TSA) win.graph(width = 4.875,height = 2.5,pointsize = 8) data(airm
《R實戰》讀書筆記二
.wang col ott director pan tle outfile sink cto 第一章 R簡單介紹 本章概要 1安裝R 2理解R語言 3執行R程序 本章所介紹的內容概括例如以下。 一個典型的數據分析步驟如圖1所
R語言--時間序列分析步驟
align 如何 -- list arima test bsp nat 建立 大白。 (1)根據趨勢定差分 plot(lostjob,type="b") 查看圖像總體趨勢,確定如何差分 df1 = diff(lostjob) d=1階差分 s4_df1=diff(df1,
時間序列2擬合檢驗和預測#R
logs clas 診斷 mean 噪聲 移動平均 clu 常數 設定 一、擬合 1、自動擬合模型 要使用auto.arima( )函數需要先下載zoo和forecast程序包,並用library調用這兩個程序包。auto.arima()函數的命令格式如下 auto.ar