
solr5.3.1 整合IK中文分詞器
阿新 • • 發佈:2019-01-06
參考文章:http://www.cnblogs.com/sword-successful/p/5604541.html
轉載文章:http://www.cnblogs.com/pazsolr/p/5796813.html
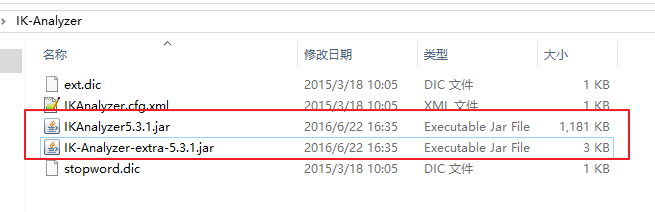
1.下載IK分詞器包。
連結:http://pan.baidu.com/s/1i4D0fZJ 密碼:bcen
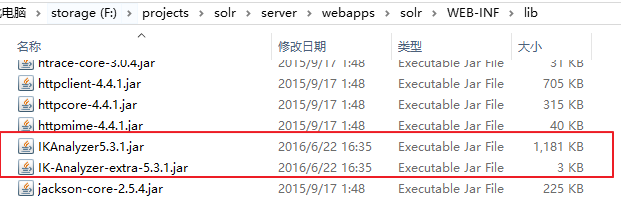
2.解壓並把IKAnalyzer5.3.1.jar 、IK-Analyzer-extra-5.3.1.jar拷貝到tomcat/webapps/solr/WEB-INF/lib下。
3.修改schema.xml配置檔案,如下:
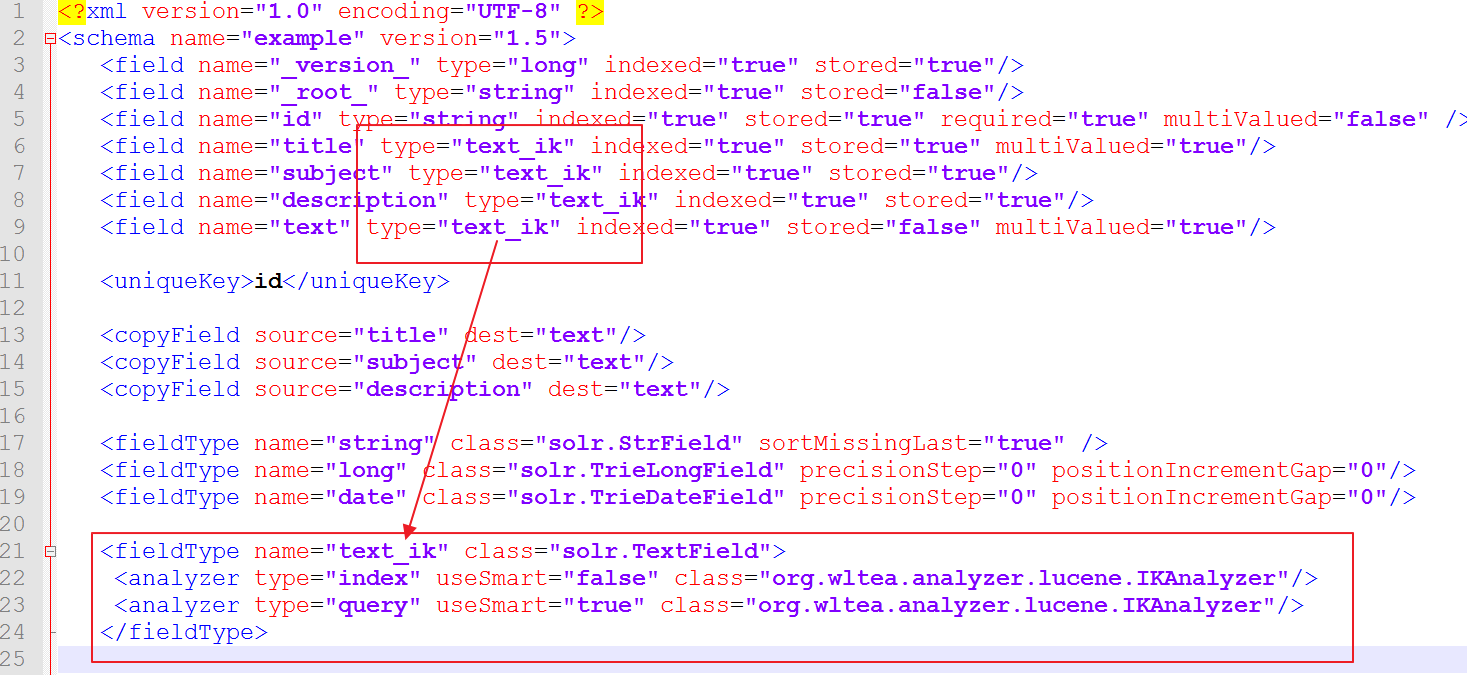
修改後的配置檔案
<?xml version="1.0" encoding="UTF-8" ?> <schema name="example" version="1.5"> <field name="_version_" type="long" indexed="true" stored="true"/> <field name="_root_" type="string" indexed="true" stored="false"/> <field name="id" type="string" indexed="true" stored="true" required="true" multiValued="false" /> <field name="title" type="text_ik" indexed="true" stored="true" multiValued="true"/> <field name="subject" type="text_ik" indexed="true" stored="true"/> <field name="description" type="text_ik" indexed="true" stored="true"/> <field name="text" type="text_ik" indexed="true" stored="false" multiValued="true"/> <uniqueKey>id</uniqueKey> <copyField source="title" dest="text"/> <copyField source="subject" dest="text"/> <copyField source="description" dest="text"/> <fieldType name="string" class="solr.StrField" sortMissingLast="true" /> <fieldType name="long" class="solr.TrieLongField" precisionStep="0" positionIncrementGap="0"/> <fieldType name="date" class="solr.TrieDateField" precisionStep="0" positionIncrementGap="0"/> <fieldType name="text_ik" class="solr.TextField"> <analyzer type="index" useSmart="false" class="org.wltea.analyzer.lucene.IKAnalyzer"/> <analyzer type="query" useSmart="true" class="org.wltea.analyzer.lucene.IKAnalyzer"/> </fieldType> <fieldType name="text_general" class="solr.TextField" positionIncrementGap="100"> <analyzer type="index"> <tokenizer class="solr.StandardTokenizerFactory"/> <filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" /> <filter class="solr.LowerCaseFilterFactory"/> </analyzer> <analyzer type="query"> <tokenizer class="solr.StandardTokenizerFactory"/> <filter class="solr.StopFilterFactory" ignoreCase="true" words="stopwords.txt" /> <filter class="solr.SynonymFilterFactory" synonyms="synonyms.txt" ignoreCase="true" expand="true"/> <filter class="solr.LowerCaseFilterFactory"/> </analyzer> </fieldType> </schema>
修改完成之後儲存並重啟solr伺服器。