
蝸龍徒行-Spark學習筆記【四】Spark叢集中使用spark-submit提交jar任務包實戰經驗
阿新 • • 發佈:2019-01-06
一、所遇問題
由於在IDEA下可以方便快捷地執行scala程式,所以先前並沒有在終端下使用spark-submit提交打包好的jar任務包的習慣,但是其只能在local模式下執行,在網上搜了好多帖子設定VM引數都不能啟動spark叢集,由於實驗任務緊急只能暫時作罷IDEA下任務提交,繼而改由終端下使用spark-submit提交打包好的jar任務。
二、spark-shell功能介紹
進入$SPARK_HOME目錄,輸入bin/spark-submit --help可以得到該命令的使用幫助。
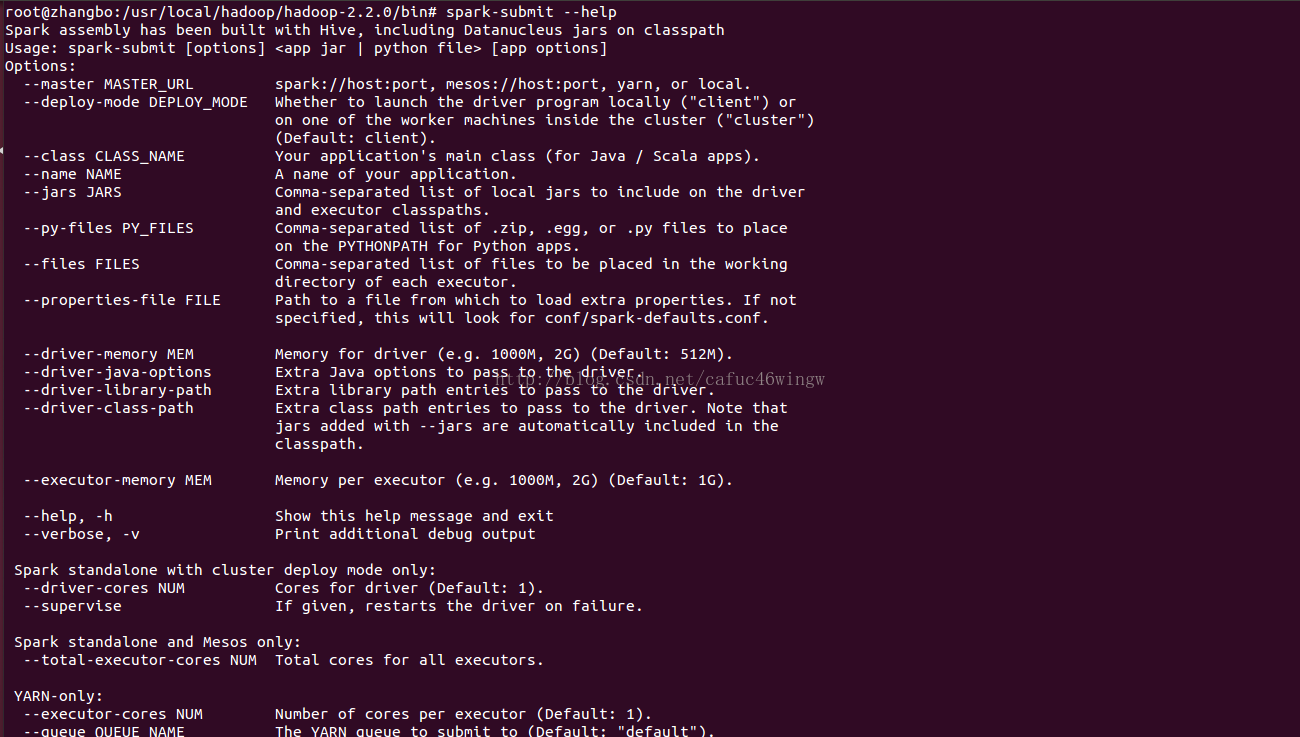

--master MASTER_URL spark://host:port, mesos://host:port, yarn, or local.
--deploy-mode DEPLOY_MODE driver執行之處,client執行在本機,cluster執行在叢集
--class CLASS_NAME 應用程式包的要執行的class
--name NAME 應用程式名稱
--jars JARS 用逗號隔開的driver本地jar包列表以及executor類路徑
--py-files PY_FILES 用逗號隔開的放置在Python應用程式PYTHONPATH上的.zip, .egg, .py檔案列表
--files FILES 用逗號隔開的要放置在每個executor工作目錄的檔案列表
--properties-file FILE 設定應用程式屬性的檔案放置位置,預設是conf/spark-defaults.conf
--driver-memory MEM driver記憶體大小,預設512M
--driver-java-options driver的java選項
--driver-library-path driver的庫路徑Extra library path entries to pass to the driver
--driver-class-path driver的類路徑,用--jars 新增的jar包會自動包含在類路徑裡
--executor-memory MEM executor記憶體大小,預設1G
Spark standalone with cluster deploy mode only:
--driver-cores NUM driver使用核心數,預設為1
--supervise 如果設定了該引數,driver失敗是會重啟
Spark standalone and Mesos only:
--total-executor-cores NUM executor使用的總核數
YARN-only:
--executor-cores NUM 每個executor使用的核心數,預設為1
--queue QUEUE_NAME 提交應用程式給哪個YARN的佇列,預設是default佇列
--num-executors NUM 啟動的executor數量,預設是2個
--archives ARCHIVES 被每個executor提取到工作目錄的檔案列表,用逗號隔開
- 關於--master --deploy-mode,正常情況下,可以不需要配置--deploy-mode,使用下面的值配置--master就可以了,使用類似 --master spark://host:port --deploy-mode cluster會將driver提交給cluster,然後就將worker給kill的現象。
| Master URL | 含義 |
| local | 使用1個worker執行緒在本地執行Spark應用程式 |
| local[K] | 使用K個worker執行緒在本地執行Spark應用程式 |
| local[*] |
使用所有剩餘worker執行緒在本地執行Spark應用程式 |
| spark://HOST:PORT | 連線到Spark Standalone叢集,以便在該叢集上執行Spark應用程式 |
| mesos://HOST:PORT | 連線到Mesos叢集,以便在該叢集上執行Spark應用程式 |
| yarn-client | 以client方式連線到YARN叢集,叢集的定位由環境變數HADOOP_CONF_DIR定義,該方式driver在client執行。 |
| yarn-cluster | 以cluster方式連線到YARN叢集,叢集的定位由環境變數HADOOP_CONF_DIR定義,該方式driver也在叢集中執行。 |
- 如果要使用--properties-file的話,在--properties-file中定義的屬性就不必要在spark-sumbit中再定義了,比如在conf/spark-defaults.conf 定義了spark.master,就可以不使用--master了。關於Spark屬性的優先權為:SparkConf方式 > 命令列引數方式 >檔案配置方式,具體參見Spark1.0.0屬性配置。
- 和之前的版本不同,Spark1.0.0會將自身的jar包和--jars選項中的jar包自動傳給叢集。
- Spark使用下面幾種URI來處理檔案的傳播:
- file:// 使用file://和絕對路徑,是由driver的HTTP server來提供檔案服務,各個executor從driver上拉回檔案。
- hdfs:, http:, https:, ftp: executor直接從URL拉回檔案
- local: executor本地本身存在的檔案,不需要拉回;也可以是通過NFS網路共享的檔案。
- 如果需要檢視配置選項是從哪裡來的,可以用開啟--verbose選項來生成更詳細的執行資訊以做參考。
三、如何將scala程式在IDEA中打包為JAR可執行包
A:建立新專案(new project)
- 建立名為KMeansTest的project:啟動IDEA -> Welcome to IntelliJ IDEA -> Create New Project -> Scala -> Non-SBT -> 建立一個名為KMeansTest的project(注意這裡選擇自己安裝的JDK和scala編譯器) -> Finish。
- 設定KMeansTest的project structure
- 增加原始碼目錄:File -> Project Structure -> Medules -> KMeansTest,給KMeansTest建立原始碼目錄和資源目錄,注意用上面的按鈕標註新增加的目錄的用途。
- 增加原始碼目錄:File -> Project Structure -> Medules -> KMeansTest,給KMeansTest建立原始碼目錄和資源目錄,注意用上面的按鈕標註新增加的目錄的用途。
- 增加開發包:File -> Project Structure -> Libraries -> + -> java -> 選擇
- /usr/local/spark/spark-1.0.2-bin-hadoop2/lib/spark-assembly-1.0.2-hadoop2.2.0.jar
- /root/.sbt/boot/scala-2.10.4/lib/scala-library.jar可能會提示錯誤,可以根據fix提示進行處
B:編寫程式碼
在原始碼scala目錄下建立1個名為KMeansTest的package,並增加3個object(SparkPi、WordCoun、SparkKMeans):
//SparkPi程式碼
package <span style="font-size:14px;"><span style="font-size:14px;"><span style="font-size:14px;">KMeansTest</span></span></span>
import scala.math.random
import org.apache.spark._
/** Computes an approximation to pi */
object SparkPi {
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("Spark Pi")
val spark = new SparkContext(conf)
val slices = if (args.length > 0) args(0).toInt else 2
val n = 100000 * slices
val count = spark.parallelize(1 to n, slices).map { i =>
val x = random * 2 - 1
val y = random * 2 - 1
if (x*x + y*y < 1) 1 else 0
}.reduce(_ + _)
println("Pi is roughly " + 4.0 * count / n)
spark.stop()
}
} // WordCount1程式碼
package <span style="font-size:14px;"><span style="font-size:14px;"><span style="font-size:14px;">KMeansTest</span></span></span>
import org.apache.spark.{SparkContext, SparkConf}
import org.apache.spark.SparkContext._
object WordCount1 {
def main(args: Array[String]) {
if (args.length == 0) {
System.err.println("Usage: WordCount1 <file1>")
System.exit(1)
}
val conf = new SparkConf().setAppName("WordCount1")
val sc = new SparkContext(conf)
sc.textFile(args(0)).flatMap(_.split(" ")).map(x => (x, 1)).reduceByKey(_ + _).take(10).foreach(println)
sc.stop()
}
} //SparkKMeans程式碼
package KMeansTest
import java.util.Random
import breeze.linalg.{Vector, DenseVector, squaredDistance}
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.SparkContext._
object SparkKMeans {
val R = 1000 // Scaling factor
val rand = new Random(42)
def parseVector(line: String): Vector[Double] = {
DenseVector(line.split(' ').map(_.toDouble))
}
def closestPoint(p: Vector[Double], centers: Array[Vector[Double]]): Int = {
var index = 0
var bestIndex = 0
var closest = Double.PositiveInfinity
for (i <- 0 until centers.length) {
val tempDist = squaredDistance(p, centers(i))
if (tempDist < closest) {
closest = tempDist
bestIndex = i
}
}
bestIndex
}
def main(args: Array[String]) {
if (args.length < 3) {
System.err.println("Usage: SparkKMeans <file> <k> <convergeDist>")
System.exit(1)
}
val sparkConf = new SparkConf().setAppName("SparkKMeans").setMaster(args(0))
val sc = new SparkContext(sparkConf)
val lines = sc.textFile(args(1))
val data = lines.map(parseVector _).cache()
val K = args(2).toInt
val convergeDist = args(3).toDouble
val kPoints = data.takeSample(withReplacement = false, K, 42).toArray
var tempDist = 1.0
while(tempDist > convergeDist) {
val closest = data.map (p => (closestPoint(p, kPoints), (p, 1)))
val pointStats = closest.reduceByKey{case ((x1, y1), (x2, y2)) => (x1 + x2, y1 + y2)}
val newPoints = pointStats.map {pair =>
(pair._1, pair._2._1 * (1.0 / pair._2._2))}.collectAsMap()
tempDist = 0.0
for (i <- 0 until K) {
tempDist += squaredDistance(kPoints(i), newPoints(i))
}
for (newP <- newPoints) {
kPoints(newP._1) = newP._2
}
println("Finished iteration (delta = " + tempDist + ")")
}
println("Final centers:")
kPoints.foreach(println)
sc.stop()
}
}C:生成jar程式包
生成jar程式包之前要先建立一個artifacts,File -> Project Structure -> Artifacts -> + -> Jars -> From moudles with dependencies,然後隨便選一個class作為主class。
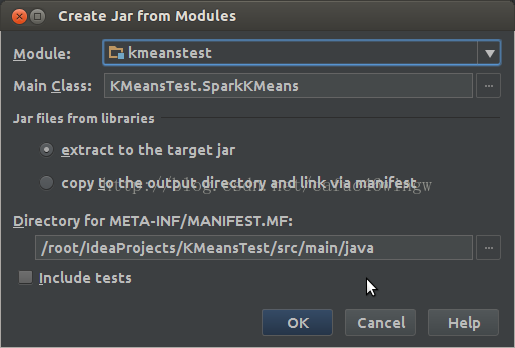
按OK後, Build -> Build Artifacts -> KMeansTest -> rebuild進行打包,經過編譯後,程式包放置在out/artifacts/KMeansTest目錄下,檔名為KMeansTest.jar。
D:Spark應用程式部署
將生成的程式包KMeansTest.jar複製到spark安裝目錄下,切換到使用者hadoop/bin目錄下進行程式的部署。
四、spark-shell下進行jar程式包提交執行實驗
下面給出了幾種實驗CASE的命令:


在使用spark-submit提交spark應用程式的時候,需要注意以下幾點:
- 叢集外的客戶機向Spark Standalone部署Spark應用程式時,要注意事先實現該客戶機和Spark Standalone之間的SSH無密碼登入。
- 向YARN部署spark應用程式的時候,注意executor-memory的大小,其記憶體加上container要使用的記憶體(預設值是1G)不要超過NM可用記憶體,不然分配不到container來執行executor。